 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModality Dropout for Multimodal Device Directed Speech Detection using Verbal and Non-Verbal Features
Oct 23, 2023Device-directed speech detection (DDSD) is the binary classification task of distinguishing between queries directed at a voice assistant versus side conversation or background speech. State-of-the-art DDSD systems use verbal cues, e.g acoustic, text and/or automatic speech recognition system (ASR) features, to classify speech as device-directed or otherwise, and often have to contend with one or more of these modalities being unavailable when deployed in real-world settings. In this paper, we investigate fusion schemes for DDSD systems that can be made more robust to missing modalities. Concurrently, we study the use of non-verbal cues, specifically prosody features, in addition to verbal cues for DDSD. We present different approaches to combine scores and embeddings from prosody with the corresponding verbal cues, finding that prosody improves DDSD performance by upto 8.5% in terms of false acceptance rate (FA) at a given fixed operating point via non-linear intermediate fusion, while our use of modality dropout techniques improves the performance of these models by 7.4% in terms of FA when evaluated with missing modalities during inference time.
Brain Signals to Rescue Aphasia, Apraxia and Dysarthria Speech Recognition
Feb 28, 2021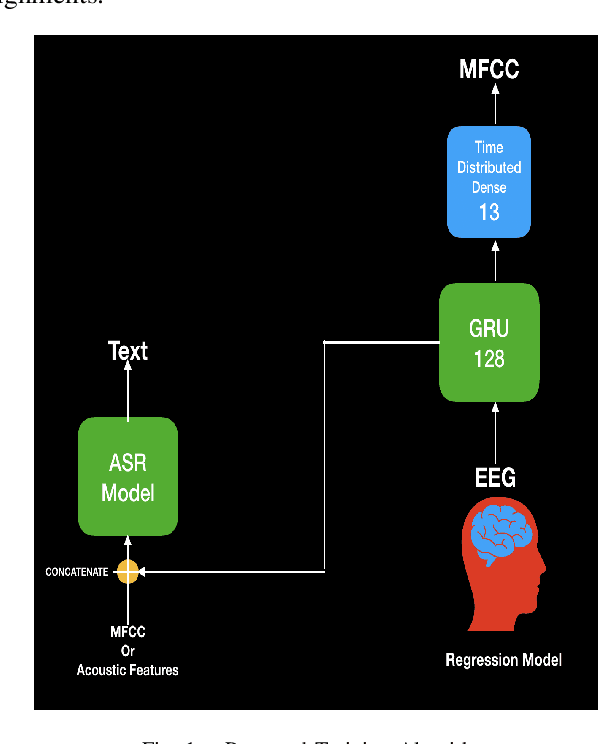
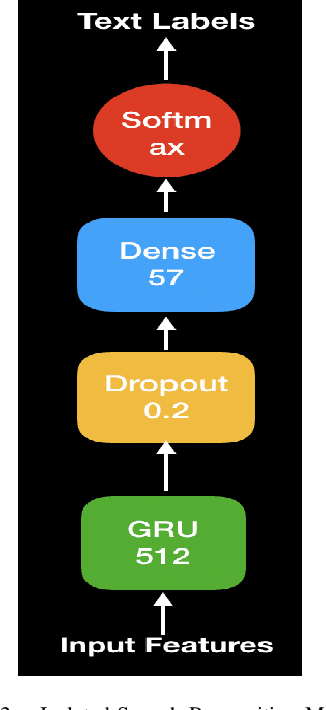
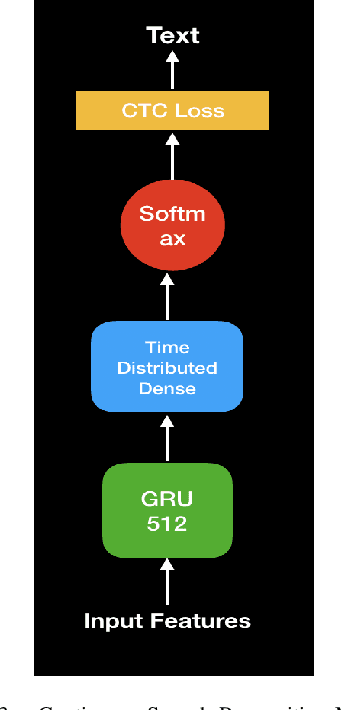
In this paper, we propose a deep learning-based algorithm to improve the performance of automatic speech recognition (ASR) systems for aphasia, apraxia, and dysarthria speech by utilizing electroencephalography (EEG) features recorded synchronously with aphasia, apraxia, and dysarthria speech. We demonstrate a significant decoding performance improvement by more than 50\% during test time for isolated speech recognition task and we also provide preliminary results indicating performance improvement for the more challenging continuous speech recognition task by utilizing EEG features. The results presented in this paper show the first step towards demonstrating the possibility of utilizing non-invasive neural signals to design a real-time robust speech prosthetic for stroke survivors recovering from aphasia, apraxia, and dysarthria. Our aphasia, apraxia, and dysarthria speech-EEG data set will be released to the public to help further advance this interesting and crucial research.
