 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUAVScenes: A Multi-Modal Dataset for UAVs
Jul 30, 2025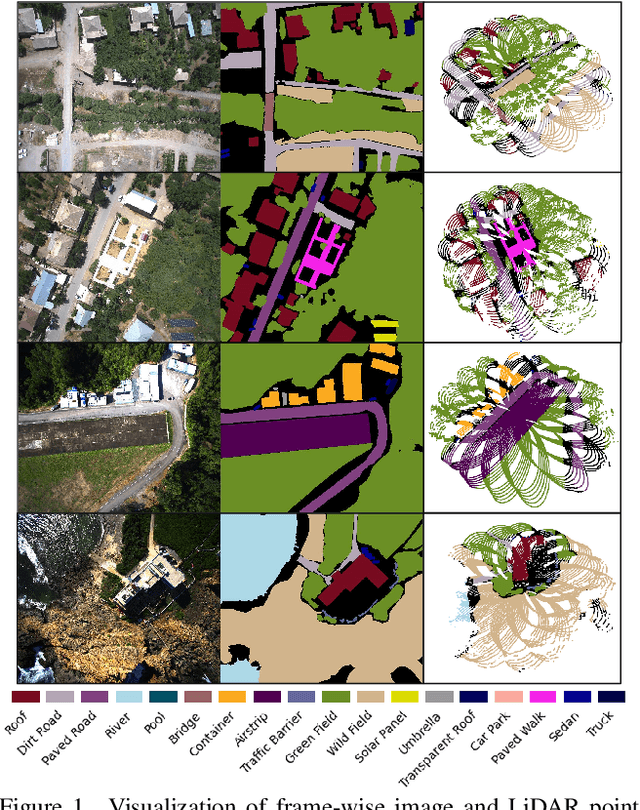
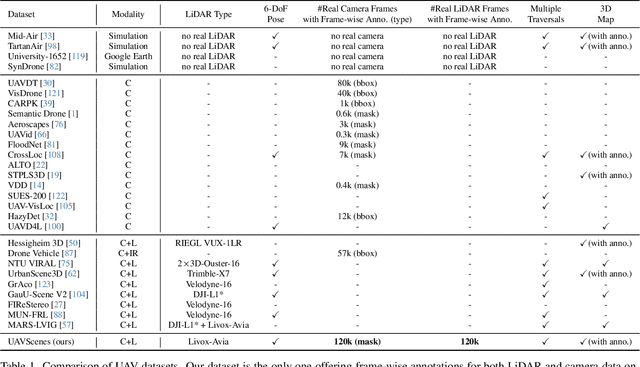
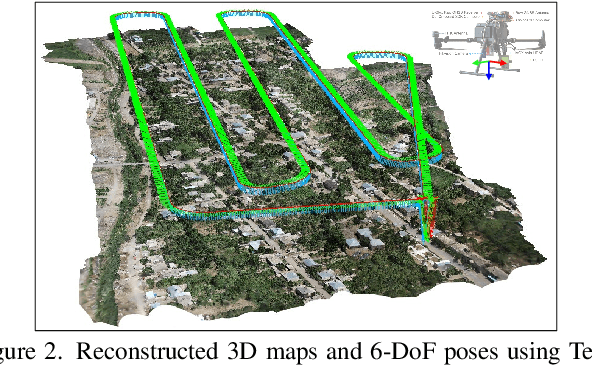
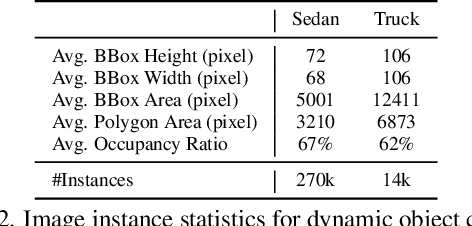
Multi-modal perception is essential for unmanned aerial vehicle (UAV) operations, as it enables a comprehensive understanding of the UAVs' surrounding environment. However, most existing multi-modal UAV datasets are primarily biased toward localization and 3D reconstruction tasks, or only support map-level semantic segmentation due to the lack of frame-wise annotations for both camera images and LiDAR point clouds. This limitation prevents them from being used for high-level scene understanding tasks. To address this gap and advance multi-modal UAV perception, we introduce UAVScenes, a large-scale dataset designed to benchmark various tasks across both 2D and 3D modalities. Our benchmark dataset is built upon the well-calibrated multi-modal UAV dataset MARS-LVIG, originally developed only for simultaneous localization and mapping (SLAM). We enhance this dataset by providing manually labeled semantic annotations for both frame-wise images and LiDAR point clouds, along with accurate 6-degree-of-freedom (6-DoF) poses. These additions enable a wide range of UAV perception tasks, including segmentation, depth estimation, 6-DoF localization, place recognition, and novel view synthesis (NVS). Our dataset is available at https://github.com/sijieaaa/UAVScenes
Active Learning in the Predict-then-Optimize Framework: A Margin-Based Approach
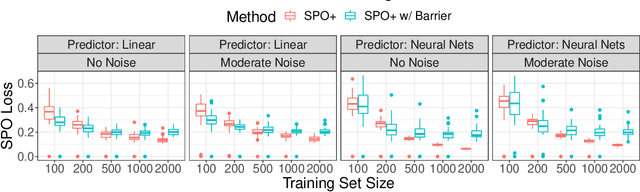
May 11, 2023We develop the first active learning method in the predict-then-optimize framework. Specifically, we develop a learning method that sequentially decides whether to request the "labels" of feature samples from an unlabeled data stream, where the labels correspond to the parameters of an optimization model for decision-making. Our active learning method is the first to be directly informed by the decision error induced by the predicted parameters, which is referred to as the Smart Predict-then-Optimize (SPO) loss. Motivated by the structure of the SPO loss, our algorithm adopts a margin-based criterion utilizing the concept of distance to degeneracy and minimizes a tractable surrogate of the