 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnbiased estimators for the variance of MMD estimators
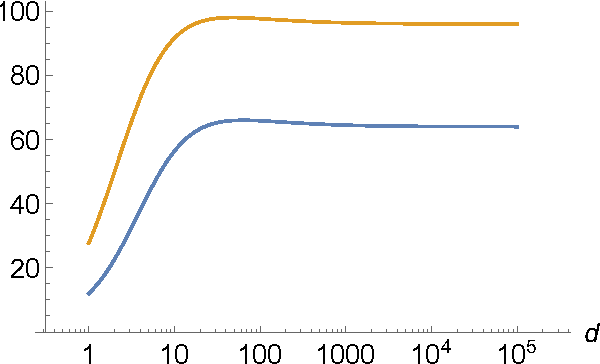
Jun 05, 2019The maximum mean discrepancy (MMD) is a kernel-based distance between probability distributions useful in many applications (Gretton et al. 2012), bearing a simple estimator with pleasing computational and statistical properties. Being able to efficiently estimate the variance of this estimator is very helpful to various problems in two-sample testing. Towards this end, Bounliphone et al. (2016) used the theory of U-statistics to derive estimators for the variance of an MMD estimator, and differences between two such estimators. Their estimator, however, drops lower-order terms, and is unnecessarily biased. We show in this note - extending and correcting work of Sutherland et al. (2017) - that we can find a truly unbiased estimator for the actual variance of both the squared MMD estimator and the difference of two correlated squared MMD estimators, at essentially no additional computational cost.
On gradient regularizers for MMD GANs
Oct 27, 2018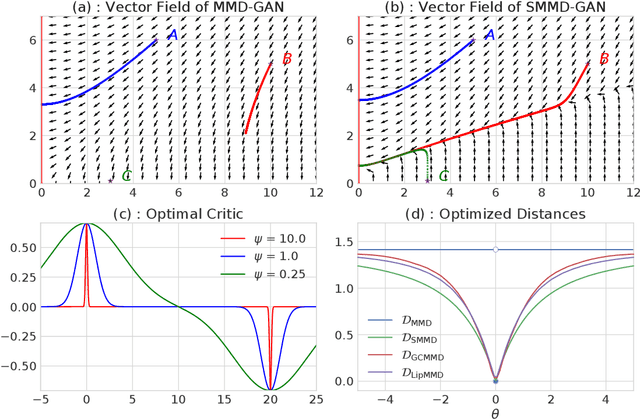

We propose a principled method for gradient-based regularization of the critic of GAN-like models trained by adversarially optimizing the kernel of a Maximum Mean Discrepancy (MMD). We show that controlling the gradient of the critic is vital to having a sensible loss function, and devise a method to enforce exact, analytical gradient constraints at no additional cost compared to existing approximate techniques based on additive regularizers. The new loss function is provably continuous, and experiments show that it stabilizes and accelerates training, giving image generation models that outperform state-of-the art methods on $160 \times 160$ CelebA and $64 \times 64$ unconditional ImageNet.
