 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Large Language Models with Fusion Low Rank Adaptation for Device Directed Speech Detection
Jun 13, 2024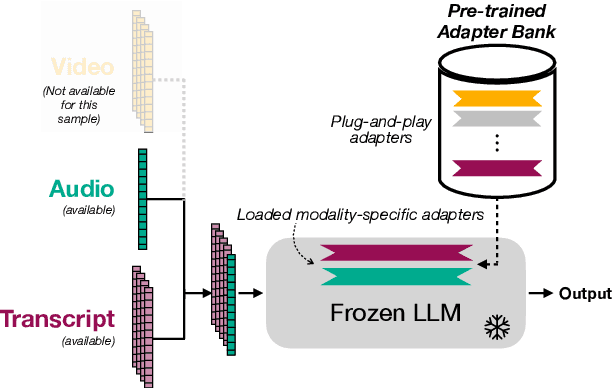
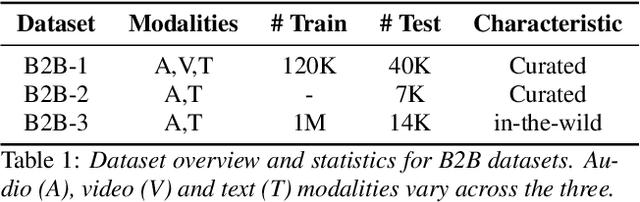
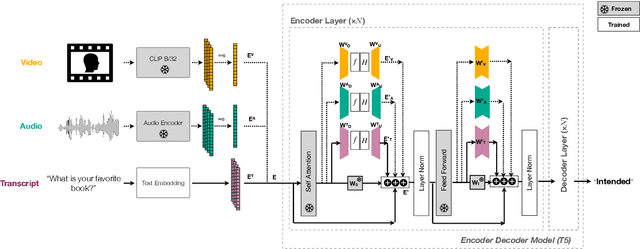
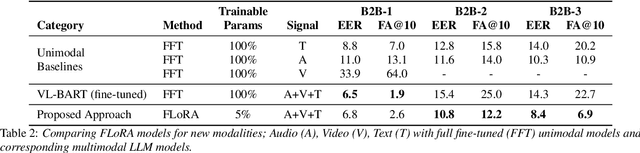
Although Large Language Models (LLMs) have shown promise for human-like conversations, they are primarily pre-trained on text data. Incorporating audio or video improves performance, but collecting large-scale multimodal data and pre-training multimodal LLMs is challenging. To this end, we propose a Fusion Low Rank Adaptation (FLoRA) technique that efficiently adapts a pre-trained unimodal LLM to consume new, previously unseen modalities via low rank adaptation. For device-directed speech detection, using FLoRA, the multimodal LLM achieves 22% relative reduction in equal error rate (EER) over the text-only approach and attains performance parity with its full fine-tuning (FFT) counterpart while needing to tune only a fraction of its parameters. Furthermore, with the newly introduced adapter dropout, FLoRA is robust to missing data, improving over FFT by 20% lower EER and 56% lower false accept rate. The proposed approach scales well for model sizes from 16M to 3B parameters.
On Advances in Text Generation from Images Beyond Captioning: A Case Study in Self-Rationalization
May 24, 2022


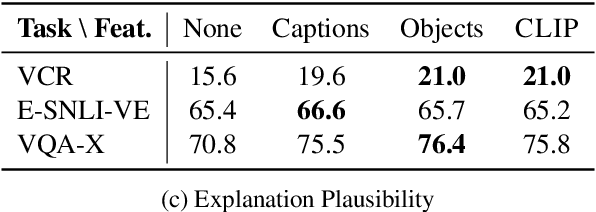
Integrating vision and language has gained notable attention following the success of pretrained language models. Despite that, a fraction of emerging multimodal models is suitable for text generation conditioned on images. This minority is typically developed and evaluated for image captioning, a text generation task conditioned solely on images with the goal to describe what is explicitly visible in an image. In this paper, we take a step back and ask: How do these models work for more complex generative tasks, conditioned on both text and images? Are models based on joint multimodal pretraining, visually adapted pretrained language models, or models that combine these two approaches, more promising for such tasks? We address these questions in the context of self-rationalization (jointly generating task labels/answers and free-text explanations) of three tasks: (i) visual question answering in VQA-X, (ii) visual commonsense reasoning in VCR, and (iii) visual-textual entailment in E-SNLI-VE. We show that recent advances in each modality, CLIP image representations and scaling of language models, do not consistently improve multimodal self-rationalization of tasks with multimodal inputs. We also observe that no model type works universally the best across tasks/datasets and finetuning data sizes. Our findings call for a backbone modelling approach that can be built on to advance text generation from images and text beyond image captioning.
