 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecision-Focused On-Policy Learning for Contextual Linear Optimization with Partial Feedback
May 31, 2026Decision-focused learning (DFL) trains predictive models by optimizing downstream decision quality rather than standalone prediction accuracy. For contextual linear optimization, most existing DFL methods assume offline data and full observations of the objective cost vector. We develop an on-policy learning method for sequential contextual linear optimization under partial feedback, generalizing the standard bandit feedback setting. Our method learns a stochastic predict-then-optimize policy that samples a cost-vector prediction from a conditional distribution and solves the resulting downstream linear optimization problem. To update this distributional model, we introduce a two-component hybrid gradient estimator. The first component is a score function estimator, which provides an unbiased but potentially high-variance policy gradient estimate. The second is a decision-focused plug-in component that uses an auxiliary nuisance estimate of the latent cost vector to exploit the downstream optimization structure, becoming more informative as the estimate improves. We prove an $\mathcal{O}(T^{-1/2})$ bound on the average squared policy-gradient norm, matching the standard non-convex SGD rate. Experiments on top-$k$ selection, shortest path, combinatorial pricing, and a real-data energy-scheduling benchmark show that the hybrid gradient approach achieves lower cumulative regret than contextual-bandit-style baselines across all benchmarks, using both Gaussian and richer conditional generative models. Code is available at https://github.com/Joeyetinghan/on-policy-bandit-dfl.
A Barrier-Metric First-Order Method for Linearly Constrained Bilevel Optimization
May 12, 2026We study bilevel optimization with a fixed polyhedral lower feasible set. Such problems are challenging for two reasons: active-set changes can make the upper objective nonsmooth, and existing hypergradient methods typically require lower-Hessian inversions or equivalent linear solves, which are computationally expensive. To address these issues, we adopt a logarithmic barrier smoothing of the lower problem to obtain a differentiable approximation of the constrained bilevel objective, and develop a proxy-gradient algorithm for the resulting barrier-smoothed surrogate. The algorithm uses only gradients of the upper and lower objectives; its only second-order object is the explicit logarithmic barrier Hessian determined by the fixed polyhedral constraints. Barrier smoothing restores differentiability, but Euclidean smoothness constants are not uniformly bounded near the boundary. We therefore develop a local Dikin-geometry analysis in which the barrier-metric provides an oracle-free curvature scale near the moving lower centers. This leads to barrier-aware schedules that keep the iterates inside locally well-behaved regions. For the barrier-smoothed objective, we prove stationarity rates of $\widetilde{O}(K^{-2/3})$ in the deterministic setting and $\widetilde{O}(K^{-2/5})$ under upper-level-only bounded stochastic noise after $K$ outer iterations, together with quantitative bias control as the barrier parameter decreases.
Decision-Focused Sequential Experimental Design: A Directional Uncertainty-Guided Approach
Feb 05, 2026We consider the sequential experimental design problem in the predict-then-optimize paradigm. In this paradigm, the outputs of the prediction model are used as coefficient vectors in a downstream linear optimization problem. Traditional sequential experimental design aims to control the input variables (features) so that the improvement in prediction accuracy from each experimental outcome (label) is maximized. However, in the predict-then-optimize setting, performance is ultimately evaluated based on the decision loss induced by the downstream optimization, rather than by prediction error. This mismatch between prediction accuracy and decision loss renders traditional decision-blind designs inefficient. To address this issue, we propose a directional-based metric to quantify predictive uncertainty. This metric does not require solving an optimization oracle and is therefore computationally tractable. We show that the resulting sequential design criterion enjoys strong consistency and convergence guarantees. Under a broad class of distributions, we demonstrate that our directional uncertainty-based design attains an earlier stopping time than decision-blind designs. This advantage is further supported by real-world experiments on an LLM job allocation problem.
Smart Surrogate Losses for Contextual Stochastic Linear Optimization with Robust Constraints
May 28, 2025We study an extension of contextual stochastic linear optimization (CSLO) that, in contrast to most of the existing literature, involves inequality constraints that depend on uncertain parameters predicted by a machine learning model. To handle the constraint uncertainty, we use contextual uncertainty sets constructed via methods like conformal prediction. Given a contextual uncertainty set method, we introduce the "Smart Predict-then-Optimize with Robust Constraints" (SPO-RC) loss, a feasibility-sensitive adaptation of the SPO loss that measures decision error of predicted objective parameters. We also introduce a convex surrogate, SPO-RC+, and prove Fisher consistency with SPO-RC. To enhance performance, we train on truncated datasets where true constraint parameters lie within the uncertainty sets, and we correct the induced sample selection bias using importance reweighting techniques. Through experiments on fractional knapsack and alloy production problem instances, we demonstrate that SPO-RC+ effectively handles uncertainty in constraints and that combining truncation with importance reweighting can further improve performance.
