 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing Privacy Risks in Language Models: A Case Study on Summarization Tasks
Oct 20, 2023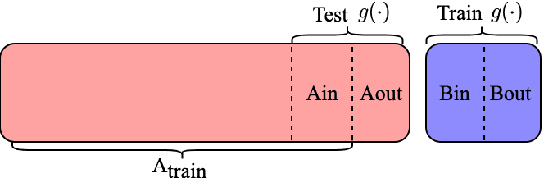
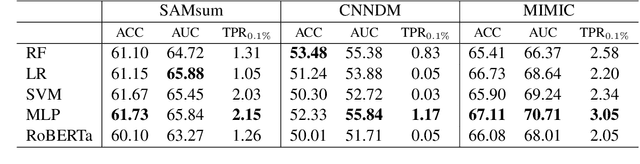
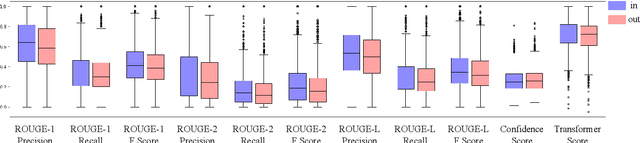
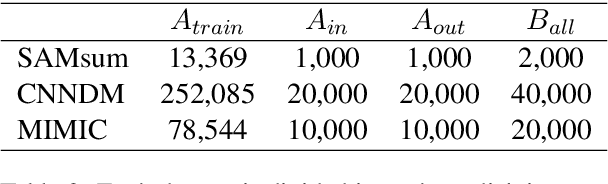
Large language models have revolutionized the field of NLP by achieving state-of-the-art performance on various tasks. However, there is a concern that these models may disclose information in the training data. In this study, we focus on the summarization task and investigate the membership inference (MI) attack: given a sample and black-box access to a model's API, it is possible to determine if the sample was part of the training data. We exploit text similarity and the model's resistance to document modifications as potential MI signals and evaluate their effectiveness on widely used datasets. Our results demonstrate that summarization models are at risk of exposing data membership, even in cases where the reference summary is not available. Furthermore, we discuss several safeguards for training summarization models to protect against MI attacks and discuss the inherent trade-off between privacy and utility.
Explicit and Implicit Semantic Ranking Framework
Apr 11, 2023


The core challenge in numerous real-world applications is to match an inquiry to the best document from a mutable and finite set of candidates. Existing industry solutions, especially latency-constrained services, often rely on similarity algorithms that sacrifice quality for speed. In this paper we introduce a generic semantic learning-to-rank framework, Self-training Semantic Cross-attention Ranking (sRank). This transformer-based framework uses linear pairwise loss with mutable training batch sizes and achieves quality gains and high efficiency, and has been applied effectively to show gains on two industry tasks at Microsoft over real-world large-scale data sets: Smart Reply (SR) and Ambient Clinical Intelligence (ACI). In Smart Reply, $sRank$ assists live customers with technical support by selecting the best reply from predefined solutions based on consumer and support agent messages. It achieves 11.7% gain in offline top-one accuracy on the SR task over the previous system, and has enabled 38.7% time reduction in composing messages in telemetry recorded since its general release in January 2021. In the ACI task, sRank selects relevant historical physician templates that serve as guidance for a text summarization model to generate higher quality medical notes. It achieves 35.5% top-one accuracy gain, along with 46% relative ROUGE-L gain in generated medical notes.
MIMICS: A Large-Scale Data Collection for Search Clarification
Jun 17, 2020



Search clarification has recently attracted much attention due to its applications in search engines. It has also been recognized as a major component in conversational information seeking systems. Despite its importance, the research community still feels the lack of a large-scale data for studying different aspects of search clarification. In this paper, we introduce MIMICS, a collection of search clarification datasets for real web search queries sampled from the Bing query logs. Each clarification in MIMICS is generated by a Bing production algorithm and consists of a clarifying question and up to five candidate answers. MIMICS contains three datasets: (1) MIMICS-Click includes over 400k unique queries, their associated clarification panes, and the corresponding aggregated user interaction signals (i.e., clicks). (2) MIMICS-ClickExplore is an exploration data that includes aggregated user interaction signals for over 60k unique queries, each with multiple clarification panes. (3) MIMICS-Manual includes over 2k unique real search queries. Each query-clarification pair in this dataset has been manually labeled by at least three trained annotators. It contains graded quality labels for the clarifying question, the candidate answer set, and the landing result page for each candidate answer. MIMICS is publicly available for research purposes, thus enables researchers to study a number of tasks related to search clarification, including clarification generation and selection, user engagement prediction for clarification, click models for clarification, and analyzing user interactions with search clarification.