 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Grounding for Sequence-to-Sequence Speech Recognition
Paper and Code

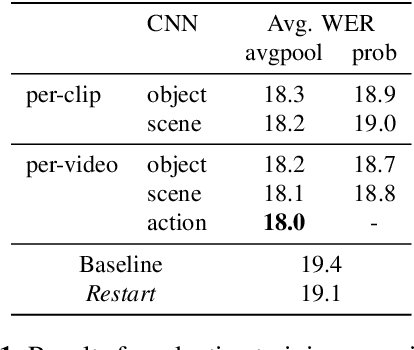
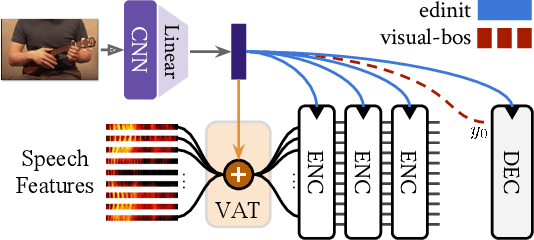
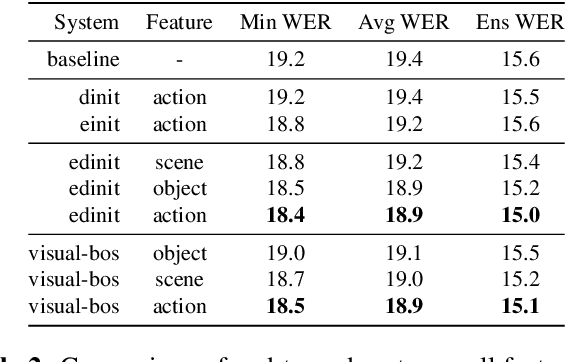
Humans are capable of processing speech by making use of multiple sensory modalities. For example, the environment where a conversation takes place generally provides semantic and/or acoustic context that helps us to resolve ambiguities or to recall named entities. Motivated by this, there have been many works studying the integration of visual information into the speech recognition pipeline. Specifically, in our previous work, we propose a multistep visual adaptive training approach which improves the accuracy of an audio-based Automatic Speech Recognition (ASR) system. This approach, however, is not end-to-end as it requires fine-tuning the whole model with an adaptation layer. In this paper, we propose novel end-to-end multimodal ASR systems and compare them to the adaptive approach by using a range of visual representations obtained from state-of-the-art convolutional neural networks. We show that adaptive training is effective for S2S models leading to an absolute improvement of 1.4% in word error rate. As for the end-to-end systems, although they perform better than baseline, the improvements are slightly less than adaptive training, 0.8 absolute WER reduction in single-best models. Using ensemble decoding, end-to-end models reach a WER of 15% which is the lowest score among all systems.