 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgressive Voice Trigger Detection: Accuracy vs Latency
Oct 29, 2020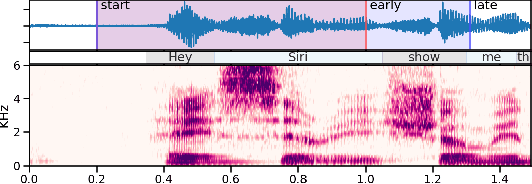
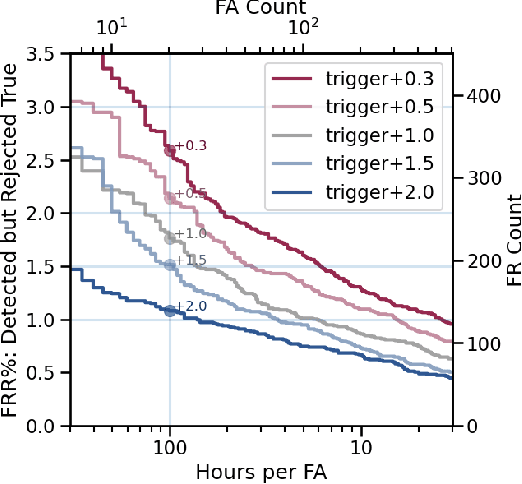
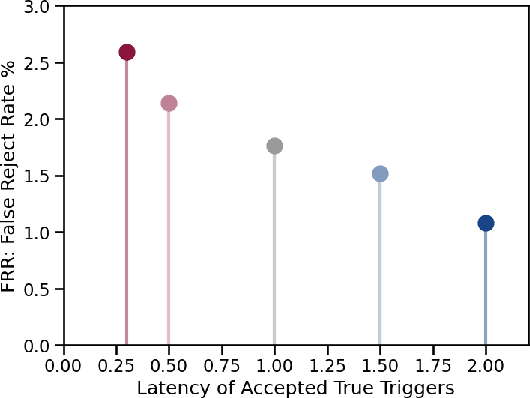
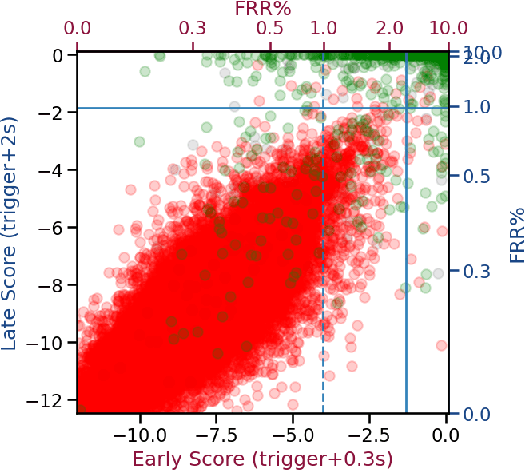
We present an architecture for voice trigger detection for virtual assistants. The main idea in this work is to exploit information in words that immediately follow the trigger phrase. We first demonstrate that by including more audio context after a detected trigger phrase, we can indeed get a more accurate decision. However, waiting to listen to more audio each time incurs a latency increase. Progressive Voice Trigger Detection allows us to trade-off latency and accuracy by accepting clear trigger candidates quickly, but waiting for more context to decide whether to accept more marginal examples. Using a two-stage architecture, we show that by delaying the decision for just 3% of detected true triggers in the test set, we are able to obtain a relative improvement of 66% in false rejection rate, while incurring only a negligible increase in latency.