Speech Summarization using Restricted Self-Attention
Oct 12, 2021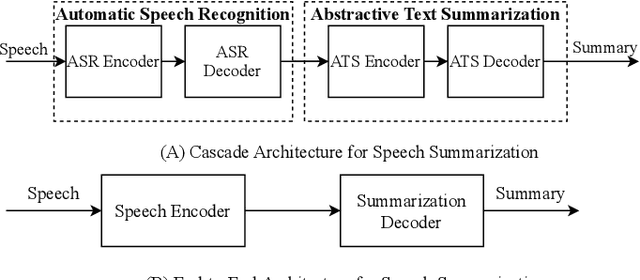
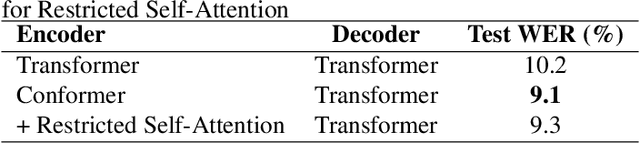
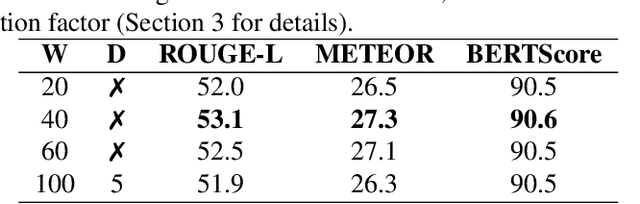
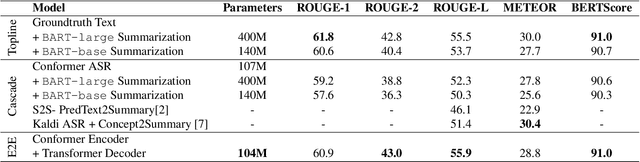
Speech summarization is typically performed by using a cascade of speech recognition and text summarization models. End-to-end modeling of speech summarization models is challenging due to memory and compute constraints arising from long input audio sequences. Recent work in document summarization has inspired methods to reduce the complexity of self-attentions, which enables transformer models to handle long sequences. In this work, we introduce a single model optimized end-to-end for speech summarization. We apply the restricted self-attention technique from text-based models to speech models to address the memory and compute constraints. We demonstrate that the proposed model learns to directly summarize speech for the How-2 corpus of instructional videos. The proposed end-to-end model outperforms the previously proposed cascaded model by 3 points absolute on ROUGE. Further, we consider the spoken language understanding task of predicting concepts from speech inputs and show that the proposed end-to-end model outperforms the cascade model by 4 points absolute F-1.