Pneumonia Detection on Chest X-ray using Radiomic Features and Contrastive Learning
Jan 12, 2021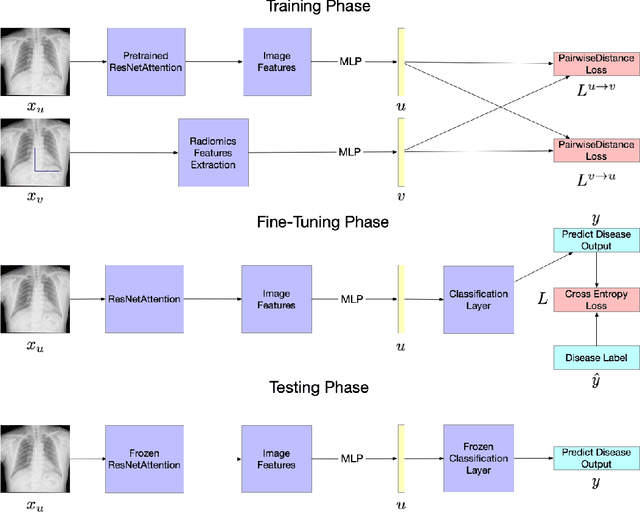
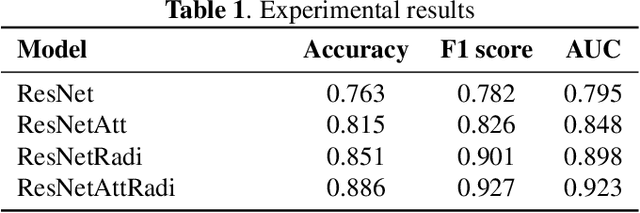
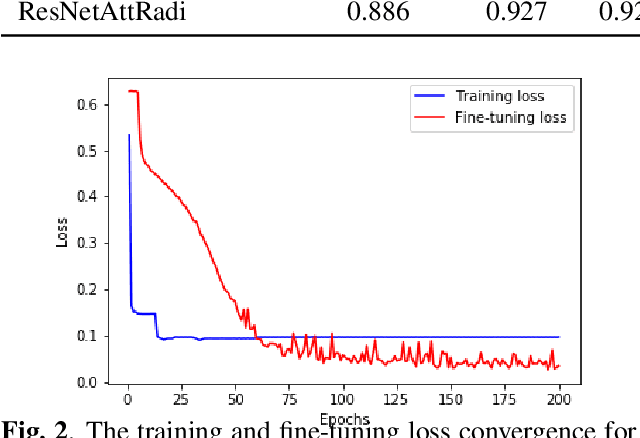
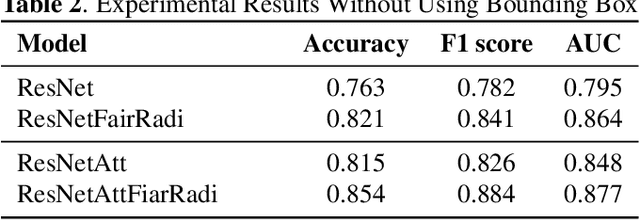
Chest X-ray becomes one of the most common medical diagnoses due to its noninvasiveness. The number of chest X-ray images has skyrocketed, but reading chest X-rays still have been manually performed by radiologists, which creates huge burnouts and delays. Traditionally, radiomics, as a subfield of radiology that can extract a large number of quantitative features from medical images, demonstrates its potential to facilitate medical imaging diagnosis before the deep learning era. With the rise of deep learning, the explainability of deep neural networks on chest X-ray diagnosis remains opaque. In this study, we proposed a novel framework that leverages radiomics features and contrastive learning to detect pneumonia in chest X-ray. Experiments on the RSNA Pneumonia Detection Challenge dataset show that our model achieves superior results to several state-of-the-art models (> 10% in F1-score) and increases the model's interpretability.
