 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Object Networks: Image Generation with Disentangled 3D Representation
Paper and Code
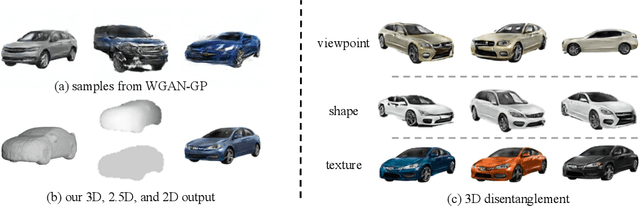
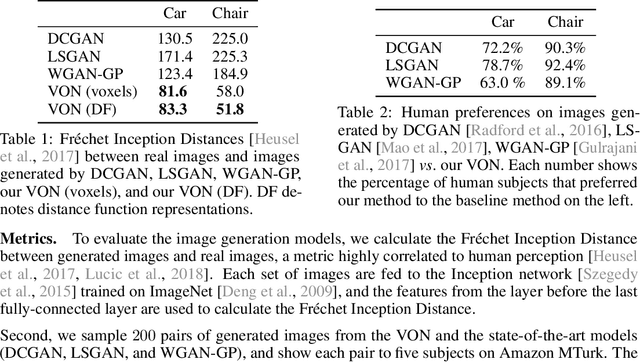
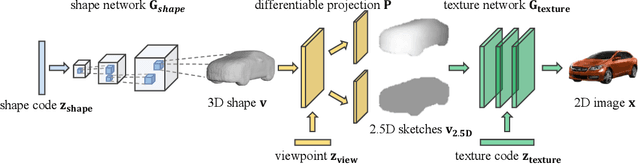

Recent progress in deep generative models has led to tremendous breakthroughs in image generation. However, while existing models can synthesize photorealistic images, they lack an understanding of our underlying 3D world. We present a new generative model, Visual Object Networks (VON), synthesizing natural images of objects with a disentangled 3D representation. Inspired by classic graphics rendering pipelines, we unravel our image formation process into three conditionally independent factors---shape, viewpoint, and texture---and present an end-to-end adversarial learning framework that jointly models 3D shapes and 2D images. Our model first learns to synthesize 3D shapes that are indistinguishable from real shapes. It then renders the object's 2.5D sketches (i.e., silhouette and depth map) from its shape under a sampled viewpoint. Finally, it learns to add realistic texture to these 2.5D sketches to generate natural images. The VON not only generates images that are more realistic than state-of-the-art 2D image synthesis methods, but also enables many 3D operations such as changing the viewpoint of a generated image, editing of shape and texture, linear interpolation in texture and shape space, and transferring appearance across different objects and viewpoints.