 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperpixel-based and Spatially-regularized Diffusion Learning for Unsupervised Hyperspectral Image Clustering
Dec 24, 2023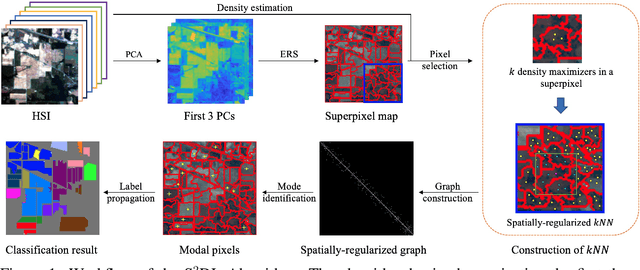
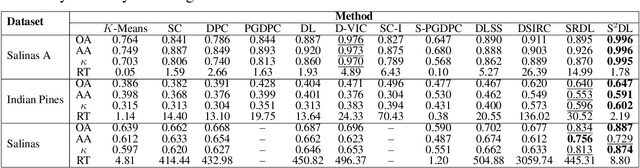

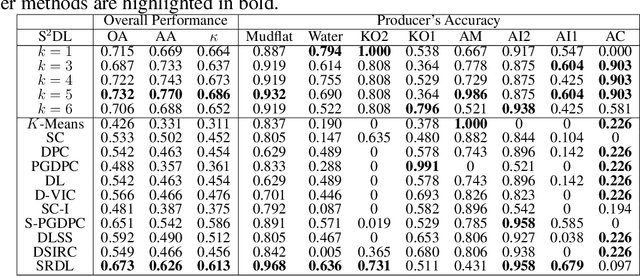
Hyperspectral images (HSIs) provide exceptional spatial and spectral resolution of a scene, crucial for various remote sensing applications. However, the high dimensionality, presence of noise and outliers, and the need for precise labels of HSIs present significant challenges to HSIs analysis, motivating the development of performant HSI clustering algorithms. This paper introduces a novel unsupervised HSI clustering algorithm, Superpixel-based and Spatially-regularized Diffusion Learning (S2DL), which addresses these challenges by incorporating rich spatial information encoded in HSIs into diffusion geometry-based clustering. S2DL employs the Entropy Rate Superpixel (ERS) segmentation technique to partition an image into superpixels, then constructs a spatially-regularized diffusion graph using the most representative high-density pixels. This approach reduces computational burden while preserving accuracy. Cluster modes, serving as exemplars for underlying cluster structure, are identified as the highest-density pixels farthest in diffusion distance from other highest-density pixels. These modes guide the labeling of the remaining representative pixels from ERS superpixels. Finally, majority voting is applied to the labels assigned within each superpixel to propagate labels to the rest of the image. This spatial-spectral approach simultaneously simplifies graph construction, reduces computational cost, and improves clustering performance. S2DL's performance is illustrated with extensive experiments on three publicly available, real-world HSIs: Indian Pines, Salinas, and Salinas A. Additionally, we apply S2DL to landscape-scale, unsupervised mangrove species mapping in the Mai Po Nature Reserve, Hong Kong, using a Gaofen-5 HSI. The success of S2DL in these diverse numerical experiments indicates its efficacy on a wide range of important unsupervised remote sensing analysis tasks.
Semi-supervised Change Detection of Small Water Bodies Using RGB and Multispectral Images in Peruvian Rainforests
Jun 19, 2022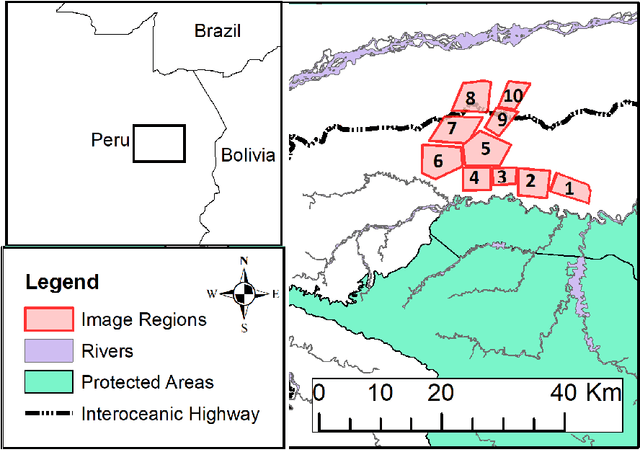
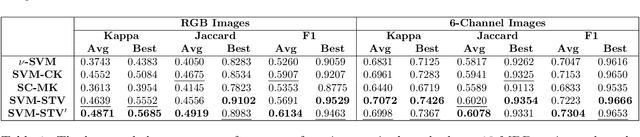

