 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmart Surrogate Losses for Contextual Stochastic Linear Optimization with Robust Constraints
May 28, 2025We study an extension of contextual stochastic linear optimization (CSLO) that, in contrast to most of the existing literature, involves inequality constraints that depend on uncertain parameters predicted by a machine learning model. To handle the constraint uncertainty, we use contextual uncertainty sets constructed via methods like conformal prediction. Given a contextual uncertainty set method, we introduce the "Smart Predict-then-Optimize with Robust Constraints" (SPO-RC) loss, a feasibility-sensitive adaptation of the SPO loss that measures decision error of predicted objective parameters. We also introduce a convex surrogate, SPO-RC+, and prove Fisher consistency with SPO-RC. To enhance performance, we train on truncated datasets where true constraint parameters lie within the uncertainty sets, and we correct the induced sample selection bias using importance reweighting techniques. Through experiments on fractional knapsack and alloy production problem instances, we demonstrate that SPO-RC+ effectively handles uncertainty in constraints and that combining truncation with importance reweighting can further improve performance.
Self-Supervised Penalty-Based Learning for Robust Constrained Optimization
Mar 07, 2025We propose a new methodology for parameterized constrained robust optimization, an important class of optimization problems under uncertainty, based on learning with a self-supervised penalty-based loss function. Whereas supervised learning requires pre-solved instances for training, our approach leverages a custom loss function derived from the exact penalty method in optimization to learn an approximation, typically defined by a neural network model, of the parameterized optimal solution mapping. Additionally, we adapt our approach to robust constrained combinatorial optimization problems by incorporating a surrogate linear cost over mixed integer domains, and a smooth approximations thereof, into the final layer of the network architecture. We perform computational experiments to test our approach on three different applications: multidimensional knapsack with continuous variables, combinatorial multidimensional knapsack with discrete variables, and an inventory management problem. Our results demonstrate that our self-supervised approach is able to effectively learn neural network approximations whose inference time is significantly smaller than the computation time of traditional solvers for this class of robust optimization problems. Furthermore, our results demonstrate that by varying the penalty parameter we are able to effectively balance the trade-off between sub-optimality and robust feasibility of the obtained solutions.
Monte Carlo Augmented Actor-Critic for Sparse Reward Deep Reinforcement Learning from Suboptimal Demonstrations
Oct 14, 2022

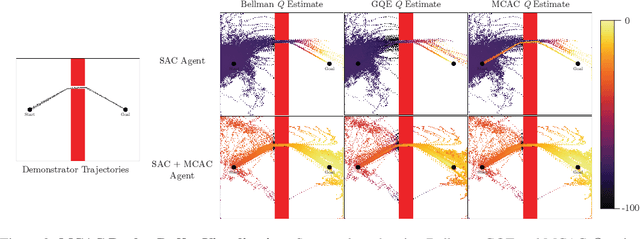

Providing densely shaped reward functions for RL algorithms is often exceedingly challenging, motivating the development of RL algorithms that can learn from easier-to-specify sparse reward functions. This sparsity poses new exploration challenges. One common way to address this problem is using demonstrations to provide initial signal about regions of the state space with high rewards. However, prior RL from demonstrations algorithms introduce significant complexity and many hyperparameters, making them hard to implement and tune. We introduce Monte Carlo Augmented Actor Critic (MCAC), a parameter free modification to standard actor-critic algorithms which initializes the replay buffer with demonstrations and computes a modified $Q$-value by taking the maximum of the standard temporal distance (TD) target and a Monte Carlo estimate of the reward-to-go. This encourages exploration in the neighborhood of high-performing trajectories by encouraging high $Q$-values in corresponding regions of the state space. Experiments across $5$ continuous control domains suggest that MCAC can be used to significantly increase learning efficiency across $6$ commonly used RL and RL-from-demonstrations algorithms. See https://sites.google.com/view/mcac-rl for code and supplementary material.