 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDevice-Directed Speech Detection for Follow-up Conversations Using Large Language Models
Nov 04, 2024Follow-up conversations with virtual assistants (VAs) enable a user to seamlessly interact with a VA without the need to repeatedly invoke it using a keyword (after the first query). Therefore, accurate Device-directed Speech Detection (DDSD) from the follow-up queries is critical for enabling naturalistic user experience. To this end, we explore the notion of Large Language Models (LLMs) and model the first query when making inference about the follow-ups (based on the ASR-decoded text), via prompting of a pretrained LLM, or by adapting a binary classifier on top of the LLM. In doing so, we also exploit the ASR uncertainty when designing the LLM prompts. We show on the real-world dataset of follow-up conversations that this approach yields large gains (20-40% reduction in false alarms at 10% fixed false rejects) due to the joint modeling of the previous speech context and ASR uncertainty, compared to when follow-ups are modeled alone.
Apple Intelligence Foundation Language Models
Jul 29, 2024



We present foundation language models developed to power Apple Intelligence features, including a ~3 billion parameter model designed to run efficiently on devices and a large server-based language model designed for Private Cloud Compute. These models are designed to perform a wide range of tasks efficiently, accurately, and responsibly. This report describes the model architecture, the data used to train the model, the training process, how the models are optimized for inference, and the evaluation results. We highlight our focus on Responsible AI and how the principles are applied throughout the model development.
Modality Dropout for Multimodal Device Directed Speech Detection using Verbal and Non-Verbal Features
Oct 23, 2023Device-directed speech detection (DDSD) is the binary classification task of distinguishing between queries directed at a voice assistant versus side conversation or background speech. State-of-the-art DDSD systems use verbal cues, e.g acoustic, text and/or automatic speech recognition system (ASR) features, to classify speech as device-directed or otherwise, and often have to contend with one or more of these modalities being unavailable when deployed in real-world settings. In this paper, we investigate fusion schemes for DDSD systems that can be made more robust to missing modalities. Concurrently, we study the use of non-verbal cues, specifically prosody features, in addition to verbal cues for DDSD. We present different approaches to combine scores and embeddings from prosody with the corresponding verbal cues, finding that prosody improves DDSD performance by upto 8.5% in terms of false acceptance rate (FA) at a given fixed operating point via non-linear intermediate fusion, while our use of modality dropout techniques improves the performance of these models by 7.4% in terms of FA when evaluated with missing modalities during inference time.
Leveraging Large Language Models for Exploiting ASR Uncertainty
Sep 12, 2023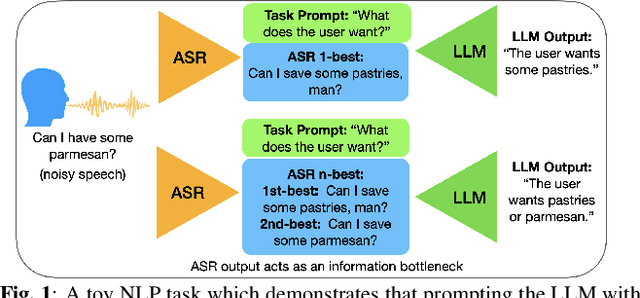


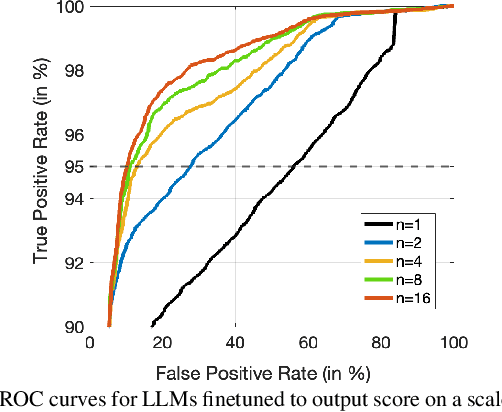
While large language models excel in a variety of natural language processing (NLP) tasks, to perform well on spoken language understanding (SLU) tasks, they must either rely on off-the-shelf automatic speech recognition (ASR) systems for transcription, or be equipped with an in-built speech modality. This work focuses on the former scenario, where LLM's accuracy on SLU tasks is constrained by the accuracy of a fixed ASR system on the spoken input. Specifically, we tackle speech-intent classification task, where a high word-error-rate can limit the LLM's ability to understand the spoken intent. Instead of chasing a high accuracy by designing complex or specialized architectures regardless of deployment costs, we seek to answer how far we can go without substantially changing the underlying ASR and LLM, which can potentially be shared by multiple unrelated tasks. To this end, we propose prompting the LLM with an n-best list of ASR hypotheses instead of only the error-prone 1-best hypothesis. We explore prompt-engineering to explain the concept of n-best lists to the LLM; followed by the finetuning of Low-Rank Adapters on the downstream tasks. Our approach using n-best lists proves to be effective on a device-directed speech detection task as well as on a keyword spotting task, where systems using n-best list prompts outperform those using 1-best ASR hypothesis; thus paving the way for an efficient method to exploit ASR uncertainty via LLMs for speech-based applications.
