Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating EEG features from Acoustic features
Paper and Code
Mar 19, 2020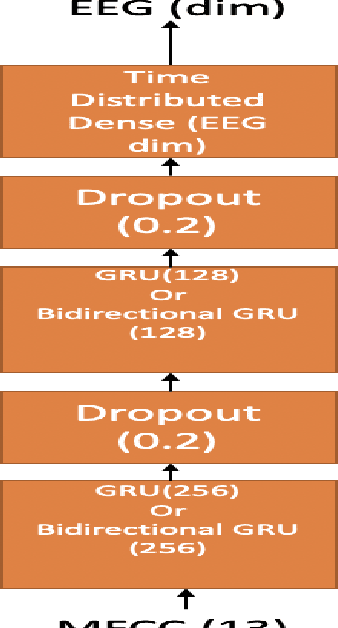

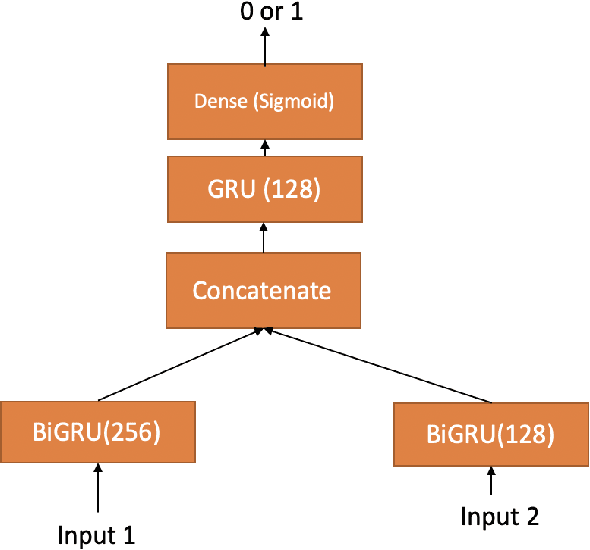
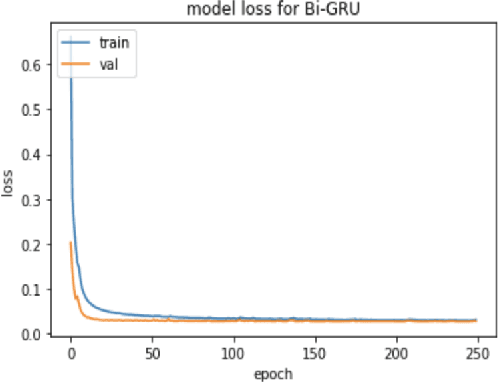
In this paper we demonstrate predicting electroencephalograpgy (EEG) features from acoustic features using recurrent neural network (RNN) based regression model and generative adversarial network (GAN). We predict various types of EEG features from acoustic features. We compare our results with the previously studied problem on speech synthesis using EEG and our results demonstrate that EEG features can be generated from acoustic features with lower root mean square error (RMSE), normalized RMSE values compared to generating acoustic features from EEG features (ie: speech synthesis using EEG) when tested using the same data sets.
View paper on