Self-Supervised Penalty-Based Learning for Robust Constrained Optimization
Mar 07, 2025We propose a new methodology for parameterized constrained robust optimization, an important class of optimization problems under uncertainty, based on learning with a self-supervised penalty-based loss function. Whereas supervised learning requires pre-solved instances for training, our approach leverages a custom loss function derived from the exact penalty method in optimization to learn an approximation, typically defined by a neural network model, of the parameterized optimal solution mapping. Additionally, we adapt our approach to robust constrained combinatorial optimization problems by incorporating a surrogate linear cost over mixed integer domains, and a smooth approximations thereof, into the final layer of the network architecture. We perform computational experiments to test our approach on three different applications: multidimensional knapsack with continuous variables, combinatorial multidimensional knapsack with discrete variables, and an inventory management problem. Our results demonstrate that our self-supervised approach is able to effectively learn neural network approximations whose inference time is significantly smaller than the computation time of traditional solvers for this class of robust optimization problems. Furthermore, our results demonstrate that by varying the penalty parameter we are able to effectively balance the trade-off between sub-optimality and robust feasibility of the obtained solutions.
Beyond Discretization: Learning the Optimal Solution Path
Oct 18, 2024Many applications require minimizing a family of optimization problems indexed by some hyperparameter $\lambda \in \Lambda$ to obtain an entire solution path. Traditional approaches proceed by discretizing $\Lambda$ and solving a series of optimization problems. We propose an alternative approach that parameterizes the solution path with a set of basis functions and solves a \emph{single} stochastic optimization problem to learn the entire solution path. Our method offers substantial complexity improvements over discretization. When using constant-step size SGD, the uniform error of our learned solution path relative to the true path exhibits linear convergence to a constant related to the expressiveness of the basis. When the true solution path lies in the span of the basis, this constant is zero. We also prove stronger results for special cases common in machine learning: When $\lambda \in [-1, 1]$ and the solution path is $\nu$-times differentiable, constant step-size SGD learns a path with $\epsilon$ uniform error after at most $O(\epsilon^{\frac{1}{1-\nu}} \log(1/\epsilon))$ iterations, and when the solution path is analytic, it only requires $O\left(\log^2(1/\epsilon)\log\log(1/\epsilon)\right)$. By comparison, the best-known discretization schemes in these settings require at least $O(\epsilon^{-1/2})$ discretization points (and even more gradient calls). Finally, we propose an adaptive variant of our method that sequentially adds basis functions and demonstrates strong numerical performance through experiments.
Binary Classification with Instance and Label Dependent Label Noise
Jun 06, 2023Learning with label dependent label noise has been extensively explored in both theory and practice; however, dealing with instance (i.e., feature) and label dependent label noise continues to be a challenging task. The difficulty arises from the fact that the noise rate varies for each instance, making it challenging to estimate accurately. The question of whether it is possible to learn a reliable model using only noisy samples remains unresolved. We answer this question with a theoretical analysis that provides matching upper and lower bounds. Surprisingly, our results show that, without any additional assumptions, empirical risk minimization achieves the optimal excess risk bound. Specifically, we derive a novel excess risk bound proportional to the noise level, which holds in very general settings, by comparing the empirical risk minimizers obtained from clean samples and noisy samples. Second, we show that the minimax lower bound for the 0-1 loss is a constant proportional to the average noise rate. Our findings suggest that learning solely with noisy samples is impossible without access to clean samples or strong assumptions on the distribution of the data.
Active Learning in the Predict-then-Optimize Framework: A Margin-Based Approach
May 11, 2023We develop the first active learning method in the predict-then-optimize framework. Specifically, we develop a learning method that sequentially decides whether to request the "labels" of feature samples from an unlabeled data stream, where the labels correspond to the parameters of an optimization model for decision-making. Our active learning method is the first to be directly informed by the decision error induced by the predicted parameters, which is referred to as the Smart Predict-then-Optimize (SPO) loss. Motivated by the structure of the SPO loss, our algorithm adopts a margin-based criterion utilizing the concept of distance to degeneracy and minimizes a tractable surrogate of the SPO loss on the collected data. In particular, we develop an efficient active learning algorithm with both hard and soft rejection variants, each with theoretical excess risk (i.e., generalization) guarantees. We further derive bounds on the label complexity, which refers to the number of samples whose labels are acquired to achieve a desired small level of SPO risk. Under some natural low-noise conditions, we show that these bounds can be better than the naive supervised learning approach that labels all samples. Furthermore, when using the SPO+ loss function, a specialized surrogate of the SPO loss, we derive a significantly smaller label complexity under separability conditions. We also present numerical evidence showing the practical value of our proposed algorithms in the settings of personalized pricing and the shortest path problem.
