 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASR Error Detection via Audio-Transcript entailment
Jul 22, 2022

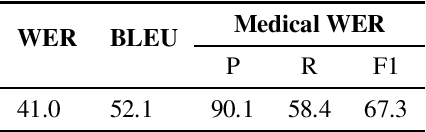
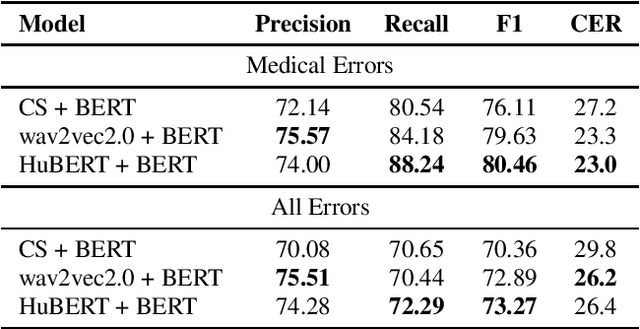
Despite improved performances of the latest Automatic Speech Recognition (ASR) systems, transcription errors are still unavoidable. These errors can have a considerable impact in critical domains such as healthcare, when used to help with clinical documentation. Therefore, detecting ASR errors is a critical first step in preventing further error propagation to downstream applications. To this end, we propose a novel end-to-end approach for ASR error detection using audio-transcript entailment. To the best of our knowledge, we are the first to frame this problem as an end-to-end entailment task between the audio segment and its corresponding transcript segment. Our intuition is that there should be a bidirectional entailment between audio and transcript when there is no recognition error and vice versa. The proposed model utilizes an acoustic encoder and a linguistic encoder to model the speech and transcript respectively. The encoded representations of both modalities are fused to predict the entailment. Since doctor-patient conversations are used in our experiments, a particular emphasis is placed on medical terms. Our proposed model achieves classification error rates (CER) of 26.2% on all transcription errors and 23% on medical errors specifically, leading to improvements upon a strong baseline by 12% and 15.4%, respectively.
ASR Error Correction and Domain Adaptation Using Machine Translation
Mar 13, 2020
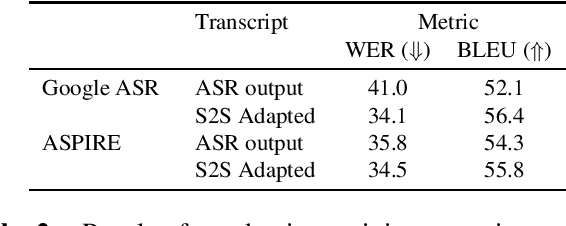
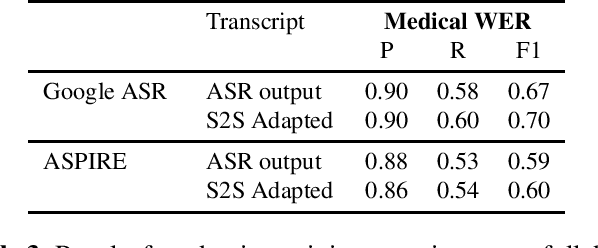

Off-the-shelf pre-trained Automatic Speech Recognition (ASR) systems are an increasingly viable service for companies of any size building speech-based products. While these ASR systems are trained on large amounts of data, domain mismatch is still an issue for many such parties that want to use this service as-is leading to not so optimal results for their task. We propose a simple technique to perform domain adaptation for ASR error correction via machine translation. The machine translation model is a strong candidate to learn a mapping from out-of-domain ASR errors to in-domain terms in the corresponding reference files. We use two off-the-shelf ASR systems in this work: Google ASR (commercial) and the ASPIRE model (open-source). We observe 7% absolute improvement in word error rate and 4 point absolute improvement in BLEU score in Google ASR output via our proposed method. We also evaluate ASR error correction via a downstream task of Speaker Diarization that captures speaker style, syntax, structure and semantic improvements we obtain via ASR correction.