 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining-Free Imitation Learning with Closed-Form Diffusion Policies
May 31, 2026While diffusion-based policies have impressive performance and expressivity, their long offline training slows down the data collection and policy deployment loop. We introduce Closed-Form Diffusion Policies, a class of training-free diffusion-based policies for imitation learning using the closed-form score derived from the demonstration dataset. We deploy CFDP with real-time inference with a mobile CPU in hardware experiments, showing it can successfully perform imitation directly from the dataset in milliseconds and with faster inference than neural diffusion policies. In experiments on imitation learning benchmarks, we show that CFDP is competitive against neural baselines that require hours of training, providing a favorable tradeoff between training time and performance. Finally, we show how closed-form diffusion policies act as a composable primitive that enables data-driven inference-time editing of pre-trained neural diffusion policies, including policy guidance and novel demonstration augmentation.
DynoJEPP: Joint Estimation, Prediction and Planning in Dynamic Environments
May 13, 2026DynoJEPP is a factor-graph-based framework that jointly formulates and simultaneously optimizes estimation, prediction, and planning in dynamic environments. In conventional factor-graph-based approaches that jointly formulate estimation, prediction, and planning, information from prediction and planning feeds back into state estimation, yielding corrupted estimates, undesired behaviors, and unsafe plans. To address this, DynoJEPP introduces a novel directed factor that enforces directional information flow within the factor graph, preventing prediction and planning from corrupting state estimation. We evaluate the impact of directed factors on inter-module interactions during navigation in both static and dynamic environments. Our results demonstrate that these factors are critical for safe operation, as without them, the robot collides in the majority of experiments. Building on this, we further introduce Cooperative DynoJEPP, which enables the ego robot to incorporate cooperative object behavior into its prediction and trajectory planning.
Goal-Conditioned Neural ODEs with Guaranteed Safety and Stability for Learning-Based All-Pairs Motion Planning
Apr 03, 2026This paper presents a learning-based approach for all-pairs motion planning, where the initial and goal states are allowed to be arbitrary points in a safe set. We construct smooth goal-conditioned neural ordinary differential equations (neural ODEs) via bi-Lipschitz diffeomorphisms. Theoretical results show that the proposed model can provide guarantees of global exponential stability and safety (safe set forward invariance) regardless of goal location. Moreover, explicit bounds on convergence rate, tracking error, and vector field magnitude are established. Our approach admits a tractable learning implementation using bi-Lipschitz neural networks and can incorporate demonstration data. We illustrate the effectiveness of the proposed method on a 2D corridor navigation task.
EB-MBD: Emerging-Barrier Model-Based Diffusion for Safe Trajectory Optimization in Highly Constrained Environments
Oct 09, 2025We propose enforcing constraints on Model-Based Diffusion by introducing emerging barrier functions inspired by interior point methods. We show that constraints on Model-Based Diffusion can lead to catastrophic performance degradation, even on simple 2D systems due to sample inefficiency in the Monte Carlo approximation of the score function. We introduce Emerging-Barrier Model-Based Diffusion (EB-MBD) which uses progressively introduced barrier constraints to avoid these problems, significantly improving solution quality, without the need for computationally expensive operations such as projections. We analyze the sampling liveliness of samples each iteration to inform barrier parameter scheduling choice. We demonstrate results for 2D collision avoidance and a 3D underwater manipulator system and show that our method achieves lower cost solutions than Model-Based Diffusion, and requires orders of magnitude less computation time than projection based methods.