How2Sign: A Large-scale Multimodal Dataset for Continuous American Sign Language
Aug 18, 2020
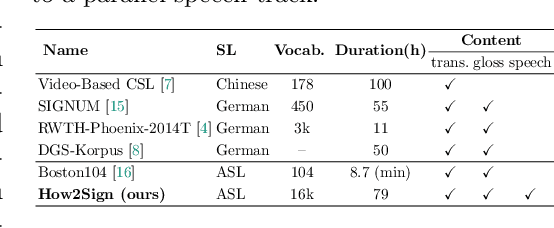
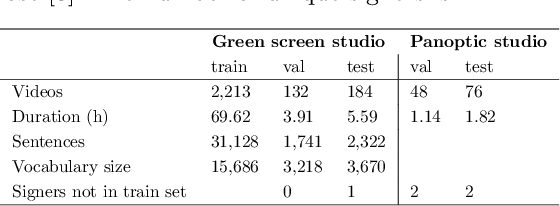
Sign Language is the primary means of communication for the majority of the Deaf community. One of the factors that has hindered the progress in the areas of automatic sign language recognition, generation, and translation is the absence of large annotated datasets, especially continuous sign language datasets, i.e. datasets that are annotated and segmented at the sentence or utterance level. Towards this end, in this work we introduce How2Sign, a work-in-progress dataset collection. How2Sign consists of a parallel corpus of 80 hours of sign language videos (collected with multi-view RGB and depth sensor data) with corresponding speech transcriptions and gloss annotations. In addition, a three-hour subset was further recorded in a geodesic dome setup using hundreds of cameras and sensors, which enables detailed 3D reconstruction and pose estimation and paves the way for vision systems to understand the 3D geometry of sign language.
ASR Error Correction and Domain Adaptation Using Machine Translation
Mar 13, 2020
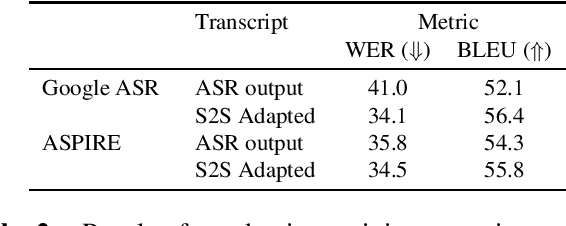
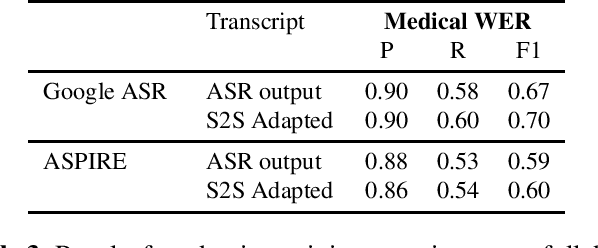

Off-the-shelf pre-trained Automatic Speech Recognition (ASR) systems are an increasingly viable service for companies of any size building speech-based products. While these ASR systems are trained on large amounts of data, domain mismatch is still an issue for many such parties that want to use this service as-is leading to not so optimal results for their task. We propose a simple technique to perform domain adaptation for ASR error correction via machine translation. The machine translation model is a strong candidate to learn a mapping from out-of-domain ASR errors to in-domain terms in the corresponding reference files. We use two off-the-shelf ASR systems in this work: Google ASR (commercial) and the ASPIRE model (open-source). We observe 7% absolute improvement in word error rate and 4 point absolute improvement in BLEU score in Google ASR output via our proposed method. We also evaluate ASR error correction via a downstream task of Speaker Diarization that captures speaker style, syntax, structure and semantic improvements we obtain via ASR correction.