Device-Directed Speech Detection: Regularization via Distillation for Weakly-Supervised Models
Mar 30, 2022


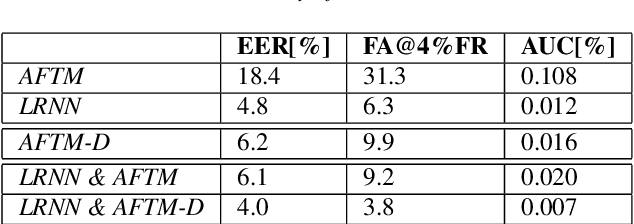
We address the problem of detecting speech directed to a device that does not contain a specific wake-word. Specifically, we focus on audio coming from a touch-based invocation. Mitigating virtual assistants (VAs) activation due to accidental button presses is critical for user experience. While the majority of approaches to false trigger mitigation (FTM) are designed to detect the presence of a target keyword, inferring user intent in absence of keyword is difficult. This also poses a challenge when creating the training/evaluation data for such systems due to inherent ambiguity in the user's data. To this end, we propose a novel FTM approach that uses weakly-labeled training data obtained with a newly introduced data sampling strategy. While this sampling strategy reduces data annotation efforts, the data labels are noisy as the data are not annotated manually. We use these data to train an acoustics-only model for the FTM task by regularizing its loss function via knowledge distillation from an ASR-based (LatticeRNN) model. This improves the model decisions, resulting in 66% gain in accuracy, as measured by equal-error-rate (EER), over the base acoustics-only model. We also show that the ensemble of the LatticeRNN and acoustic-distilled models brings further accuracy improvement of 20%.
Streaming on-device detection of device directed speech from voice and touch-based invocation
Oct 09, 2021
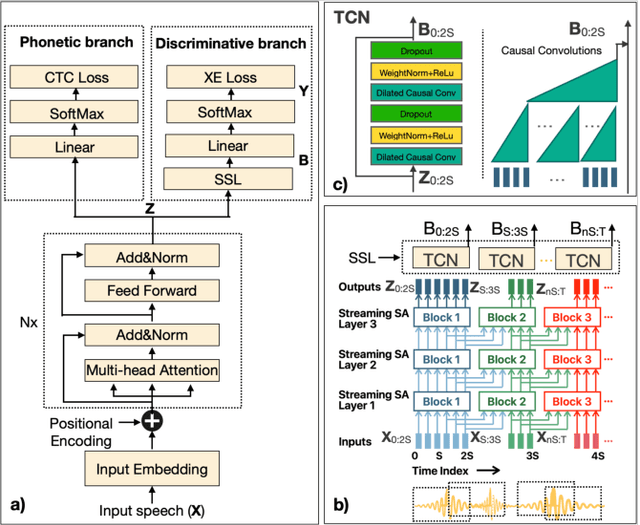
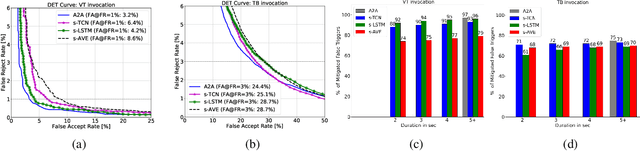
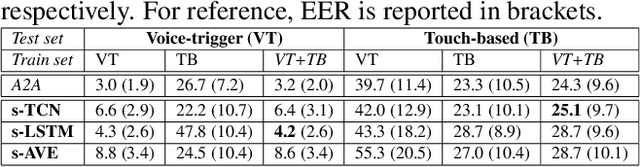
When interacting with smart devices such as mobile phones or wearables, the user typically invokes a virtual assistant (VA) by saying a keyword or by pressing a button on the device. However, in many cases, the VA can accidentally be invoked by the keyword-like speech or accidental button press, which may have implications on user experience and privacy. To this end, we propose an acoustic false-trigger-mitigation (FTM) approach for on-device device-directed speech detection that simultaneously handles the voice-trigger and touch-based invocation. To facilitate the model deployment on-device, we introduce a new streaming decision layer, derived using the notion of temporal convolutional networks (TCN) [1], known for their computational efficiency. To the best of our knowledge, this is the first approach that can detect device-directed speech from more than one invocation type in a streaming fashion. We compare this approach with streaming alternatives based on vanilla Average layer, and canonical LSTMs, and show: (i) that all the models show only a small degradation in accuracy compared with the invocation-specific models, and (ii) that the newly introduced streaming TCN consistently performs better or comparable with the alternatives, while mitigating device undirected speech faster in time, and with (relative) reduction in runtime peak-memory over the LSTM-based approach of 33% vs. 7%, when compared to a non-streaming counterpart.