Learning to optimize with guarantees: a complete characterization of linearly convergent algorithms
Aug 01, 2025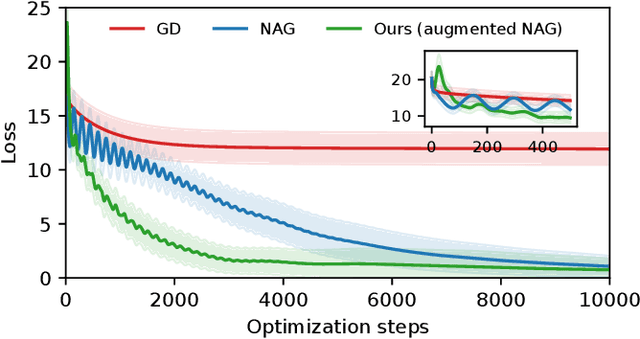
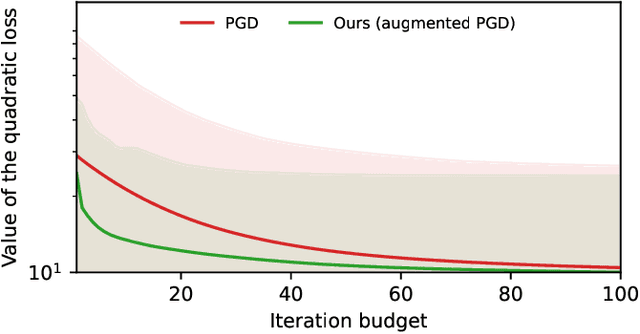
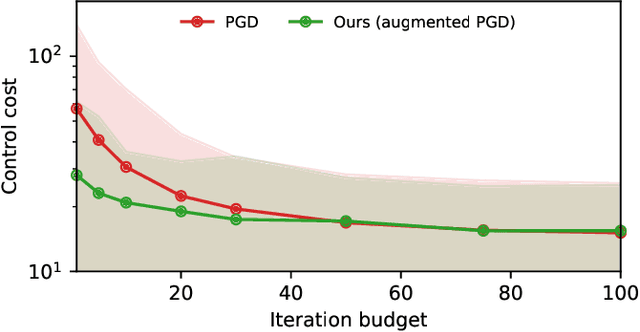
In high-stakes engineering applications, optimization algorithms must come with provable worst-case guarantees over a mathematically defined class of problems. Designing for the worst case, however, inevitably sacrifices performance on the specific problem instances that often occur in practice. We address the problem of augmenting a given linearly convergent algorithm to improve its average-case performance on a restricted set of target problems - for example, tailoring an off-the-shelf solver for model predictive control (MPC) for an application to a specific dynamical system - while preserving its worst-case guarantees across the entire problem class. Toward this goal, we characterize the class of algorithms that achieve linear convergence for classes of nonsmooth composite optimization problems. In particular, starting from a baseline linearly convergent algorithm, we derive all - and only - the modifications to its update rule that maintain its convergence properties. Our results apply to augmenting legacy algorithms such as gradient descent for nonconvex, gradient-dominated functions; Nesterov's accelerated method for strongly convex functions; and projected methods for optimization over polyhedral feasibility sets. We showcase effectiveness of the approach on solving optimization problems with tight iteration budgets in application to ill-conditioned systems of linear equations and MPC for linear systems.
Robustly Invertible Nonlinear Dynamics and the BiLipREN: Contracting Neural Models with Contracting Inverses
May 05, 2025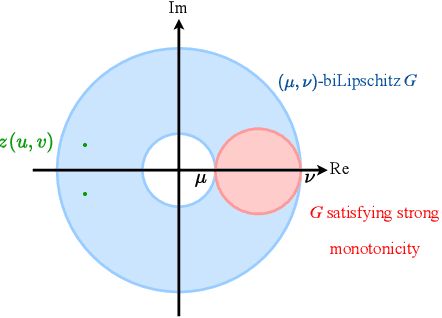
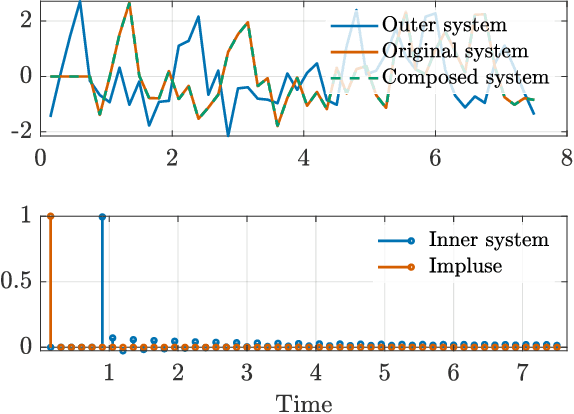
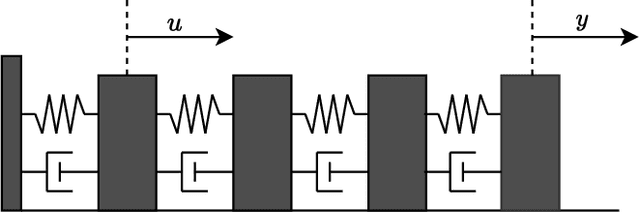
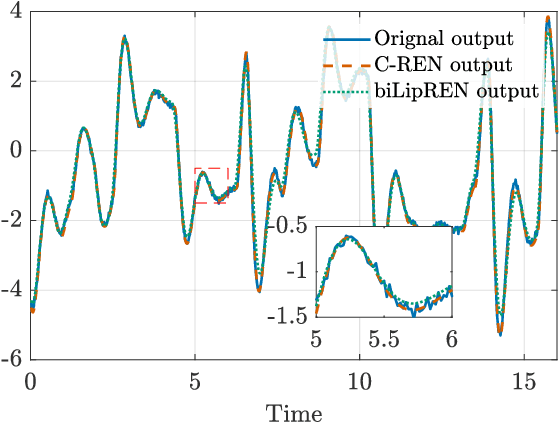
