 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerTok: Expressive Encoding and Modeling of Symbolic Musical Ideas and Variations
Oct 02, 2024



We introduce Cadenza, a new multi-stage generative framework for predicting expressive variations of symbolic musical ideas as well as unconditional generations. To accomplish this we propose a novel MIDI encoding method, PerTok (Performance Tokenizer) that captures minute expressive details whilst reducing sequence length up to 59% and vocabulary size up to 95% for polyphonic, monophonic and rhythmic tasks. The proposed framework comprises of two sequential stages: 1) Composer and 2) Performer. The Composer model is a transformer-based Variational Autoencoder (VAE), with Rotary Positional Embeddings (RoPE)ROPE and an autoregressive decoder modified to more effectively integrate the latent codes of the input musical idea. The Performer model is a bidirectional transformer encoder that is separately trained to predict velocities and microtimings on MIDI sequences. Objective and human evaluations demonstrate Cadenza's versatile capability in 1) matching other unconditional state-of-the-art symbolic models in musical quality whilst sounding more expressive, and 2) composing new, expressive ideas that are both stylistically related to the input whilst providing novel ideas to the user. Our framework is designed, researched and implemented with the objective of ethically providing inspiration for musicians.
ASR Error Correction and Domain Adaptation Using Machine Translation
Mar 13, 2020
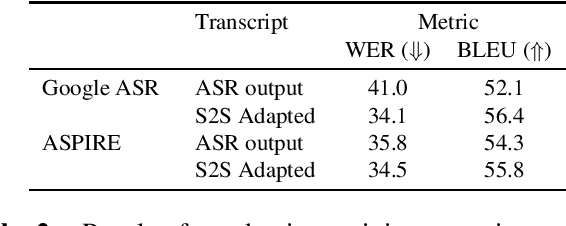
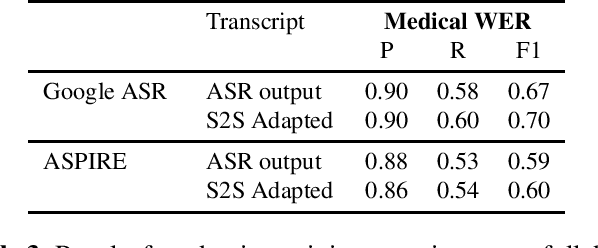

Off-the-shelf pre-trained Automatic Speech Recognition (ASR) systems are an increasingly viable service for companies of any size building speech-based products. While these ASR systems are trained on large amounts of data, domain mismatch is still an issue for many such parties that want to use this service as-is leading to not so optimal results for their task. We propose a simple technique to perform domain adaptation for ASR error correction via machine translation. The machine translation model is a strong candidate to learn a mapping from out-of-domain ASR errors to in-domain terms in the corresponding reference files. We use two off-the-shelf ASR systems in this work: Google ASR (commercial) and the ASPIRE model (open-source). We observe 7% absolute improvement in word error rate and 4 point absolute improvement in BLEU score in Google ASR output via our proposed method. We also evaluate ASR error correction via a downstream task of Speaker Diarization that captures speaker style, syntax, structure and semantic improvements we obtain via ASR correction.