Demystifying MMD GANs
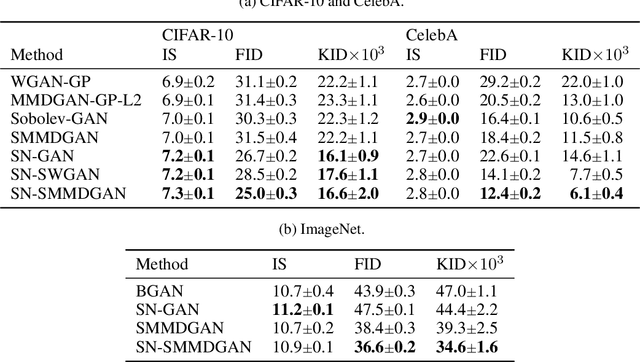
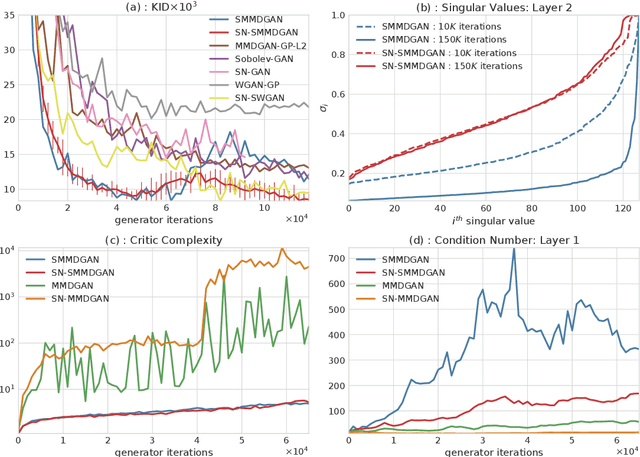
Mar 21, 2018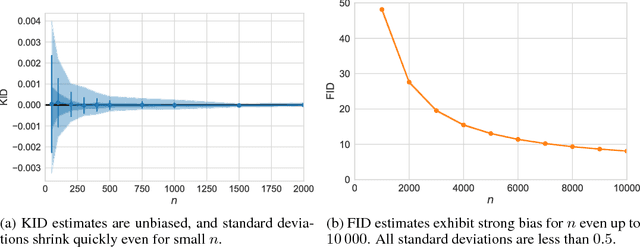
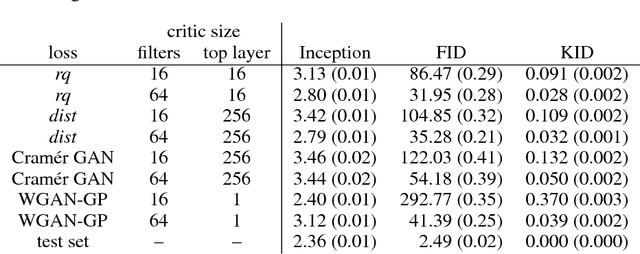
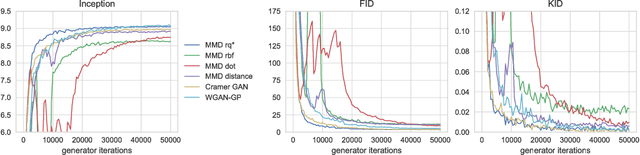

We investigate the training and performance of generative adversarial networks using the Maximum Mean Discrepancy (MMD) as critic, termed MMD GANs. As our main theoretical contribution, we clarify the situation with bias in GAN loss functions raised by recent work: we show that gradient estimators used in the optimization process for both MMD GANs and Wasserstein GANs are unbiased, but learning a discriminator based on samples leads to biased gradients for the generator parameters. We also discuss the issue of kernel choice for the MMD critic, and characterize the kernel corresponding to the energy distance used for the Cramer GAN critic. Being an integral probability metric, the MMD benefits from training strategies recently developed for Wasserstein GANs. In experiments, the MMD GAN is able to employ a smaller critic network than the Wasserstein GAN, resulting in a simpler and faster-training algorithm with matching performance. We also propose an improved measure of GAN convergence, the Kernel Inception Distance, and show how to use it to dynamically adapt learning rates during GAN training.
Efficient and principled score estimation with Nyström kernel exponential families
Mar 13, 2018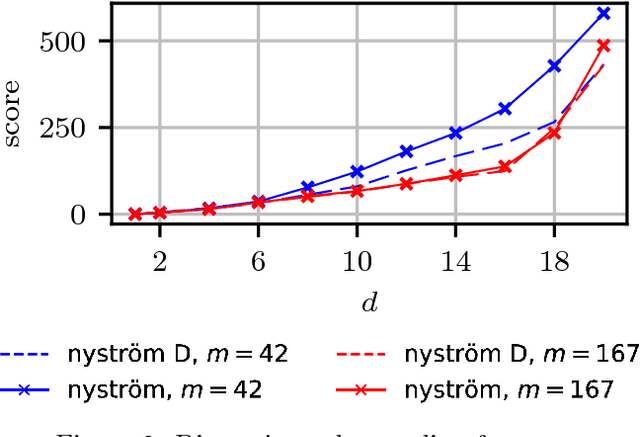

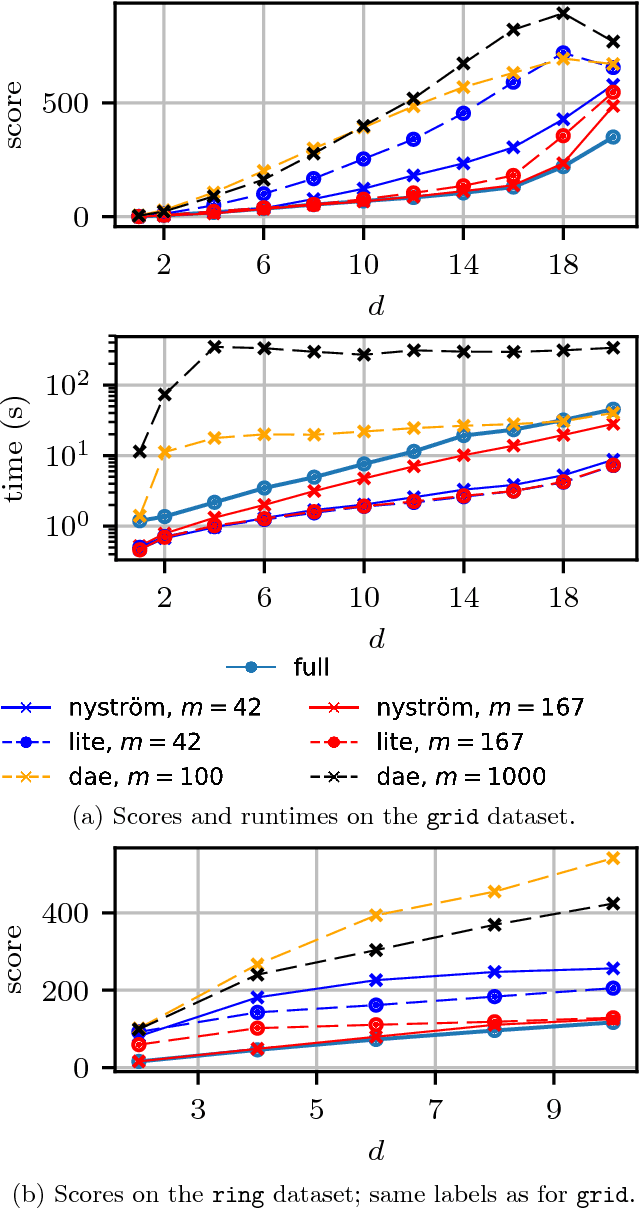
We propose a fast method with statistical guarantees for learning an exponential family density model where the natural parameter is in a reproducing kernel Hilbert space, and may be infinite-dimensional. The model is learned by fitting the derivative of the log density, the score, thus avoiding the need