Speech Recognition using EEG signals recorded using dry electrodes
Aug 13, 2020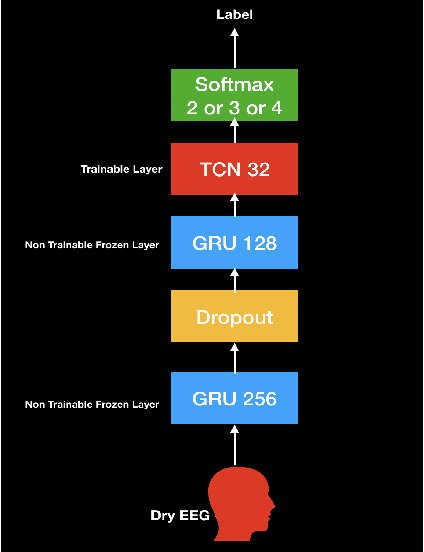
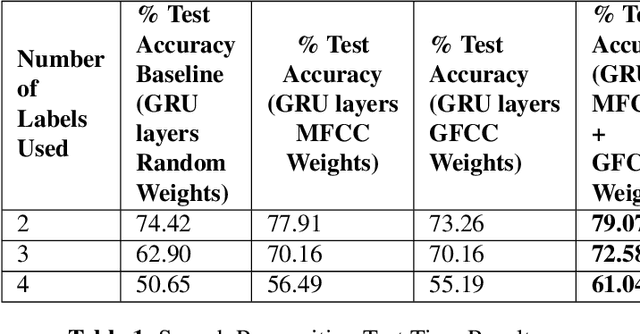
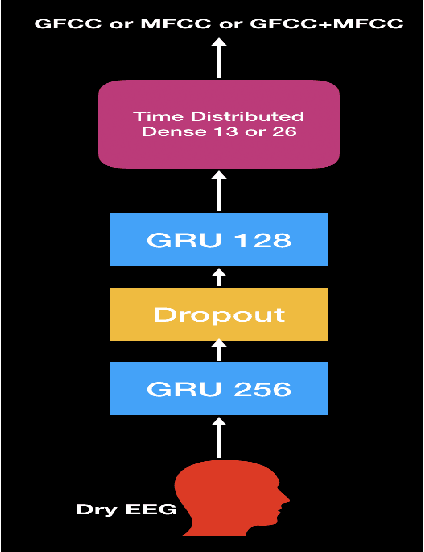
In this paper, we demonstrate speech recognition using electroencephalography (EEG) signals obtained using dry electrodes on a limited English vocabulary consisting of three vowels and one word using a deep learning model. We demonstrate a test accuracy of 79.07 percent on a subset vocabulary consisting of two English vowels. Our results demonstrate the feasibility of using EEG signals recorded using dry electrodes for performing the task of speech recognition.
Generating EEG features from Acoustic features
Mar 19, 2020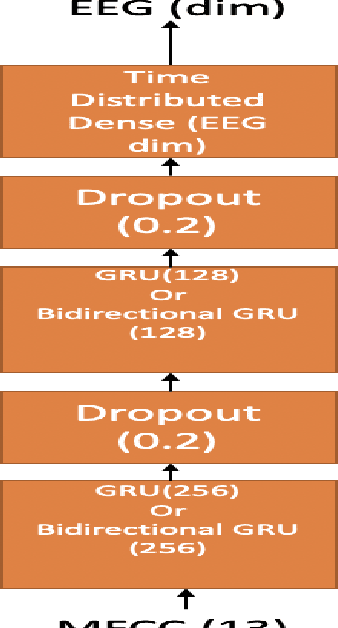

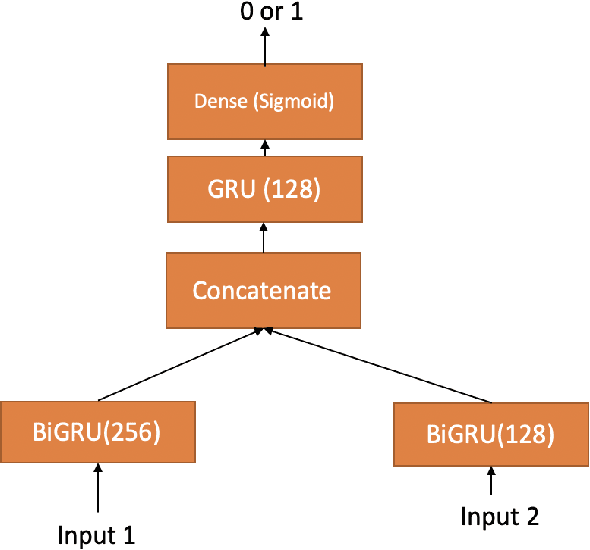
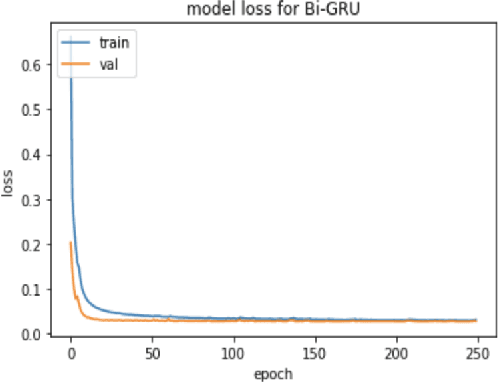
In this paper we demonstrate predicting electroencephalograpgy (EEG) features from acoustic features using recurrent neural network (RNN) based regression model and generative adversarial network (GAN). We predict various types of EEG features