Multi-task Learning for Speaker Verification and Voice Trigger Detection
Jan 26, 2020
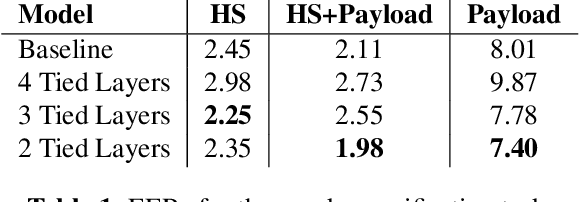
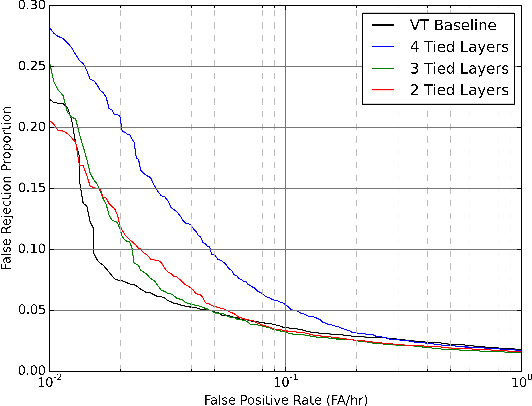
Automatic speech transcription and speaker recognition are usually treated as separate tasks even though they are interdependent. In this study, we investigate training a single network to perform both tasks jointly. We train the network in a supervised multi-task learning setup, where the speech transcription branch of the network is trained to minimise a phonetic connectionist temporal classification (CTC) loss while the speaker recognition branch of the network is trained to label the input sequence with the correct label for the speaker. We present a large-scale empirical study where the model is trained using several thousand hours of labelled training data for each task. We evaluate the speech transcription branch of the network on a voice trigger detection task while the speaker recognition branch is evaluated on a speaker verification task. Results demonstrate that the network is able to encode both phonetic \emph{and} speaker information in its learnt representations while yielding accuracies at least as good as the baseline models for each task, with the same number of parameters as the independent models.
Multi-task Learning for Voice Trigger Detection
Jan 26, 2020
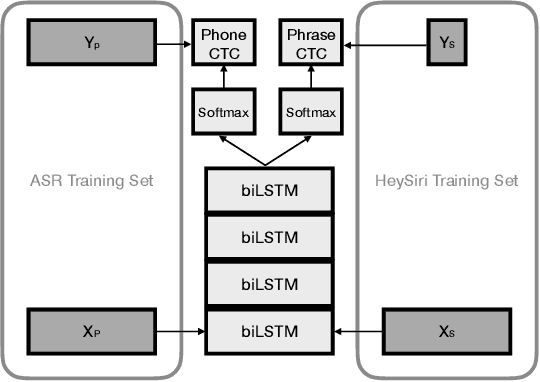
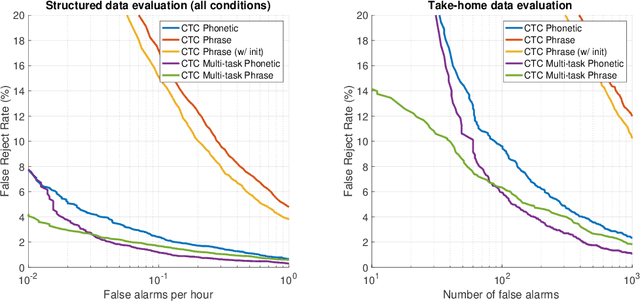
We describe the design of a voice trigger detection system for smart speakers. In this study, we address two major challenges. The first is that the detectors are deployed in complex acoustic environments with external noise and loud playback by the device itself. Secondly, collecting training examples for a specific keyword or trigger phrase is challenging resulting in a scarcity of trigger phrase specific training data. We describe a two-stage cascaded architecture where a low-power detector is always running and listening for the trigger phrase. If a detection is made at this stage, the candidate audio segment is re-scored by larger, more complex models to verify that the segment contains the trigger phrase. In this study, we focus our attention on the architecture and design of these second-pass detectors. We start by training a general acoustic model that produces phonetic transcriptions given a large labelled training dataset. Next, we collect a much smaller dataset of examples that are challenging for the baseline system. We then use multi-task learning to train a model to simultaneously produce accurate phonetic transcriptions on the larger dataset \emph{and} discriminate between true and easily confusable examples using the smaller dataset. Our results demonstrate that the proposed model reduces errors by half compared to the baseline in a range of challenging test conditions \emph{without} requiring extra parameters.