 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Robot-Centric Learning from Demonstration via Personalized Embeddings
Oct 07, 2021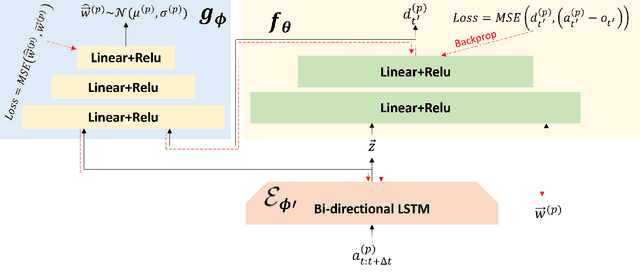
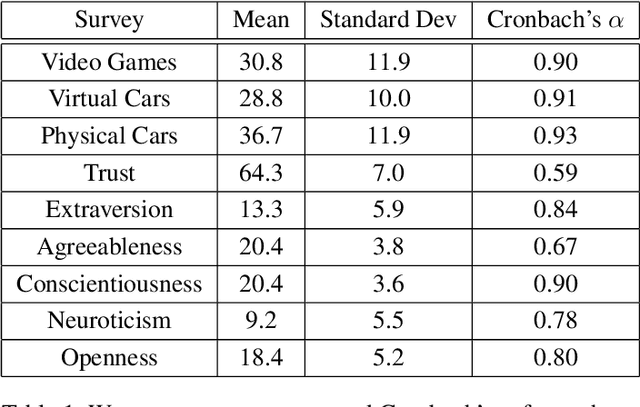
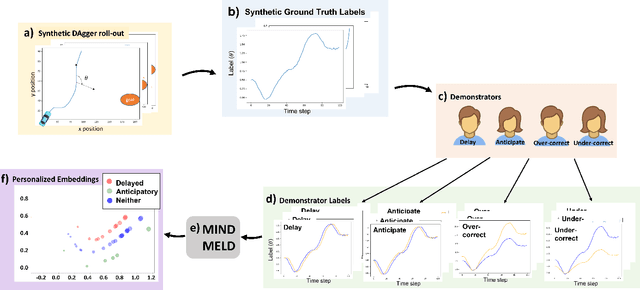

Learning from demonstration (LfD) techniques seek to enable novice users to teach robots novel tasks in the real world. However, prior work has shown that robot-centric LfD approaches, such as Dataset Aggregation (DAgger), do not perform well with human teachers. DAgger requires a human demonstrator to provide corrective feedback to the learner either in real-time, which can result in degraded performance due to suboptimal human labels, or in a post hoc manner which is time intensive and often not feasible. To address this problem, we present Mutual Information-driven Meta-learning from Demonstration (MIND MELD), which meta-learns a mapping from poor quality human labels to predicted ground truth labels, thereby improving upon the performance of prior LfD approaches for DAgger-based training. The key to our approach for improving upon suboptimal feedback is mutual information maximization via variational inference. Our approach learns a meaningful, personalized embedding via variational inference which informs the mapping from human provided labels to predicted ground truth labels. We demonstrate our framework in a synthetic domain and in a human-subjects experiment, illustrating that our approach improves upon the corrective labels provided by a human demonstrator by 63%.