from acoustic features. We compare our results with the previously studied problem on speech synthesis using EEG and our results demonstrate that EEG features can be generated from acoustic features with lower root mean square error (RMSE), normalized RMSE values compared to generating acoustic features from EEG features (ie: speech synthesis using EEG) when tested using the same data sets.
EEG based Continuous Speech Recognition using Transformers
Dec 31, 2019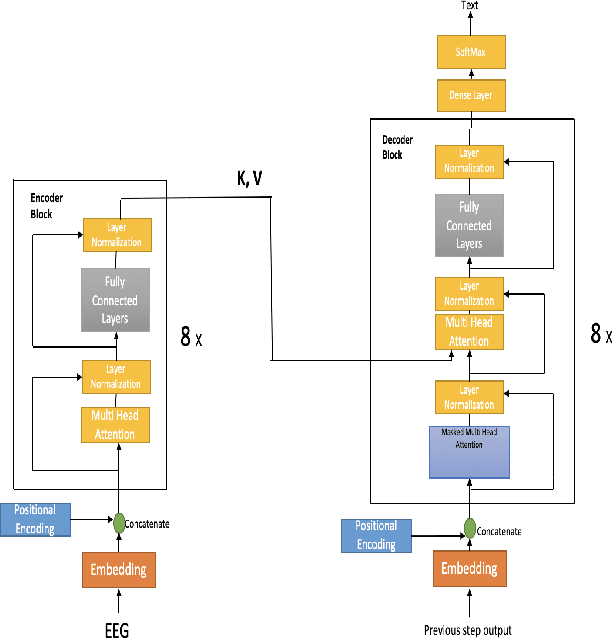
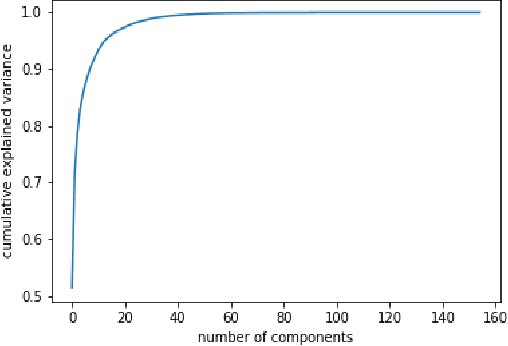
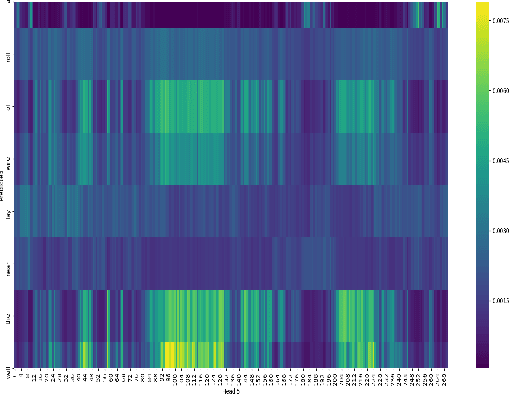
In this paper we investigate continuous speech recognition using electroencephalography (EEG) features using recently introduced end-to-end transformer based automatic speech recognition (ASR) model. Our results show that transformer based model demonstrate faster inference and training compared to recurrent neural network (RNN) based sequence-to-sequence EEG models but performance of the RNN based models were better than transformer based model during test time on a limited English vocabulary.