We study the invertibility of nonlinear dynamical systems from the perspective of contraction and incremental stability analysis and propose a new invertible recurrent neural model: the BiLipREN. In particular, we consider a nonlinear state space model to be robustly invertible if an inverse exists with a state space realisation, and both the forward model and its inverse are contracting, i.e. incrementally exponentially stable, and Lipschitz, i.e. have bounded incremental gain. This property of bi-Lipschitzness implies both robustness in the sense of sensitivity to input perturbations, as well as robust distinguishability of different inputs from their corresponding outputs, i.e. the inverse model robustly reconstructs the input sequence despite small perturbations to the initial conditions and measured output. Building on this foundation, we propose a parameterization of neural dynamic models: bi-Lipschitz recurrent equilibrium networks (biLipREN), which are robustly invertible by construction. Moreover, biLipRENs can be composed with orthogonal linear systems to construct more general bi-Lipschitz dynamic models, e.g., a nonlinear analogue of minimum-phase/all-pass (inner/outer) factorization. We illustrate the utility of our proposed approach with numerical examples.
Negative Imaginary Neural ODEs: Learning to Control Mechanical Systems with Stability Guarantees
Apr 28, 2025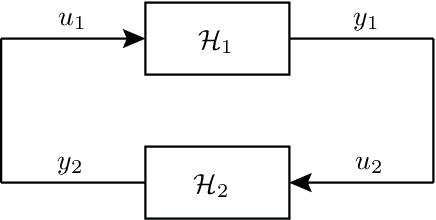
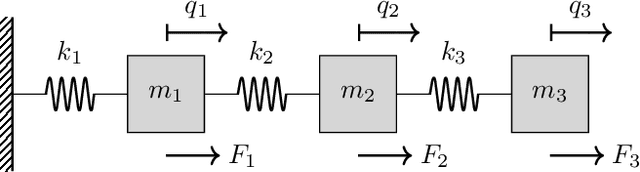
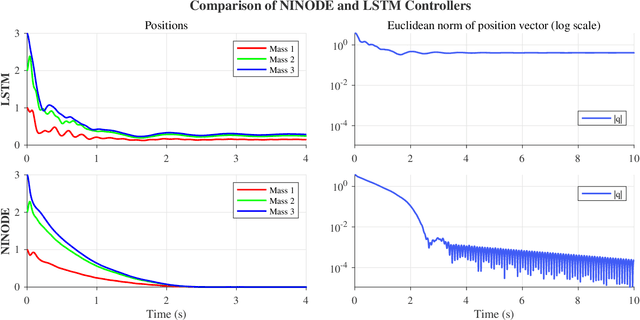
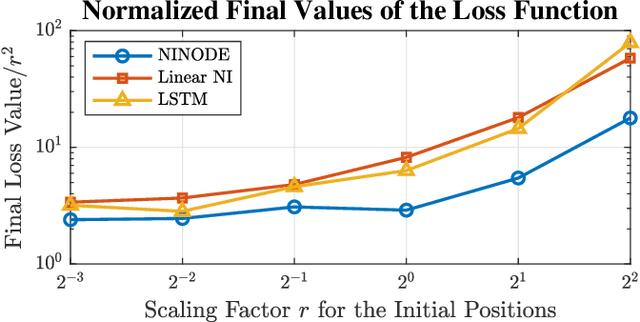
We propose a neural control method to provide guaranteed stabilization for mechanical systems using a novel negative imaginary neural ordinary differential equation (NINODE) controller. Specifically, we employ neural networks with desired properties as state-space function matrices within a Hamiltonian framework to ensure the system possesses the NI property. This NINODE system can