 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAMPLIFY: Actionless Motion Priors for Robot Learning from Videos
Jun 17, 2025Action-labeled data for robotics is scarce and expensive, limiting the generalization of learned policies. In contrast, vast amounts of action-free video data are readily available, but translating these observations into effective policies remains a challenge. We introduce AMPLIFY, a novel framework that leverages large-scale video data by encoding visual dynamics into compact, discrete motion tokens derived from keypoint trajectories. Our modular approach separates visual motion prediction from action inference, decoupling the challenges of learning what motion defines a task from how robots can perform it. We train a forward dynamics model on abundant action-free videos and an inverse dynamics model on a limited set of action-labeled examples, allowing for independent scaling. Extensive evaluations demonstrate that the learned dynamics are both accurate, achieving up to 3.7x better MSE and over 2.5x better pixel prediction accuracy compared to prior approaches, and broadly useful. In downstream policy learning, our dynamics predictions enable a 1.2-2.2x improvement in low-data regimes, a 1.4x average improvement by learning from action-free human videos, and the first generalization to LIBERO tasks from zero in-distribution action data. Beyond robotic control, we find the dynamics learned by AMPLIFY to be a versatile latent world model, enhancing video prediction quality. Our results present a novel paradigm leveraging heterogeneous data sources to build efficient, generalizable world models. More information can be found at https://amplify-robotics.github.io/.
SAIL: Faster-than-Demonstration Execution of Imitation Learning Policies
Jun 13, 2025Offline Imitation Learning (IL) methods such as Behavior Cloning are effective at acquiring complex robotic manipulation skills. However, existing IL-trained policies are confined to executing the task at the same speed as shown in demonstration data. This limits the task throughput of a robotic system, a critical requirement for applications such as industrial automation. In this paper, we introduce and formalize the novel problem of enabling faster-than-demonstration execution of visuomotor policies and identify fundamental challenges in robot dynamics and state-action distribution shifts. We instantiate the key insights as SAIL (Speed Adaptation for Imitation Learning), a full-stack system integrating four tightly-connected components: (1) a consistency-preserving action inference algorithm for smooth motion at high speed, (2) high-fidelity tracking of controller-invariant motion targets, (3) adaptive speed modulation that dynamically adjusts execution speed based on motion complexity, and (4) action scheduling to handle real-world system latencies. Experiments on 12 tasks across simulation and two real, distinct robot platforms show that SAIL achieves up to a 4x speedup over demonstration speed in simulation and up to 3.2x speedup in the real world. Additional detail is available at https://nadunranawaka1.github.io/sail-policy
Adapt3R: Adaptive 3D Scene Representation for Domain Transfer in Imitation Learning
Mar 06, 2025Imitation Learning (IL) has been very effective in training robots to perform complex and diverse manipulation tasks. However, its performance declines precipitously when the observations are out of the training distribution. 3D scene representations that incorporate observations from calibrated RGBD cameras have been proposed as a way to improve generalizability of IL policies, but our evaluations in cross-embodiment and novel camera pose settings found that they show only modest improvement. To address those challenges, we propose Adaptive 3D Scene Representation (Adapt3R), a general-purpose 3D observation encoder which uses a novel architecture to synthesize data from one or more RGBD cameras into a single vector that can then be used as conditioning for arbitrary IL algorithms. The key idea is to use a pretrained 2D backbone to extract semantic information about the scene, using 3D only as a medium for localizing this semantic information with respect to the end-effector. We show that when trained end-to-end with several SOTA multi-task IL algorithms, Adapt3R maintains these algorithms' multi-task learning capacity while enabling zero-shot transfer to novel embodiments and camera poses. Furthermore, we provide a detailed suite of ablation and sensitivity experiments to elucidate the design space for point cloud observation encoders.
Canonical mapping as a general-purpose object descriptor for robotic manipulation
Mar 02, 2023Perception is an essential part of robotic manipulation in a semi-structured environment. Traditional approaches produce a narrow task-specific prediction (e.g., object's 6D pose), that cannot be adapted to other tasks and is ill-suited for deformable objects. In this paper, we propose using canonical mapping as a near-universal and flexible object descriptor. We demonstrate that common object representations can be derived from a single pre-trained canonical mapping model, which in turn can be generated with minimal manual effort using an automated data generation and training pipeline. We perform a multi-stage experiment using two robot arms that demonstrate the robustness of the perception approach and the ways it can inform the manipulation strategy, thus serving as a powerful foundation for general-purpose robotic manipulation.
Pose estimation and bin picking for deformable products
Nov 12, 2019

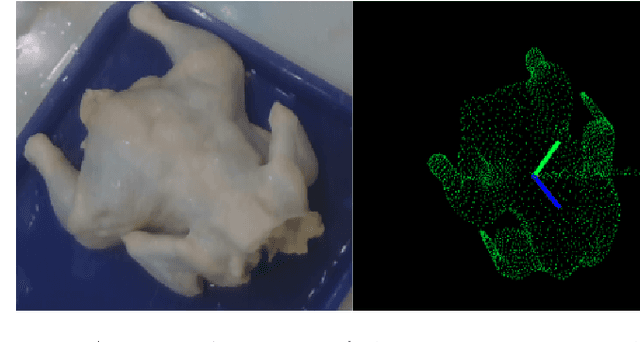

Robotic systems in manufacturing applications commonly assume known object geometry and appearance. This simplifies the task for the 3D perception algorithms and allows the manipulation to be more deterministic. However, those approaches are not easily transferable to the agricultural and food domains due to the variability and deformability of natural food. We demonstrate an approach applied to poultry products that allows picking up a whole chicken from an unordered bin using a suction cup gripper, estimating its pose using a Deep Learning approach, and placing it in a canonical orientation where it can be further processed. Our robotic system was experimentally evaluated and is able to generalize to object variations and achieves high accuracy on bin picking and pose estimation tasks in a real-world environment.