SPO loss on the collected data. In particular, we develop an efficient active learning algorithm with both hard and soft rejection variants, each with theoretical excess risk (i.e., generalization) guarantees. We further derive bounds on the label complexity, which refers to the number of samples whose labels are acquired to achieve a desired small level of SPO risk. Under some natural low-noise conditions, we show that these bounds can be better than the naive supervised learning approach that labels all samples. Furthermore, when using the SPO+ loss function, a specialized surrogate of the SPO loss, we derive a significantly smaller label complexity under separability conditions. We also present numerical evidence showing the practical value of our proposed algorithms in the settings of personalized pricing and the shortest path problem.
Online Contextual Decision-Making with a Smart Predict-then-Optimize Method
Jun 15, 2022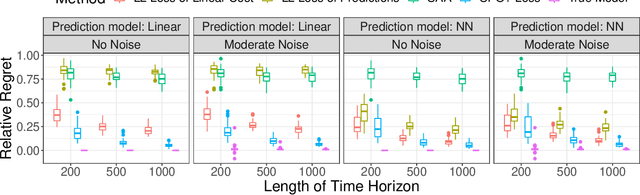
We study an online contextual decision-making problem with resource constraints. At each time period, the decision-maker first predicts a reward vector and resource consumption matrix based on a given context vector and then solves a downstream optimization problem to make a decision. The final goal of the decision-maker is to maximize the summation of the reward and the utility from resource consumption, while satisfying the resource constraints. We propose an algorithm that mixes a prediction step based on the "Smart Predict-then-Optimize (SPO)" method with a dual update step based on mirror descent. We prove regret bounds and demonstrate that the overall convergence rate of our method depends on the $\mathcal{O}(T^{-1/2})$ convergence of online mirror descent as well as risk bounds of the surrogate loss function used to learn the prediction model. Our algorithm and regret bounds apply to a general convex feasible region for the resource constraints, including both hard and soft resource constraint cases, and they apply to a wide class of prediction models in contrast to the traditional settings of linear contextual models or finite policy spaces. We also conduct numerical experiments to empirically demonstrate the strength of our proposed SPO-type methods, as compared to traditional prediction-error-only methods, on multi-dimensional knapsack and longest path instances.