Multimodal Abstractive Summarization for How2 Videos
Jun 19, 2019
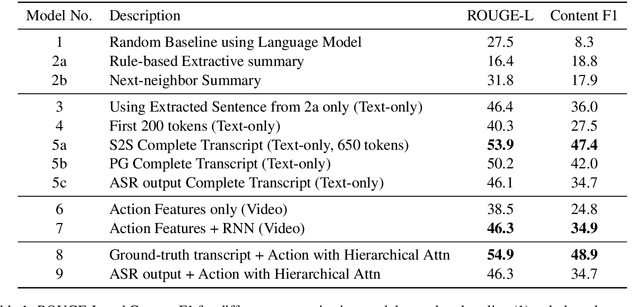
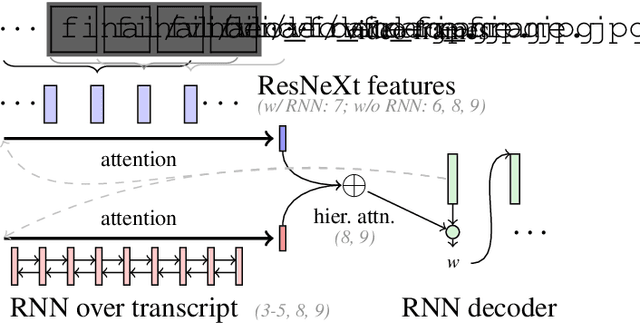
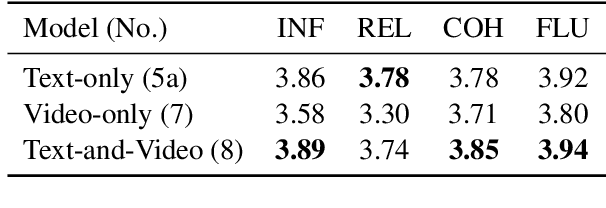
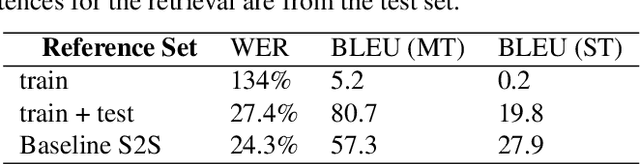
In this paper, we study abstractive summarization for open-domain videos. Unlike the traditional text news summarization, the goal is less to "compress" text information but rather to provide a fluent textual summary of information that has been collected and fused from different source modalities, in our case video and audio transcripts (or text). We show how a multi-source sequence-to-sequence model with hierarchical attention can integrate information from different modalities into a coherent output, compare various models trained with different modalities and present pilot experiments on the How2 corpus of instructional videos. We also propose a new evaluation metric (Content F1) for abstractive summarization task that measures semantic adequacy rather than fluency of the summaries, which is covered by metrics like ROUGE and BLEU.
Learned In Speech Recognition: Contextual Acoustic Word Embeddings
Feb 18, 2019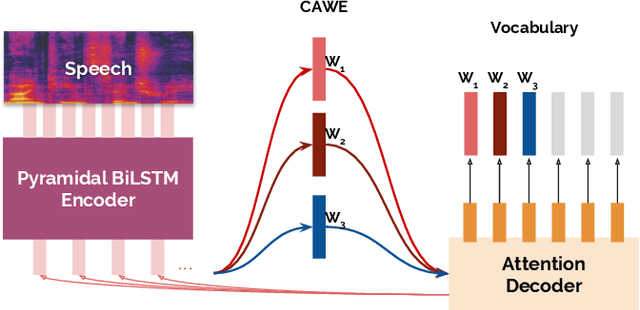
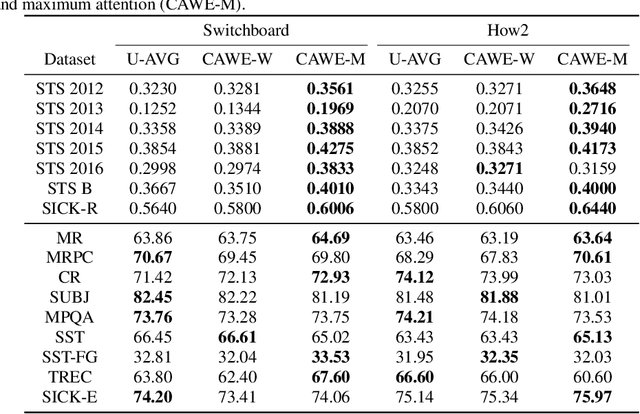
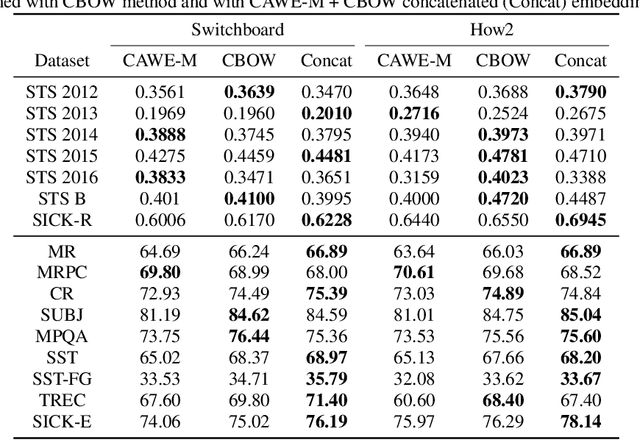

End-to-end acoustic-to-word speech recognition models have recently gained popularity because they are easy to train, scale well to large amounts of training data, and do not require a lexicon. In addition, word models may also be easier to integrate with downstream tasks such as spoken language understanding, because inference (search) is much simplified compared to phoneme, character or any other sort of sub-word units. In this paper, we describe methods to construct contextual acoustic word embeddings directly from a supervised sequence-to-sequence acoustic-to-word speech recognition model using the learned attention distribution. On a suite of 16 standard sentence evaluation tasks, our embeddings show competitive performance against a word2vec model trained on the speech transcriptions. In addition, we evaluate these embeddings on a spoken language understanding task, and observe that our embeddings match the performance of text-based embeddings in a pipeline of first performing speech recognition and then constructing word embeddings from transcriptions.