serve as a controller that asymptotically stabilizes an NI plant under certain conditions. For mechanical plants with colocated force actuators and position sensors, we demonstrate that all the conditions required for stability can be translated into regularity constraints on the neural networks used in the controller. We illustrate the utility, effectiveness, and stability guarantees of the NINODE controller through an example involving a nonlinear mass-spring system.
R2DN: Scalable Parameterization of Contracting and Lipschitz Recurrent Deep Networks
Apr 01, 2025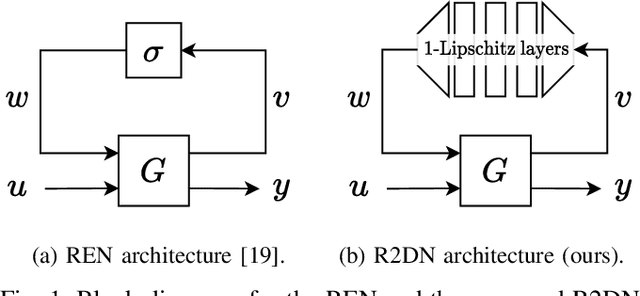
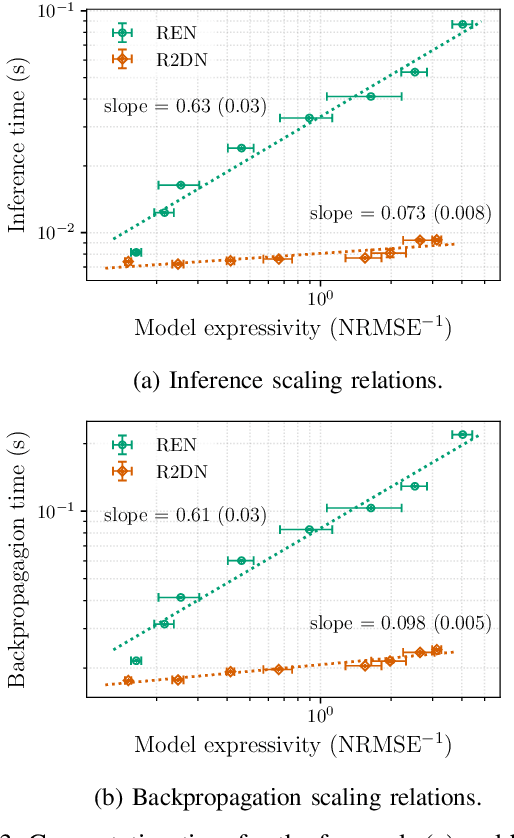
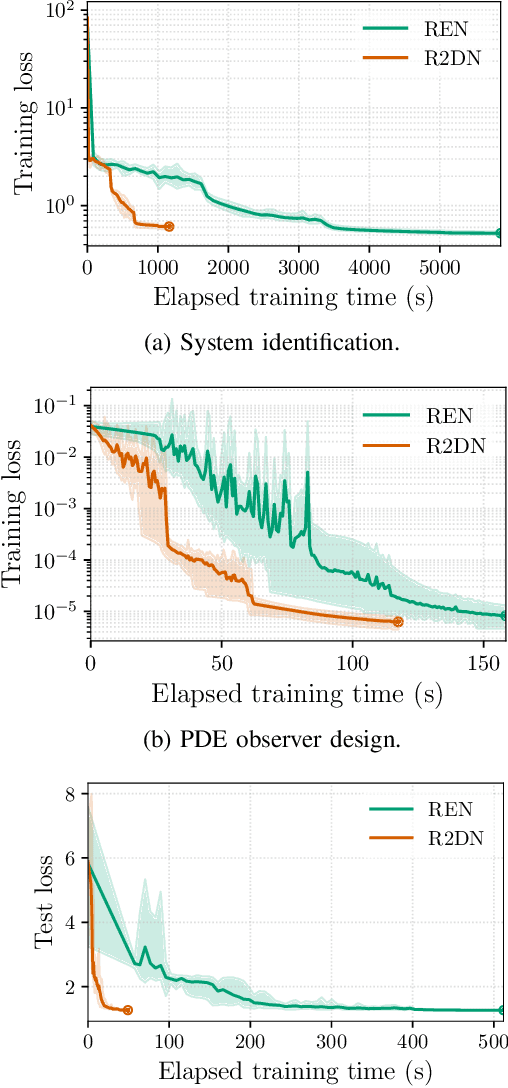
This paper presents the Robust Recurrent Deep Network (R2DN), a scalable parameterization of robust recurrent neural networks for machine learning and data-driven control. We construct R2DNs as a feedback interconnection of a linear time-invariant system and a 1-Lipschitz deep feedforward network, and directly parameterize the weights so that our models are stable (contracting) and robust to small input perturbations (Lipschitz) by design. Our parameterization uses a structure similar to the previously-proposed recurrent equilibrium networks (RENs), but without the requirement to iteratively solve an equilibrium layer at each time-step. This speeds up model evaluation and backpropagation on GPUs, and makes it computationally feasible to scale up the network size, batch size, and input sequence length in comparison to RENs. We compare R2DNs to RENs on three representative problems in nonlinear system identification, observer design, and learning-based feedback control and find that training and inference are both up to an order of magnitude faster with similar test set performance, and that training/inference times scale more favorably with respect to model expressivity.
Training Trajectory Predictors Without Ground-Truth Data