to compute a normalization constant. Our approach improves the computational efficiency of an earlier solution by using a low-rank, Nystr\"om-like solution. The new solution retains the consistency and convergence rates of the full-rank solution (exactly in Fisher distance, and nearly in other distances), with guarantees on the degree of cost and storage reduction. We evaluate the method in experiments on density estimation and in the construction of an adaptive Hamiltonian Monte Carlo sampler. Compared to an existing score learning approach using a denoising autoencoder, our estimator is empirically more data-efficient when estimating the score, runs faster, and has fewer parameters (which can be tuned in a principled and interpretable way), in addition to providing statistical guarantees.
Bayesian Approaches to Distribution Regression
Feb 22, 2018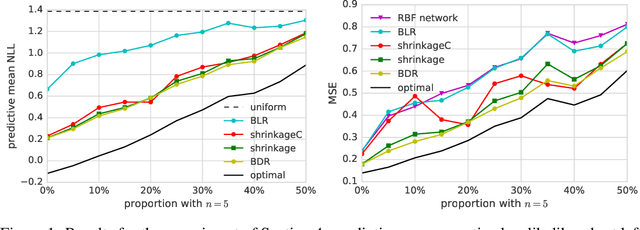
Distribution regression has recently attracted much interest as a generic solution to the problem of supervised learning where labels are available at the group level, rather than at the individual level. Current approaches, however, do not propagate the uncertainty in observations due to sampling variability in the groups. This effectively assumes that small and large groups are estimated equally well, and should have equal weight in the final regression. We account for this uncertainty with a Bayesian distribution regression formalism, improving the robustness and performance of the model when group sizes vary. We frame our models in a neural network style, allowing for simple MAP inference using backpropagation to learn the parameters, as well as MCMC-based inference which can fully propagate uncertainty. We demonstrate our approach on illustrative toy datasets, as well as on a challenging problem of predicting age from images.
