 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-task Learning for Speaker Verification and Voice Trigger Detection
Paper and Code
Jan 26, 2020
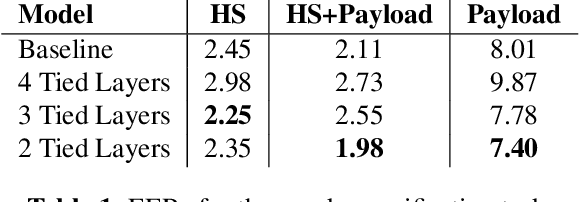
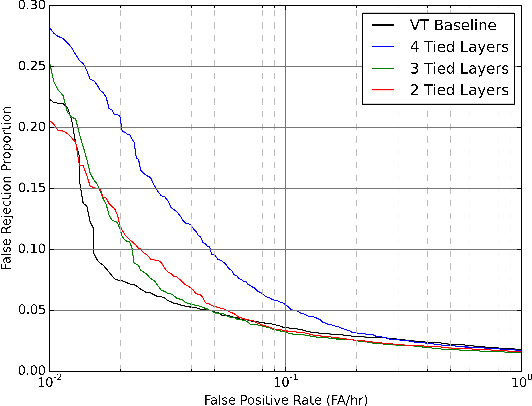
Automatic speech transcription and speaker recognition are usually treated as separate tasks even though they are interdependent. In this study, we investigate training a single network to perform both tasks jointly. We train the network in a supervised multi-task learning setup, where the speech transcription branch of the network is trained to minimise a phonetic connectionist temporal classification (CTC) loss while the speaker recognition branch of the network is trained to label the input sequence with the correct label for the speaker. We present a large-scale empirical study where the model is trained using several thousand hours of labelled training data for each task. We evaluate the speech transcription branch of the network on a voice trigger detection task while the speaker recognition branch is evaluated on a speaker verification task. Results demonstrate that the network is able to encode both phonetic \emph{and} speaker information in its learnt representations while yielding accuracies at least as good as the baseline models for each task, with the same number of parameters as the independent models.