Streaming Transformer for Hardware Efficient Voice Trigger Detection and False Trigger Mitigation
May 14, 2021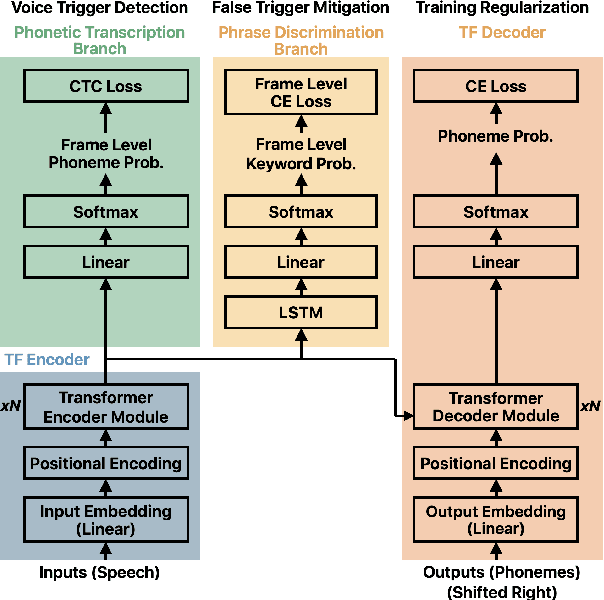
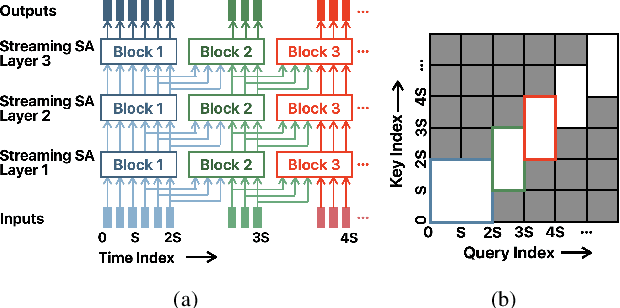

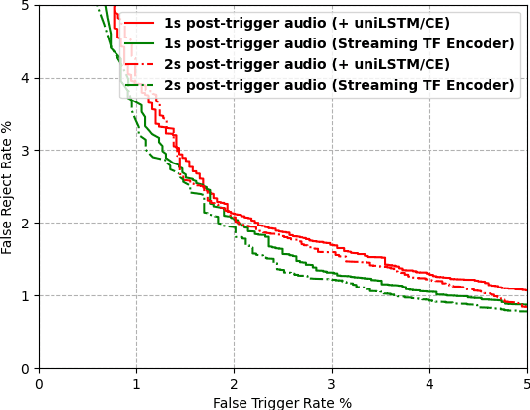
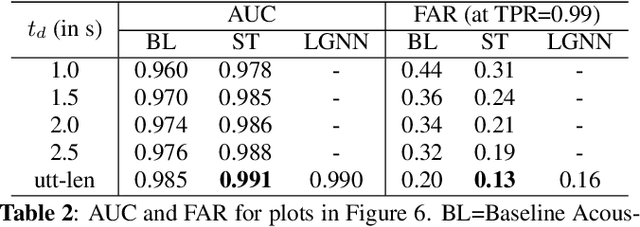
We present a unified and hardware efficient architecture for two stage voice trigger detection (VTD) and false trigger mitigation (FTM) tasks. Two stage VTD systems of voice assistants can get falsely activated to audio segments acoustically similar to the trigger phrase of interest. FTM systems cancel such activations by using post trigger audio context. Traditional FTM systems rely on automatic speech recognition lattices which are computationally expensive to obtain on device. We propose a streaming transformer (TF) encoder architecture, which progressively processes incoming audio chunks and maintains audio context to perform both VTD and FTM tasks using only acoustic features. The proposed joint model yields an average 18% relative reduction in false reject rate (FRR) for the VTD task at a given false alarm rate. Moreover, our model suppresses 95% of the false triggers with an additional one second of post-trigger audio. Finally, on-device measurements show 32% reduction in runtime memory and 56% reduction in inference time compared to non-streaming version of the model.