Generative Models and Model Criticism via Optimized Maximum Mean Discrepancy
Feb 10, 2017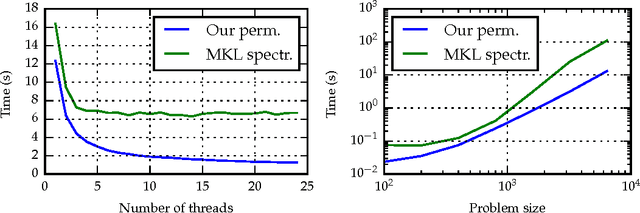
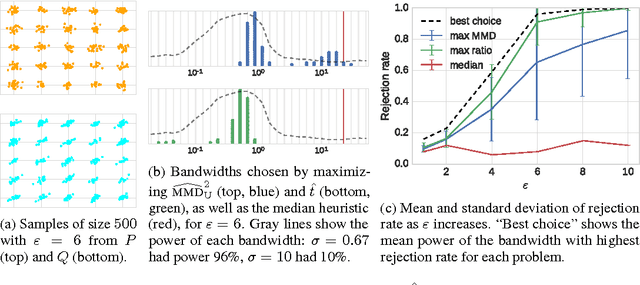
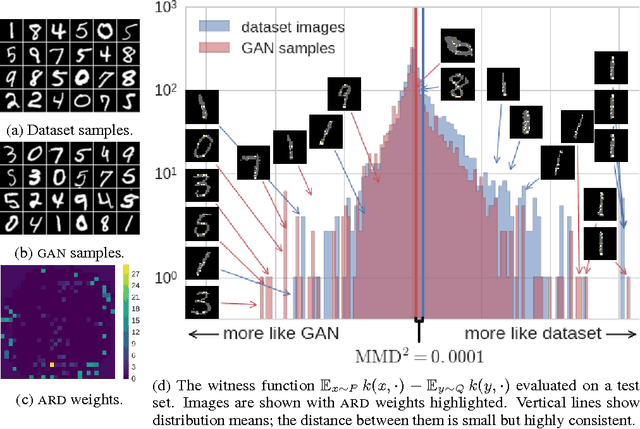

We propose a method to optimize the representation and distinguishability of samples from two probability distributions, by maximizing the estimated power of a statistical test based on the maximum mean discrepancy (MMD). This optimized MMD is applied to the setting of unsupervised learning by generative adversarial networks (GAN), in which a model attempts to generate realistic samples, and a discriminator attempts to tell these apart from data samples. In this context, the MMD may be used in two roles: first, as a discriminator, either directly on the samples, or on features of the samples. Second, the MMD can be used to evaluate the performance of a generative model, by testing the model's samples against a reference data set. In the latter role, the optimized MMD is particularly helpful, as it gives an interpretable indication of how the model and data distributions differ, even in cases where individual model samples are not easily distinguished either by eye or by classifier.
Fixing an error in Caponnetto and de Vito
Feb 09, 2017The seminal paper of Caponnetto and de Vito (2007) provides minimax-optimal rates for kernel ridge regression in a very general setting. Its proof, however, contains an error in its bound on the effective dimensionality. In this note, we explain the mistake, provide a correct bound, and show that the main theorem remains true.
Deep Mean Maps
Nov 13, 2015The use of distributions and high-level features from deep architecture has become commonplace in modern computer vision. Both of these methodologies have separately achieved a great deal of success in many computer vision tasks. However, there has been little work attempting to leverage the power of these to methodologies jointly. To this end, this paper presents the Deep Mean Maps (DMMs) framework, a novel family of methods to non-parametrically represent distributions of features in convolutional neural network models. DMMs are able to both classify images using the distribution of top-level features, and to tune the top-level features for performing this task. We show how to implement DMMs using a special mean map layer composed of typical CNN operations, making both forward and backward propagation simple. We illustrate the efficacy of DMMs at analyzing distributional patterns in image data in a synthetic data experiment. We also show that we extending existing deep architectures with DMMs improves the performance of existing CNNs on several challenging real-world datasets.