Risk Bounds and Calibration for a Smart Predict-then-Optimize Method
Aug 19, 2021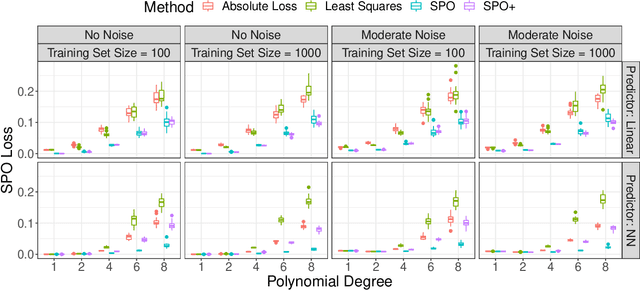
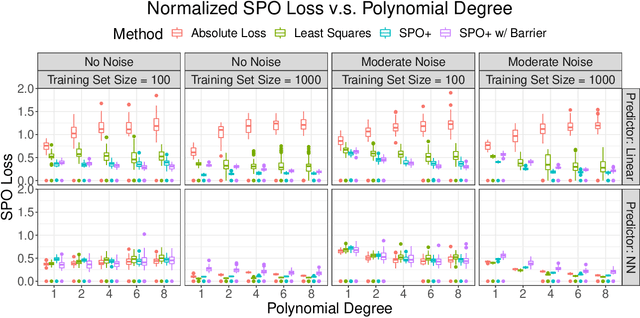
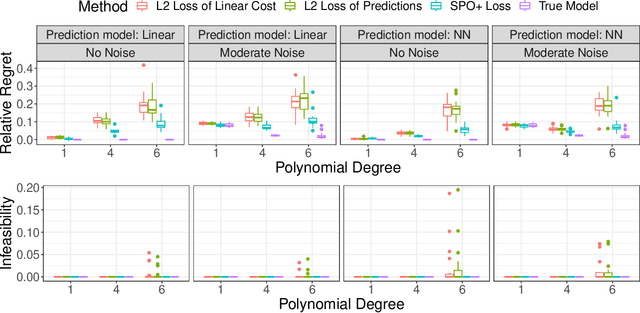
The predict-then-optimize framework is fundamental in practical stochastic decision-making problems: first predict unknown parameters of an optimization model, then solve the problem using the predicted values. A natural loss function in this setting is defined by measuring the decision error induced by the predicted parameters, which was named the Smart Predict-then-Optimize (SPO) loss by Elmachtoub and Grigas [arXiv:1710.08005]. Since the SPO loss is typically nonconvex and possibly discontinuous, Elmachtoub and Grigas [arXiv:1710.08005] introduced a convex surrogate, called the SPO+ loss, that importantly accounts for the underlying structure of the optimization model. In this paper, we greatly expand upon the consistency results for the SPO+ loss provided by Elmachtoub and Grigas [arXiv:1710.08005]. We develop risk bounds and uniform calibration results for the SPO+ loss relative to the SPO loss, which provide a quantitative way to transfer the excess surrogate risk to excess true risk. By combining our risk bounds with generalization bounds, we show that the empirical minimizer of the SPO+ loss achieves low excess true risk with high probability. We first demonstrate these results in the case when the feasible region of the underlying optimization problem is a polyhedron, and then we show that the results can be strengthened substantially when the feasible region is a level set of a strongly convex function. We perform experiments to empirically demonstrate the strength of the SPO+ surrogate, as compared to standard $\ell_1$ and squared $\ell_2$ prediction error losses, on portfolio allocation and cost-sensitive multi-class classification problems.