Learning from Multiview Correlations in Open-Domain Videos
Nov 21, 2018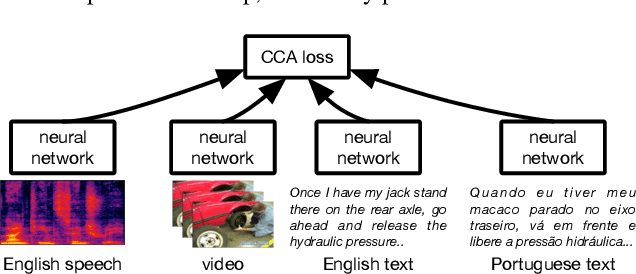
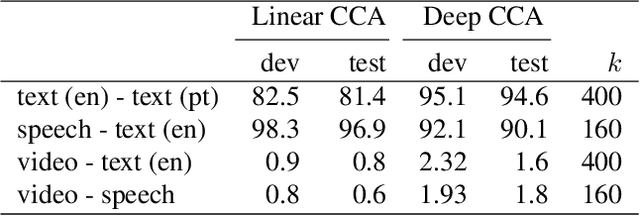
An increasing number of datasets contain multiple views, such as video, sound and automatic captions. A basic challenge in representation learning is how to leverage multiple views to learn better representations. This is further complicated by the existence of a latent alignment between views, such as between speech and its transcription, and by the multitude of choices for the learning objective. We explore an advanced, correlation-based representation learning method on a 4-way parallel, multimodal dataset, and assess the quality of the learned representations on retrieval-based tasks. We show that the proposed approach produces rich representations that capture most of the information shared across views. Our best models for speech and textual modalities achieve retrieval rates from 70.7% to 96.9% on open-domain, user-generated instructional videos. This shows it is possible to learn reliable representations across disparate, unaligned and noisy modalities, and encourages using the proposed approach on larger datasets.