Linear-time Learning on Distributions with Approximate Kernel Embeddings
Sep 24, 2015
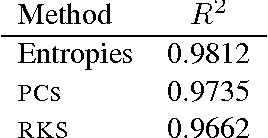
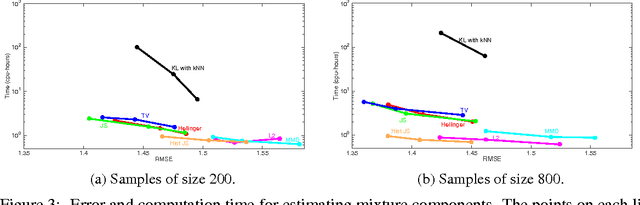
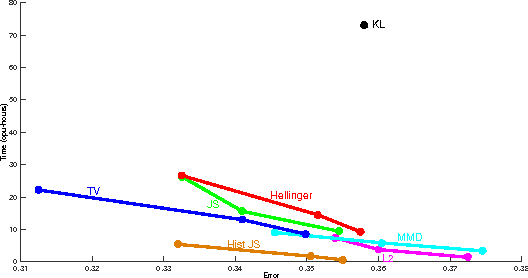
Many interesting machine learning problems are best posed by considering instances that are distributions, or sample sets drawn from distributions. Previous work devoted to machine learning tasks with distributional inputs has done so through pairwise kernel evaluations between pdfs (or sample sets). While such an approach is fine for smaller datasets, the computation of an $N \times N$ Gram matrix is prohibitive in large datasets. Recent scalable estimators that work over pdfs have done so only with kernels that use Euclidean metrics, like the $L_2$ distance. However, there are a myriad of other useful metrics available, such as total variation, Hellinger distance, and the Jensen-Shannon divergence. This work develops the first random features for pdfs whose dot product approximates kernels using these non-Euclidean metrics, allowing estimators using such kernels to scale to large datasets by working in a primal space, without computing large Gram matrices. We provide an analysis of the approximation error in using our proposed random features and show empirically the quality of our approximation both in estimating a Gram matrix and in solving learning tasks in real-world and synthetic data.
On the Error of Random Fourier Features
Jun 09, 2015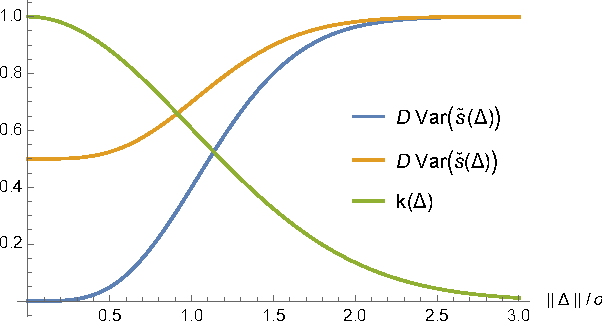
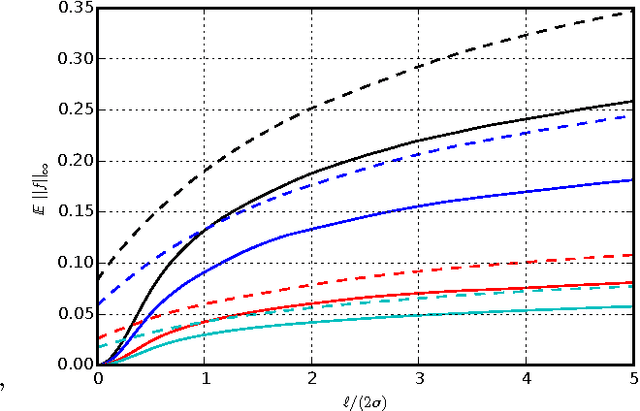
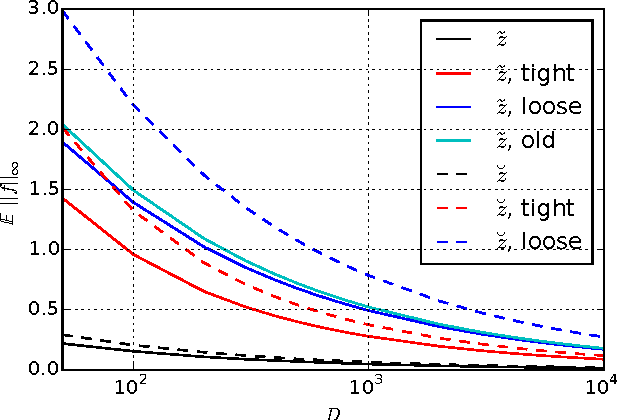
Kernel methods give powerful, flexible, and theoretically grounded approaches to solving many problems in machine learning. The standard approach, however, requires pairwise evaluations of a kernel function, which can lead to scalability issues for very large datasets. Rahimi and Recht (2007) suggested a popular approach to handling this problem, known as random Fourier features. The quality of this approximation, however, is not well understood. We improve the uniform error bound of that paper, as well as giving novel understandings of the embedding's variance, approximation error, and use in some machine learning methods. We also point out that surprisingly, of the two main variants of those features, the more widely used is strictly higher-variance for the Gaussian kernel and has worse bounds.