 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Large Language Models with Fusion Low Rank Adaptation for Device Directed Speech Detection
Jun 13, 2024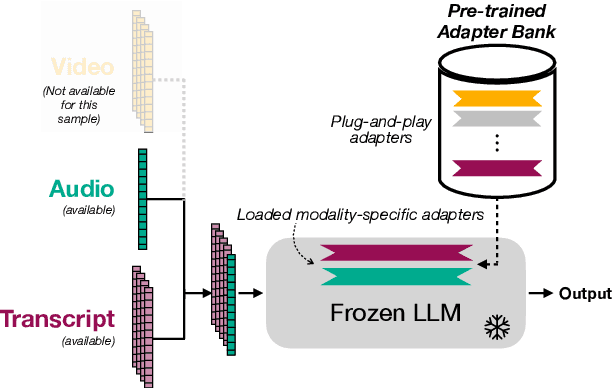
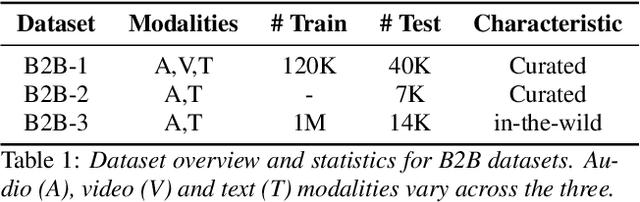
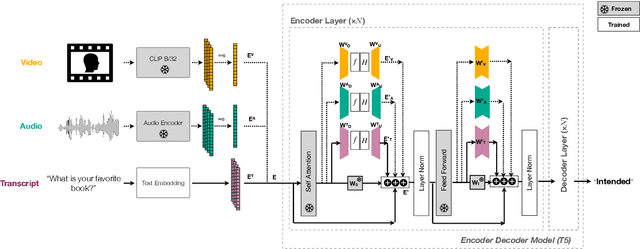
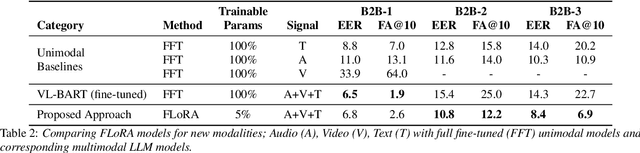
Although Large Language Models (LLMs) have shown promise for human-like conversations, they are primarily pre-trained on text data. Incorporating audio or video improves performance, but collecting large-scale multimodal data and pre-training multimodal LLMs is challenging. To this end, we propose a Fusion Low Rank Adaptation (FLoRA) technique that efficiently adapts a pre-trained unimodal LLM to consume new, previously unseen modalities via low rank adaptation. For device-directed speech detection, using FLoRA, the multimodal LLM achieves 22% relative reduction in equal error rate (EER) over the text-only approach and attains performance parity with its full fine-tuning (FFT) counterpart while needing to tune only a fraction of its parameters. Furthermore, with the newly introduced adapter dropout, FLoRA is robust to missing data, improving over FFT by 20% lower EER and 56% lower false accept rate. The proposed approach scales well for model sizes from 16M to 3B parameters.
Modality Dropout for Multimodal Device Directed Speech Detection using Verbal and Non-Verbal Features
Oct 23, 2023Device-directed speech detection (DDSD) is the binary classification task of distinguishing between queries directed at a voice assistant versus side conversation or background speech. State-of-the-art DDSD systems use verbal cues, e.g acoustic, text and/or automatic speech recognition system (ASR) features, to classify speech as device-directed or otherwise, and often have to contend with one or more of these modalities being unavailable when deployed in real-world settings. In this paper, we investigate fusion schemes for DDSD systems that can be made more robust to missing modalities. Concurrently, we study the use of non-verbal cues, specifically prosody features, in addition to verbal cues for DDSD. We present different approaches to combine scores and embeddings from prosody with the corresponding verbal cues, finding that prosody improves DDSD performance by upto 8.5% in terms of false acceptance rate (FA) at a given fixed operating point via non-linear intermediate fusion, while our use of modality dropout techniques improves the performance of these models by 7.4% in terms of FA when evaluated with missing modalities during inference time.