Online Contextual Decision-Making with a Smart Predict-then-Optimize Method
Jun 15, 2022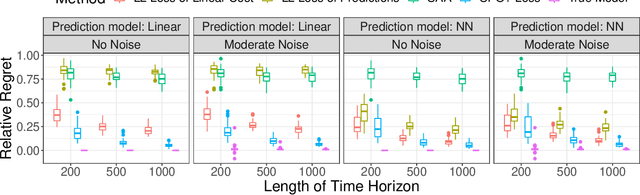
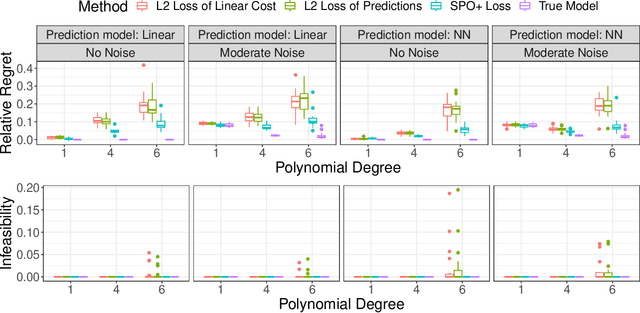
We study an online contextual decision-making problem with resource constraints. At each time period, the decision-maker first predicts a reward vector and resource consumption matrix based on a given context vector and then solves a downstream optimization problem to make a decision. The final goal of the decision-maker is to maximize the summation of the reward and the utility from resource consumption, while satisfying the resource constraints. We propose an algorithm that mixes a prediction step based on the "Smart Predict-then-Optimize (SPO)" method with a dual update step based on mirror descent. We prove regret bounds and demonstrate that the overall convergence rate of our method depends on the $\mathcal{O}(T^{-1/2})$ convergence of online mirror descent as well as risk bounds of the surrogate loss function used to learn the prediction model. Our algorithm and regret bounds apply to a general convex feasible region for the resource constraints, including both hard and soft resource constraint cases, and they apply to a wide class of prediction models in contrast to the traditional settings of linear contextual models or finite policy spaces. We also conduct numerical experiments to empirically demonstrate the strength of our proposed SPO-type methods, as compared to traditional prediction-error-only methods, on multi-dimensional knapsack and longest path instances.
Integrated Conditional Estimation-Optimization
Oct 24, 2021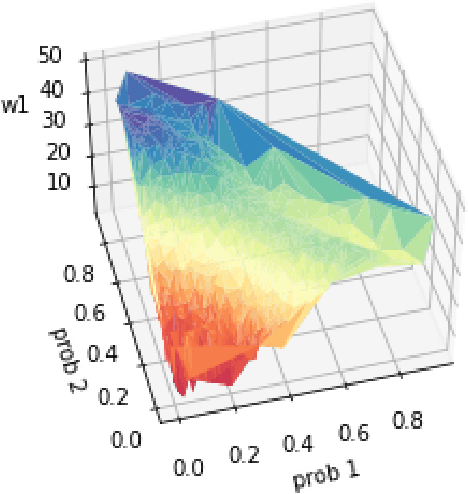
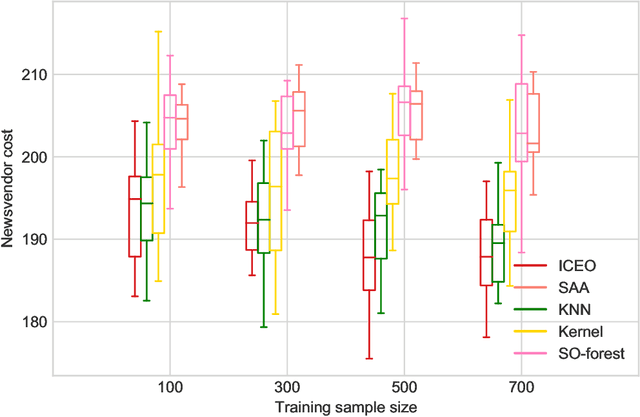
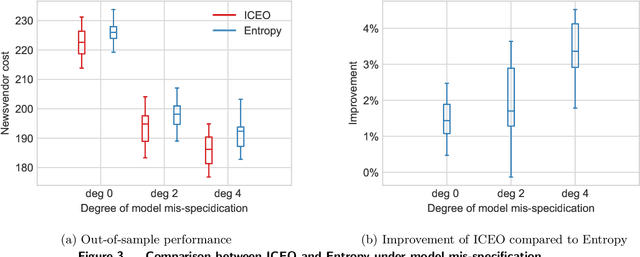
Many real-world optimization problems involve uncertain parameters with probability distributions that can be estimated using contextual feature information. In contrast to the standard approach of first estimating the distribution of uncertain parameters and then optimizing the objective based on the estimation, we propose an integrated conditional estimation-optimization (ICEO) framework that estimates the underlying conditional distribution of the random parameter while considering the structure of the optimization problem. We directly model the relationship between the conditional distribution of the random parameter and the contextual features, and then estimate the probabilistic model with an objective that aligns with the downstream optimization problem. We show that our ICEO approach is asymptotically consistent under moderate regularity conditions and further provide finite performance guarantees in the form of generalization bounds. Computationally, performing estimation with the ICEO approach is a non-convex and often non-differentiable optimization problem. We propose a general methodology for approximating the potentially non-differentiable mapping from estimated conditional distribution to the optimal decision by a differentiable function, which greatly improves the performance of gradient-based algorithms applied to the non-convex problem. We also provide a polynomial optimization solution approach in the semi-algebraic case. Numerical experiments are also conducted to show the empirical success of our approach in different situations including with limited data samples and model mismatches.