Feb 13, 2025This paper presents a framework capable of accurately and smoothly estimating position, heading, and velocity. Using this high-quality input, we propose a system based on Trajectron++, able to consistently generate precise trajectory predictions. Unlike conventional models that require ground-truth data for training, our approach eliminates this dependency. Our analysis demonstrates that poor quality input leads to noisy and unreliable predictions, which can be detrimental to navigation modules. We evaluate both input data quality and model output to illustrate the impact of input noise. Furthermore, we show that our estimation system enables effective training of trajectory prediction models even with limited data, producing robust predictions across different environments. Accurate estimations are crucial for deploying trajectory prediction models in real-world scenarios, and our system ensures meaningful and reliable results across various application contexts.
Norm-Bounded Low-Rank Adaptation
Jan 31, 2025



In this work, we propose norm-bounded low-rank adaptation (NB-LoRA) for parameter-efficient fine tuning. We introduce two parameterizations that allow explicit bounds on each singular value of the weight adaptation matrix, which can therefore satisfy any prescribed unitarily invariant norm bound, including the Schatten norms (e.g., nuclear, Frobenius, spectral norm). The proposed parameterizations are unconstrained and complete, i.e. they cover all matrices satisfying the prescribed rank and norm constraints. Experiments on vision fine-tuning benchmarks show that the proposed approach can achieve good adaptation performance while avoiding model catastrophic forgetting and also substantially improve robustness to a wide range of hyper-parameters, including adaptation rank, learning rate and number of training epochs. We also explore applications in privacy-preserving model merging and low-rank matrix completion.