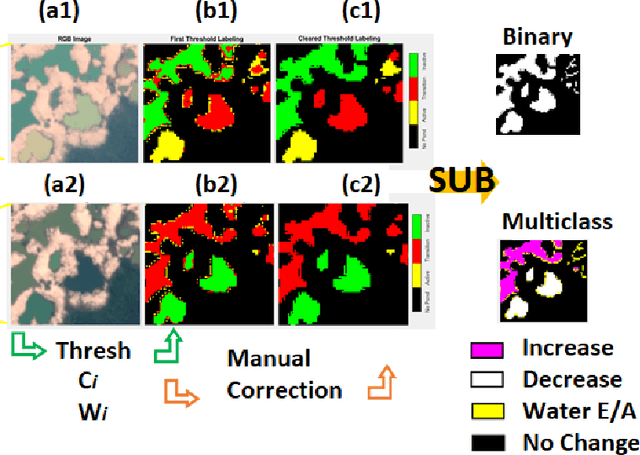
Artisanal and Small-scale Gold Mining (ASGM) is an important source of income for many households, but it can have large social and environmental effects, especially in rainforests of developing countries. The Sentinel-2 satellites collect multispectral images that can be used for the purpose of detecting changes in water extent and quality which indicates the locations of mining sites. This work focuses on the recognition of ASGM activities in Peruvian Amazon rainforests. We tested several semi-supervised classifiers based on Support Vector Machines (SVMs) to detect the changes of water bodies from 2019 to 2021 in the Madre de Dios region, which is one of the global hotspots of ASGM activities. Experiments show that SVM-based models can achieve reasonable performance for both RGB (using Cohen's $\kappa$ 0.49) and 6-channel images (using Cohen's $\kappa$ 0.71) with very limited annotations. The efficacy of incorporating Lab color space for change detection is analyzed as well.
Unsupervised Spatial-spectral Hyperspectral Image Reconstruction and Clustering with Diffusion Geometry
Apr 28, 2022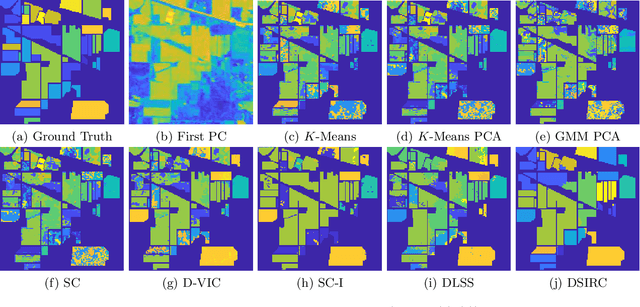

Hyperspectral images, which store a hundred or more spectral bands of reflectance, have become an important data source in natural and social sciences. Hyperspectral images are often generated in large quantities at a relatively coarse spatial resolution. As such, unsupervised machine learning algorithms incorporating known structure in hyperspectral imagery are needed to analyze these images automatically. This work introduces the Spatial-Spectral Image Reconstruction and Clustering with Diffusion Geometry (DSIRC) algorithm for partitioning highly mixed hyperspectral images. DSIRC reduces measurement noise through a shape-adaptive reconstruction procedure. In particular, for each pixel, DSIRC locates spectrally correlated pixels within a data-adaptive spatial neighborhood and reconstructs that pixel's spectral signature using those of its neighbors. DSIRC then locates high-density, high-purity pixels far in diffusion distance (a data-dependent distance metric) from other high-density, high-purity pixels and treats these as cluster exemplars, giving each a unique label. Non-modal pixels are assigned the label of their diffusion distance-nearest neighbor of higher density and purity that is already labeled. Strong numerical results indicate that incorporating spatial information through image reconstruction substantially improves the performance of pixel-wise clustering.
A 3-stage Spectral-spatial Method for Hyperspectral Image Classification
Apr 20, 2022


