 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-task Learning for Voice Trigger Detection
Jan 26, 2020
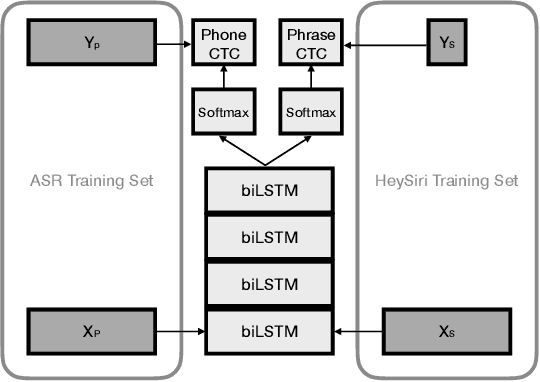
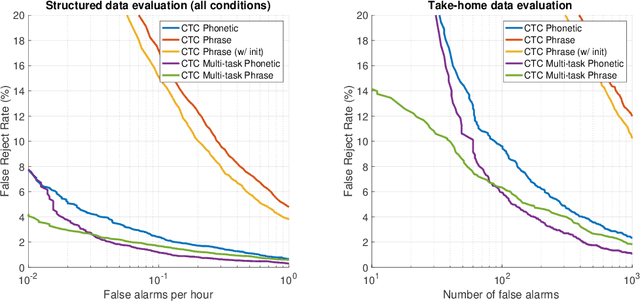
We describe the design of a voice trigger detection system for smart speakers. In this study, we address two major challenges. The first is that the detectors are deployed in complex acoustic environments with external noise and loud playback by the device itself. Secondly, collecting training examples for a specific keyword or trigger phrase is challenging resulting in a scarcity of trigger phrase specific training data. We describe a two-stage cascaded architecture where a low-power detector is always running and listening for the trigger phrase. If a detection is made at this stage, the candidate audio segment is re-scored by larger, more complex models to verify that the segment contains the trigger phrase. In this study, we focus our attention on the architecture and design of these second-pass detectors. We start by training a general acoustic model that produces phonetic transcriptions given a large labelled training dataset. Next, we collect a much smaller dataset of examples that are challenging for the baseline system. We then use multi-task learning to train a model to simultaneously produce accurate phonetic transcriptions on the larger dataset \emph{and} discriminate between true and easily confusable examples using the smaller dataset. Our results demonstrate that the proposed model reduces errors by half compared to the baseline in a range of challenging test conditions \emph{without} requiring extra parameters.