Knowledge Transfer for Efficient On-device False Trigger Mitigation
Oct 20, 2020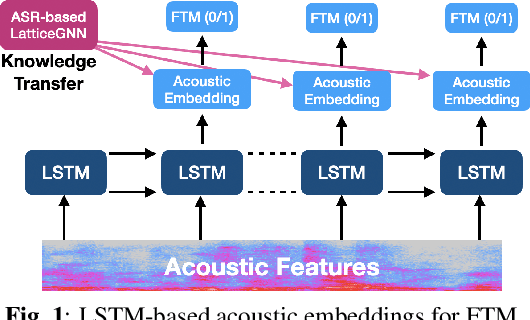

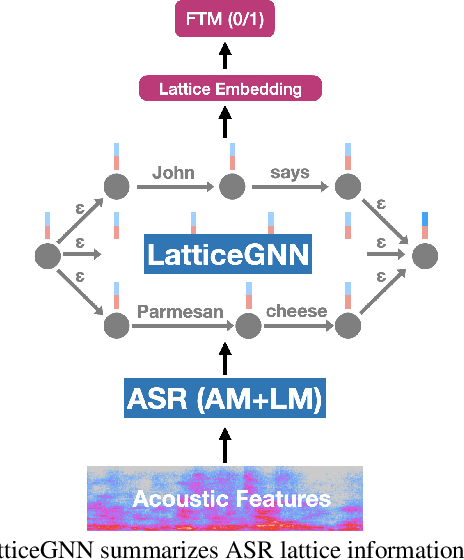
In this paper, we address the task of determining whether a given utterance is directed towards a voice-enabled smart-assistant device or not. An undirected utterance is termed as a "false trigger" and false trigger mitigation (FTM) is essential for designing a privacy-centric non-intrusive smart assistant. The directedness of an utterance can be identified by running automatic speech recognition (ASR) on it and determining the user intent by analyzing the ASR transcript. But in case of a false trigger, transcribing the audio using ASR itself is strongly undesirable. To alleviate this issue, we propose an LSTM-based FTM architecture which determines the user intent from acoustic features directly without explicitly generating ASR transcripts from the audio. The proposed models are small footprint and can be run on-device with limited computational resources. During training, the model parameters are optimized using a knowledge transfer approach where a more accurate self-attention graph neural network model serves as the teacher. Given the whole audio snippets, our approach mitigates 87% of false triggers at 99% true positive rate (TPR), and in a streaming audio scenario, the system listens to only 1.69s of the false trigger audio before rejecting it while achieving the same TPR.
