 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multimodal Approach to Device-Directed Speech Detection with Large Language Models
Mar 26, 2024Interactions with virtual assistants typically start with a predefined trigger phrase followed by the user command. To make interactions with the assistant more intuitive, we explore whether it is feasible to drop the requirement that users must begin each command with a trigger phrase. We explore this task in three ways: First, we train classifiers using only acoustic information obtained from the audio waveform. Second, we take the decoder outputs of an automatic speech recognition (ASR) system, such as 1-best hypotheses, as input features to a large language model (LLM). Finally, we explore a multimodal system that combines acoustic and lexical features, as well as ASR decoder signals in an LLM. Using multimodal information yields relative equal-error-rate improvements over text-only and audio-only models of up to 39% and 61%. Increasing the size of the LLM and training with low-rank adaption leads to further relative EER reductions of up to 18% on our dataset.
Multimodal Data and Resource Efficient Device-Directed Speech Detection with Large Foundation Models
Dec 06, 2023Interactions with virtual assistants typically start with a trigger phrase followed by a command. In this work, we explore the possibility of making these interactions more natural by eliminating the need for a trigger phrase. Our goal is to determine whether a user addressed the virtual assistant based on signals obtained from the streaming audio recorded by the device microphone. We address this task by combining 1-best hypotheses and decoder signals from an automatic speech recognition system with acoustic representations from an audio encoder as input features to a large language model (LLM). In particular, we are interested in data and resource efficient systems that require only a small amount of training data and can operate in scenarios with only a single frozen LLM available on a device. For this reason, our model is trained on 80k or less examples of multimodal data using a combination of low-rank adaptation and prefix tuning. We compare the proposed system to unimodal baselines and show that the multimodal approach achieves lower equal-error-rates (EERs), while using only a fraction of the training data. We also show that low-dimensional specialized audio representations lead to lower EERs than high-dimensional general audio representations.
Marrying Fairness and Explainability in Supervised Learning
Apr 06, 2022
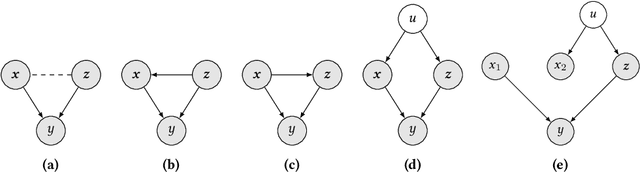


Machine learning algorithms that aid human decision-making may inadvertently discriminate against certain protected groups. We formalize direct discrimination as a direct causal effect of the protected attributes on the decisions, while induced discrimination as a change in the causal influence of non-protected features associated with the protected attributes. The measurements of marginal direct effect (MDE) and SHapley Additive exPlanations (SHAP) reveal that state-of-the-art fair learning methods can induce discrimination via association or reverse discrimination in synthetic and real-world datasets. To inhibit discrimination in algorithmic systems, we propose to nullify the influence of the protected attribute on the output of the system, while preserving the influence of remaining features. We introduce and study post-processing methods achieving such objectives, finding that they yield relatively high model accuracy, prevent direct discrimination, and diminishes various disparity measures, e.g., demographic disparity.