 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEELBERT: Tiny Models through Dynamic Embeddings
Oct 31, 2023We introduce EELBERT, an approach for compression of transformer-based models (e.g., BERT), with minimal impact on the accuracy of downstream tasks. This is achieved by replacing the input embedding layer of the model with dynamic, i.e. on-the-fly, embedding computations. Since the input embedding layer accounts for a significant fraction of the model size, especially for the smaller BERT variants, replacing this layer with an embedding computation function helps us reduce the model size significantly. Empirical evaluation on the GLUE benchmark shows that our BERT variants (EELBERT) suffer minimal regression compared to the traditional BERT models. Through this approach, we are able to develop our smallest model UNO-EELBERT, which achieves a GLUE score within 4% of fully trained BERT-tiny, while being 15x smaller (1.2 MB) in size.
Complementary Language Model and Parallel Bi-LRNN for False Trigger Mitigation
Aug 18, 2020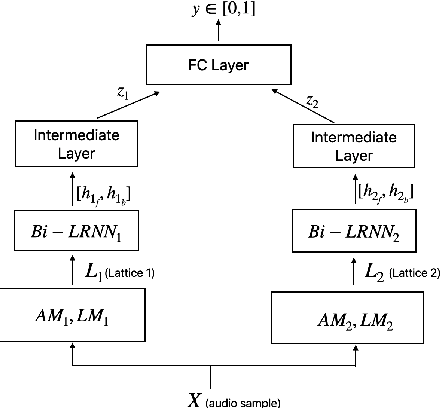

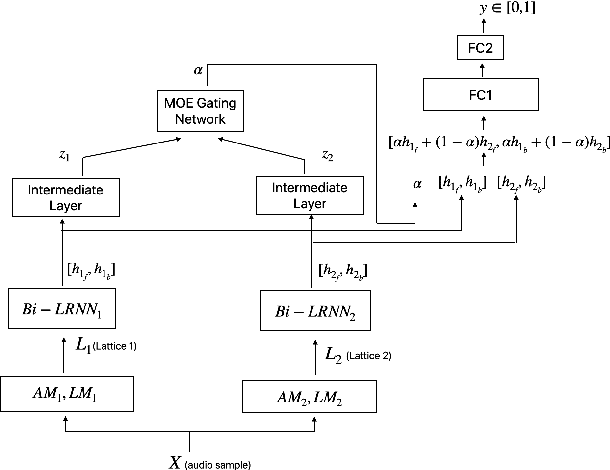
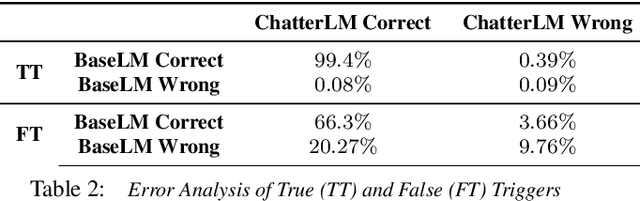
False triggers in voice assistants are unintended invocations of the assistant, which not only degrade the user experience but may also compromise privacy. False trigger mitigation (FTM) is a process to detect the false trigger events and respond appropriately to the user. In this paper, we propose a novel solution to the FTM problem by introducing a parallel ASR decoding process with a special language model trained from "out-of-domain" data sources. Such language model is complementary to the existing language model optimized for the assistant task. A bidirectional lattice RNN (Bi-LRNN) classifier trained from the lattices generated by the complementary language model shows a $38.34\%$ relative reduction of the false trigger (FT) rate at the fixed rate of $0.4\%$ false suppression (FS) of correct invocations, compared to the current Bi-LRNN model. In addition, we propose to train a parallel Bi-LRNN model based on the decoding lattices from both language models, and examine various ways of implementation. The resulting model leads to further reduction in the false trigger rate by $10.8\%$.