 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrain Signals to Rescue Aphasia, Apraxia and Dysarthria Speech Recognition
Paper and Code
Feb 28, 2021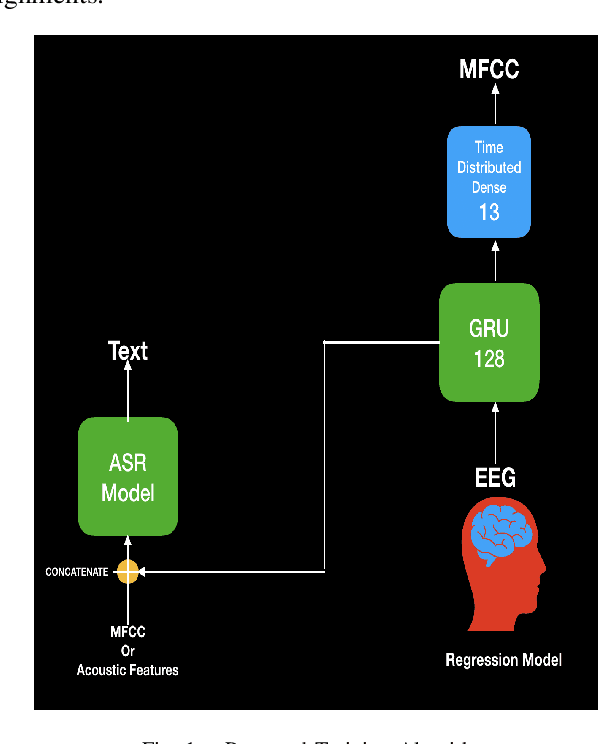
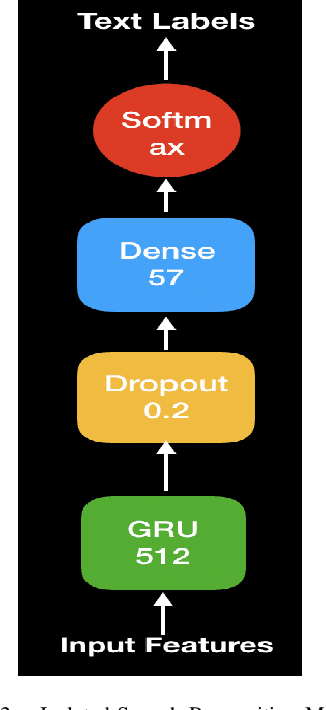
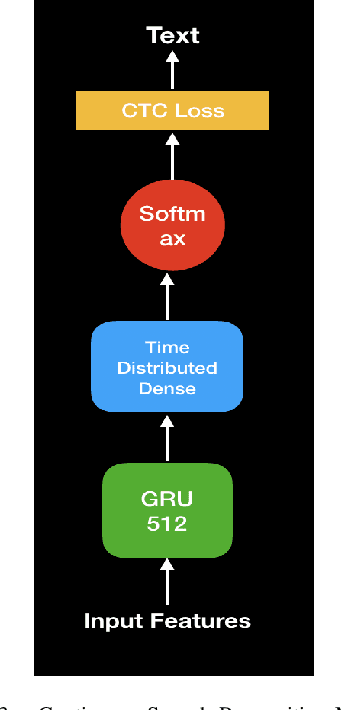
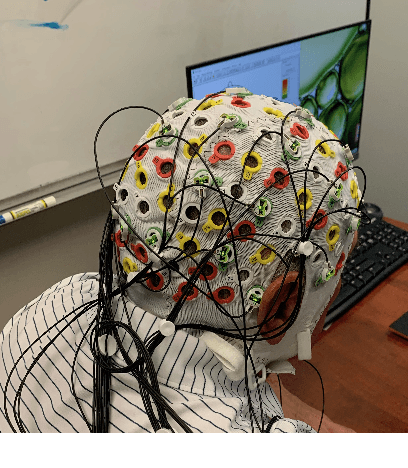
In this paper, we propose a deep learning-based algorithm to improve the performance of automatic speech recognition (ASR) systems for aphasia, apraxia, and dysarthria speech by utilizing electroencephalography (EEG) features recorded synchronously with aphasia, apraxia, and dysarthria speech. We demonstrate a significant decoding performance improvement by more than 50\% during test time for isolated speech recognition task and we also provide preliminary results indicating performance improvement for the more challenging continuous speech recognition task by utilizing EEG features. The results presented in this paper show the first step towards demonstrating the possibility of utilizing non-invasive neural signals to design a real-time robust speech prosthetic for stroke survivors recovering from aphasia, apraxia, and dysarthria. Our aphasia, apraxia, and dysarthria speech-EEG data set will be released to the public to help further advance this interesting and crucial research.