Multimodal Grounding for Sequence-to-Sequence Speech Recognition
Nov 09, 2018
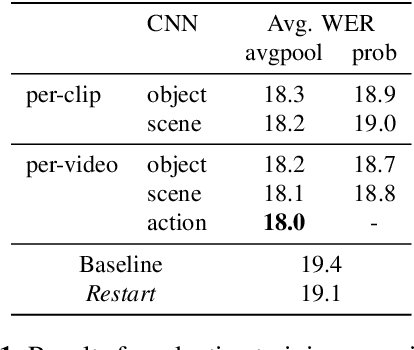
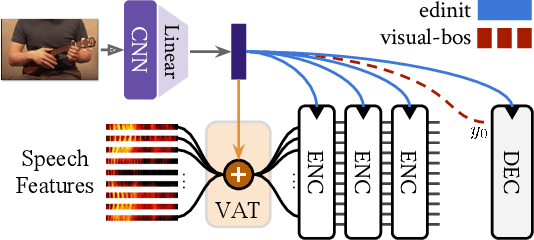
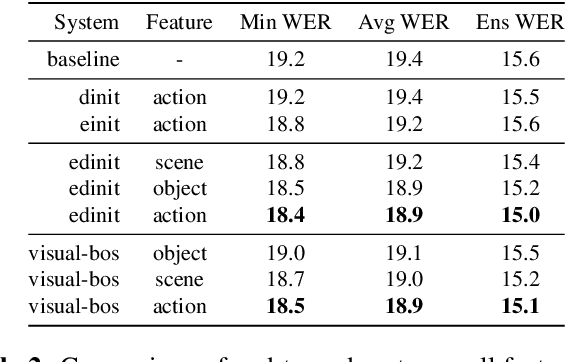
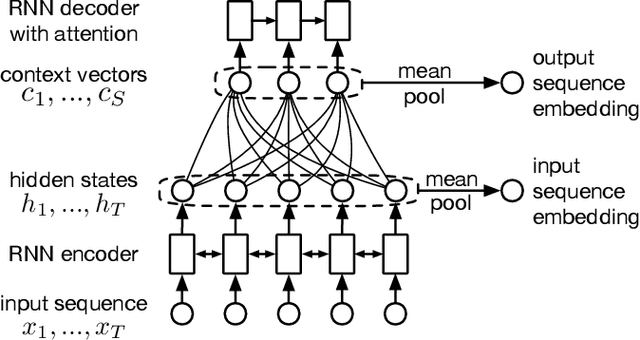
Humans are capable of processing speech by making use of multiple sensory modalities. For example, the environment where a conversation takes place generally provides semantic and/or acoustic context that helps us to resolve ambiguities or to recall named entities. Motivated by this, there have been many works studying the integration of visual information into the speech recognition pipeline. Specifically, in our previous work, we propose a multistep visual adaptive training approach which improves the accuracy of an audio-based Automatic Speech Recognition (ASR) system. This approach, however, is not end-to-end as it requires fine-tuning the whole model with an adaptation layer. In this paper, we propose novel end-to-end multimodal ASR systems and compare them to the adaptive approach by using a range of visual representations obtained from state-of-the-art convolutional neural networks. We show that adaptive training is effective for S2S models leading to an absolute improvement of 1.4% in word error rate. As for the end-to-end systems, although they perform better than baseline, the improvements are slightly less than adaptive training, 0.8 absolute WER reduction in single-best models. Using ensemble decoding, end-to-end models reach a WER of 15% which is the lowest score among all systems.
How2: A Large-scale Dataset for Multimodal Language Understanding
Nov 01, 2018
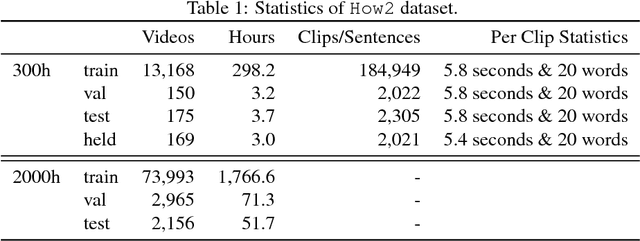
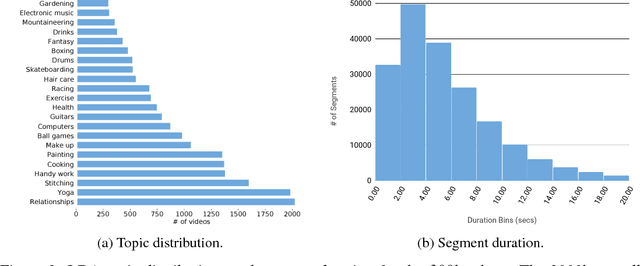

In this paper, we introduce How2, a multimodal collection of instructional videos with English subtitles and crowdsourced Portuguese translations. We also present integrated sequence-to-sequence baselines for machine translation, automatic speech recognition, spoken language translation, and multimodal summarization. By making available data and code for several multimodal natural language tasks, we hope to stimulate more research on these and similar challenges, to obtain a deeper understanding of multimodality in language processing.