Continuous Speech Recognition using EEG and Video
Dec 27, 2019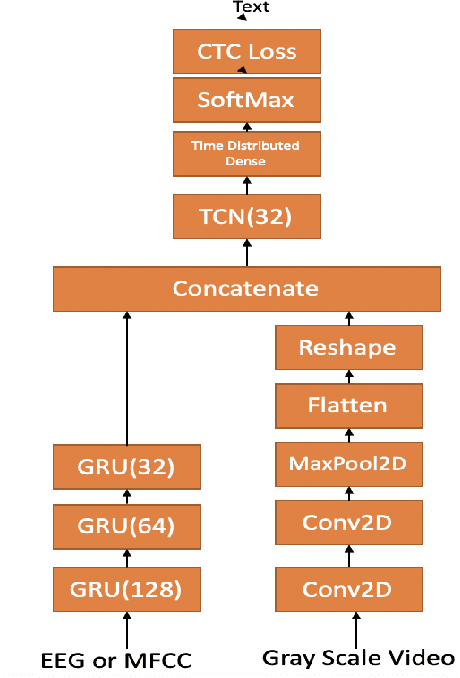
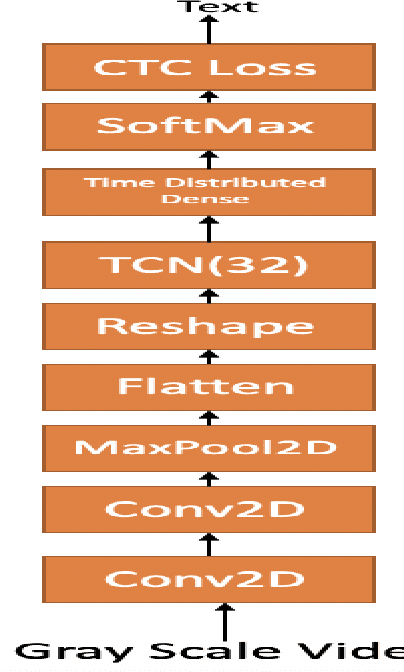
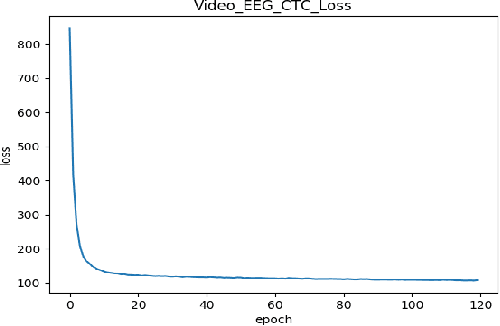
In this paper we investigate whether electroencephalography (EEG) features can be used to improve the performance of continuous visual speech recognition systems. We implemented a connectionist temporal classification (CTC) based end-to-end automatic speech recognition (ASR) model for performing recognition. Our results demonstrate that EEG features are helpful in enhancing the performance of continuous visual speech recognition systems.
