 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Goal and Strategy Inference across Heterogeneous Demonstrators via Reward Network Distillation
Paper and Code
Jan 03, 2020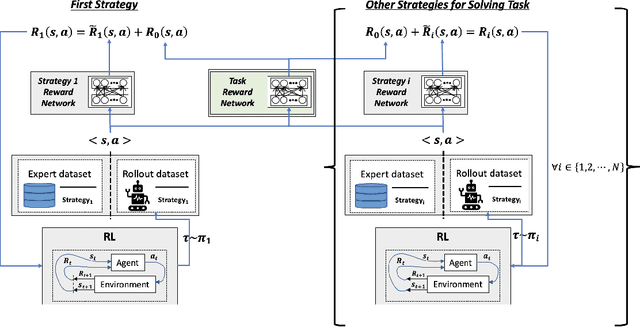
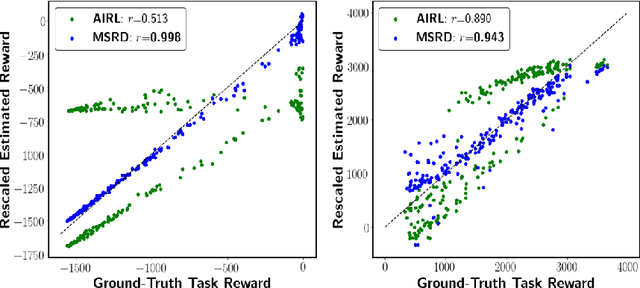
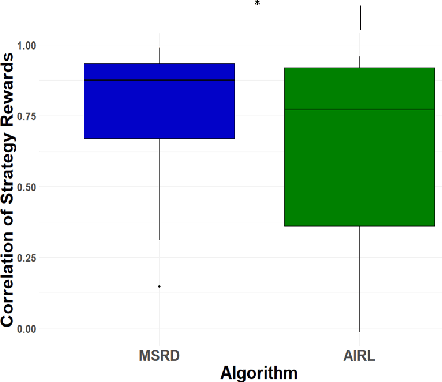
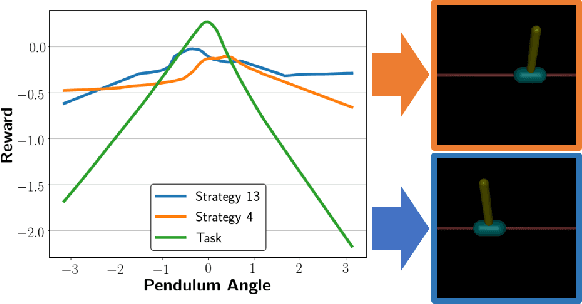
Reinforcement learning (RL) has achieved tremendous success as a general framework for learning how to make decisions. However, this success relies on the interactive hand-tuning of a reward function by RL experts. On the other hand, inverse reinforcement learning (IRL) seeks to learn a reward function from readily-obtained human demonstrations. Yet, IRL suffers from two major limitations: 1) reward ambiguity - there are an infinite number of possible reward functions that could explain an expert's demonstration and 2) heterogeneity - human experts adopt varying strategies and preferences, which makes learning from multiple demonstrators difficult due to the common assumption that demonstrators seeks to maximize the same reward. In this work, we propose a method to jointly infer a task goal and humans' strategic preferences via network distillation. This approach enables us to distill a robust task reward (addressing reward ambiguity) and to model each strategy's objective (handling heterogeneity). We demonstrate our algorithm can better recover task reward and strategy rewards and imitate the strategies in two simulated tasks and a real-world table tennis task.