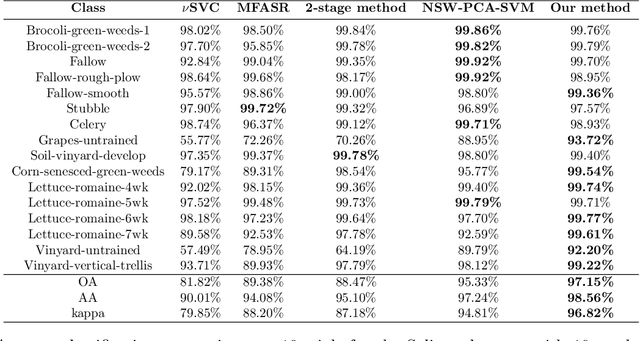
Hyperspectral images often have hundreds of spectral bands of different wavelengths captured by aircraft or satellites that record land coverage. Identifying detailed classes of pixels becomes feasible due to the enhancement in spectral and spatial resolution of hyperspectral images. In this work, we propose a novel framework that utilizes both spatial and spectral information for classifying pixels in hyperspectral images. The method consists of three stages. In the first stage, the pre-processing stage, Nested Sliding Window algorithm is used to reconstruct the original data by {enhancing the consistency of neighboring pixels} and then Principal Component Analysis is used to reduce the dimension of data. In the second stage, Support Vector Machines are trained to estimate the pixel-wise probability map of each class using the spectral information from the images. Finally, a smoothed total variation model is applied to smooth the class probability vectors by {ensuring spatial connectivity} in the images. We demonstrate the superiority of our method against three state-of-the-art algorithms on six benchmark hyperspectral data sets with 10 to 50 training labels for each class. The results show that our method gives the overall best performance in accuracy. Especially, our gain in accuracy increases when the number of labeled pixels decreases and therefore our method is more advantageous to be applied to problems with small training set. Hence it is of great practical significance since expert annotations are often expensive and difficult to collect.
Classification of Hyperspectral Images Using SVM with Shape-adaptive Reconstruction and Smoothed Total Variation
Apr 14, 2022
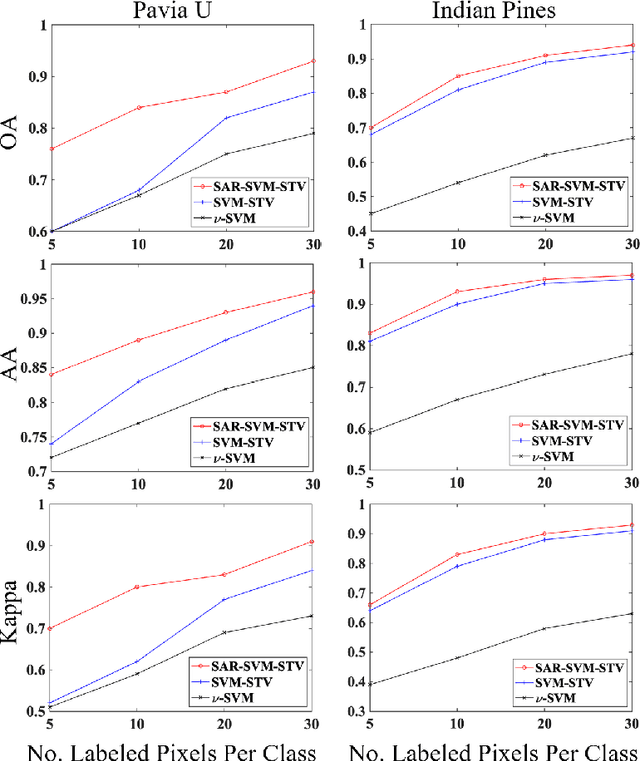
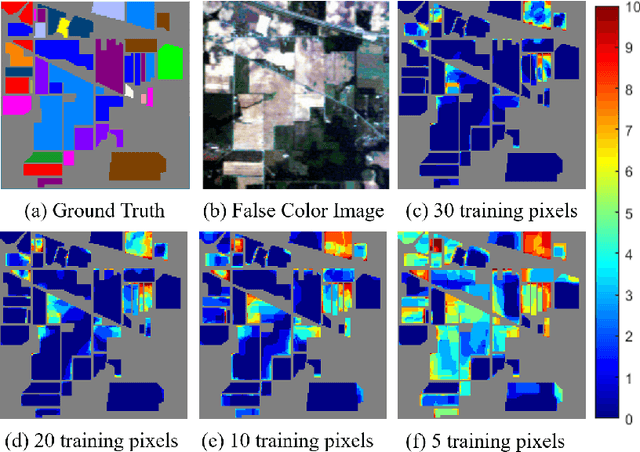

In this work, a novel algorithm called SVM with Shape-adaptive Reconstruction and Smoothed Total Variation (SaR-SVM-STV) is introduced to classify hyperspectral images, which makes full use of spatial and spectral information. The Shape-adaptive Reconstruction (SaR) is introduced to preprocess each pixel based on the Pearson Correlation between pixels in its shape-adaptive (SA) region. Support Vector Machines (SVMs) are trained to estimate the pixel-wise probability maps of each class. Then the Smoothed Total Variation (STV) model is applied to denoise and generate the final classification map. Experiments show that SaR-SVM-STV outperforms the SVM-STV method with a few training labels, demonstrating the significance of reconstructing hyperspectral images before classification.