 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Advances in Text Generation from Images Beyond Captioning: A Case Study in Self-Rationalization
May 24, 2022


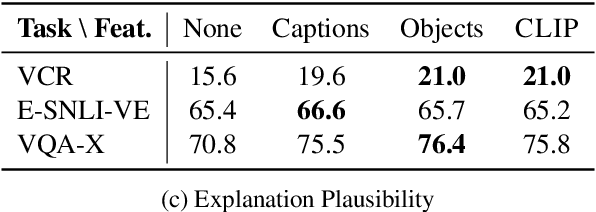
Integrating vision and language has gained notable attention following the success of pretrained language models. Despite that, a fraction of emerging multimodal models is suitable for text generation conditioned on images. This minority is typically developed and evaluated for image captioning, a text generation task conditioned solely on images with the goal to describe what is explicitly visible in an image. In this paper, we take a step back and ask: How do these models work for more complex generative tasks, conditioned on both text and images? Are models based on joint multimodal pretraining, visually adapted pretrained language models, or models that combine these two approaches, more promising for such tasks? We address these questions in the context of self-rationalization (jointly generating task labels/answers and free-text explanations) of three tasks: (i) visual question answering in VQA-X, (ii) visual commonsense reasoning in VCR, and (iii) visual-textual entailment in E-SNLI-VE. We show that recent advances in each modality, CLIP image representations and scaling of language models, do not consistently improve multimodal self-rationalization of tasks with multimodal inputs. We also observe that no model type works universally the best across tasks/datasets and finetuning data sizes. Our findings call for a backbone modelling approach that can be built on to advance text generation from images and text beyond image captioning.
Documenting the English Colossal Clean Crawled Corpus
Apr 18, 2021

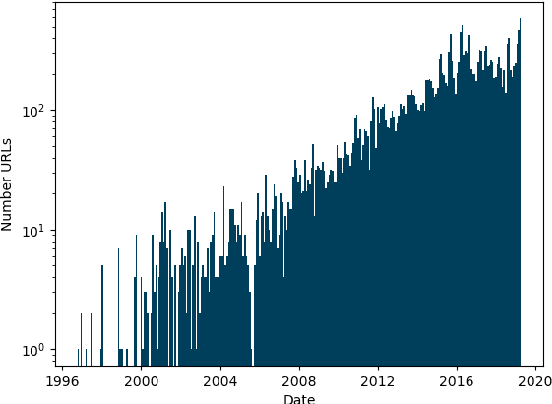

As language models are trained on ever more text, researchers are turning to some of the largest corpora available. Unlike most other types of datasets in NLP, large unlabeled text corpora are often presented with minimal documentation, and best practices for documenting them have not been established. In this work we provide the first documentation for the Colossal Clean Crawled Corpus (C4; Raffel et al., 2020), a dataset created by applying a set of filters to a single snapshot of Common Crawl. We begin with a high-level summary of the data, including distributions of where the text came from and when it was written. We then give more detailed analysis on salient parts of this data, including the most frequent sources of text (e.g., patents.google.com, which contains a significant percentage of machine translated and/or OCR'd text), the effect that the filters had on the data (they disproportionately remove text in AAE), and evidence that some other benchmark NLP dataset examples are contained in the text. We release a web interface to an interactive, indexed copy of this dataset, encouraging the community to continuously explore and report additional findings.
Measuring Association Between Labels and Free-Text Rationales
Oct 24, 2020



Interpretable NLP has taking increasing interest in ensuring that explanations are faithful to the model's decision-making process. This property is crucial for machine learning researchers and practitioners using explanations to better understand models. While prior work focuses primarily on extractive rationales (a subset of the input elements), we investigate their less-studied counterpart: free-text natural language rationales. We demonstrate that existing models for faithful interpretability do not extend cleanly to tasks where free-text rationales are needed. We turn to models that jointly predict and rationalize, a common class of models for free-text rationalization whose faithfulness is not yet established. We propose measurements of label-rationale association, a necessary property of faithful rationales, for these models. Using our measurements, we show that a state-of-the-art joint model based on T5 has strengths and weaknesses for producing faithful rationales.