Complementary Language Model and Parallel Bi-LRNN for False Trigger Mitigation
Aug 18, 2020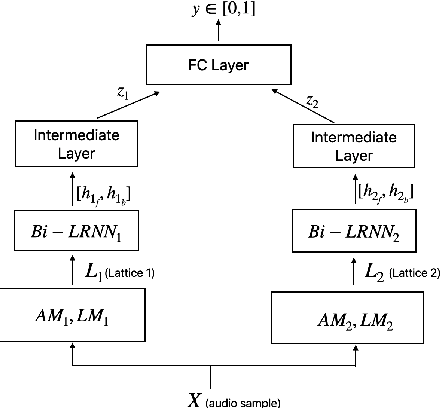

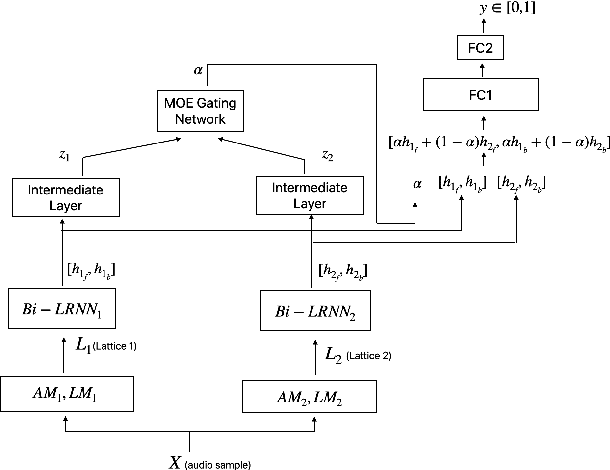
False triggers in voice assistants are unintended invocations of the assistant, which not only degrade the user experience but may also compromise privacy. False trigger mitigation (FTM) is a process to detect the false trigger events and respond appropriately to the user. In this paper, we propose a novel solution to the FTM problem by introducing a parallel ASR decoding process with a special language model trained from "out-of-domain" data sources. Such language model is complementary to the existing language model optimized for the assistant task. A bidirectional lattice RNN (Bi-LRNN) classifier trained from the lattices generated by the complementary language model shows a $38.34\%$ relative reduction of the false trigger (FT) rate at the fixed rate of $0.4\%$ false suppression (FS) of correct invocations, compared to the current Bi-LRNN model. In addition, we propose to train a parallel Bi-LRNN model based on the decoding lattices from both language models, and examine various ways of implementation. The resulting model leads to further reduction in the false trigger rate by $10.8\%$.
Lattice-based Improvements for Voice Triggering Using Graph Neural Networks
Jan 25, 2020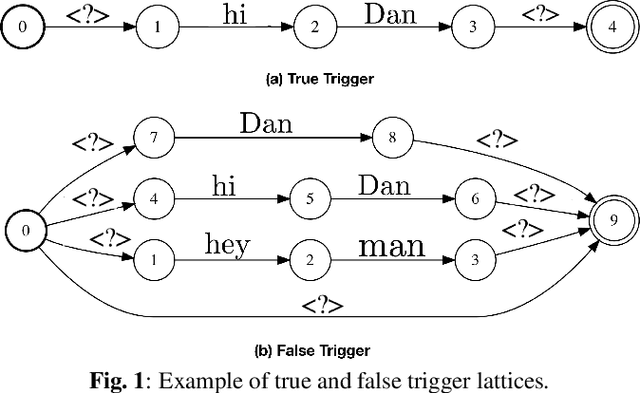
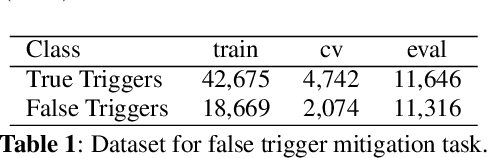
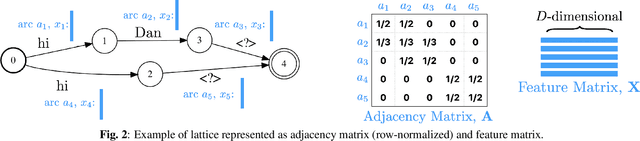

Voice-triggered smart assistants often rely on detection of a trigger-phrase before they start listening for the user request. Mitigation of false triggers is an important aspect of building a privacy-centric non-intrusive smart assistant. In this paper, we address the task of false trigger mitigation (FTM) using a novel approach based on analyzing automatic speech recognition (ASR) lattices using graph neural networks (GNN). The proposed approach uses the fact that decoding lattice of a falsely triggered audio exhibits uncertainties in terms of many alternative paths and unexpected words on the lattice arcs as compared to the lattice of a correctly triggered audio. A pure trigger-phrase detector model doesn't fully utilize the intent of the user speech whereas by using the complete decoding lattice of user audio, we can effectively mitigate speech not intended for the smart assistant. We deploy two variants of GNNs in this paper based on 1) graph convolution layers and 2) self-attention mechanism respectively. Our experiments demonstrate that GNNs are highly accurate in FTM task by mitigating ~87% of false triggers at 99% true positive rate (TPR). Furthermore, the proposed models are fast to train and efficient in parameter requirements.