Improving EEG based Continuous Speech Recognition
Dec 24, 2019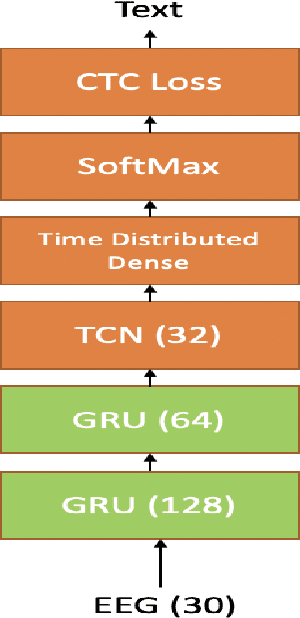
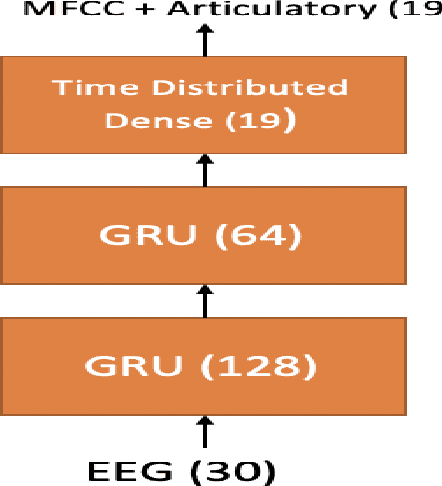
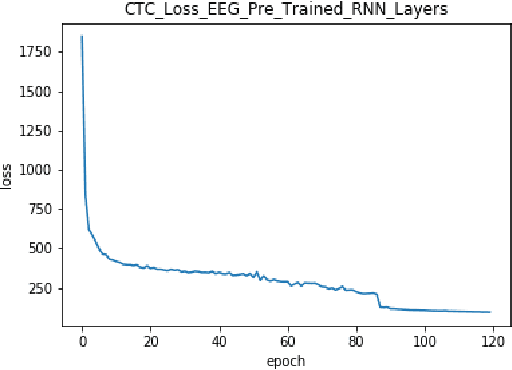
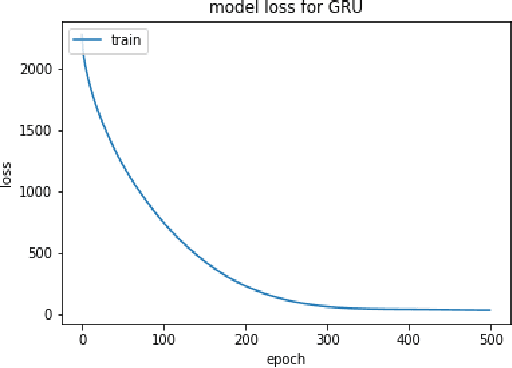
In this paper we introduce various techniques to improve the performance of electroencephalography (EEG) features based continuous speech recognition (CSR) systems. A connectionist temporal classification (CTC) based automatic speech recognition (ASR) system was implemented for performing recognition. We introduce techniques to initialize the weights of the recurrent layers in the encoder of the CTC model with more meaningful weights rather than with random weights and we make use of an external language model to improve the beam search during decoding time. We finally study the problem of predicting articulatory features from EEG features in this paper.
Spoken Speech Enhancement using EEG
Oct 29, 2019

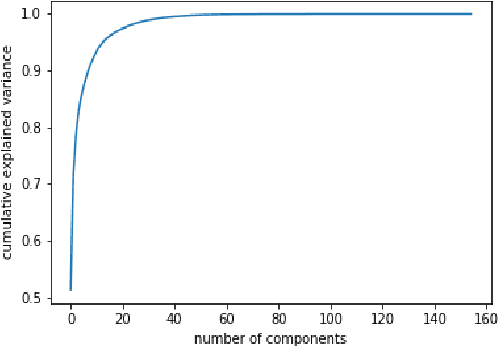
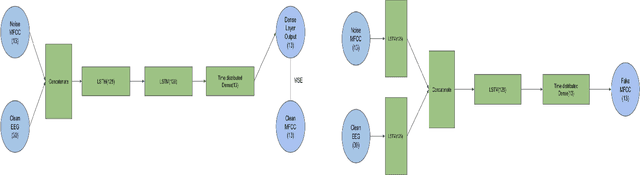
In this paper we demonstrate spoken speech enhancement using electroencephalography (EEG) signals using a generative adversarial network (GAN) based model and Long short-term Memory (LSTM) regression based model. Our results demonstrate that EEG features can be used to clean speech recorded in presence of background noise.
Advancing Speech Recognition With No Speech Or With Noisy Speech
Jul 27, 2019
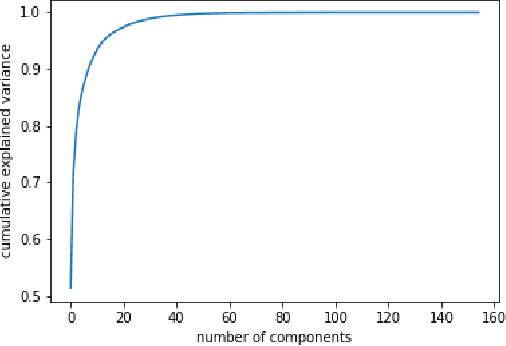
In this paper we demonstrate end to end continuous speech recognition (CSR) using electroencephalography (EEG) signals with no speech signal as input. An attention model based automatic speech recognition (ASR) and connectionist temporal classification (CTC) based ASR systems were implemented for performing recognition. We further demonstrate CSR for noisy speech by fusing with EEG features.