 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeqWalker: Sequential-Horizon Vision-and-Language Navigation with Hierarchical Planning
Jan 08, 2026Sequential-Horizon Vision-and-Language Navigation (SH-VLN) presents a challenging scenario where agents should sequentially execute multi-task navigation guided by complex, long-horizon language instructions. Current vision-and-language navigation models exhibit significant performance degradation with such multi-task instructions, as information overload impairs the agent's ability to attend to observationally relevant details. To address this problem, we propose SeqWalker, a navigation model built on a hierarchical planning framework. Our SeqWalker features: i) A High-Level Planner that dynamically selects global instructions into contextually relevant sub-instructions based on the agent's current visual observations, thus reducing cognitive load; ii) A Low-Level Planner incorporating an Exploration-Verification strategy that leverages the inherent logical structure of instructions for trajectory error correction. To evaluate SH-VLN performance, we also extend the IVLN dataset and establish a new benchmark. Extensive experiments are performed to demonstrate the superiority of the proposed SeqWalker.
Efficient Low-Tubal-Rank Tensor Estimation via Alternating Preconditioned Gradient Descent
Dec 23, 2025



The problem of low-tubal-rank tensor estimation is a fundamental task with wide applications across high-dimensional signal processing, machine learning, and image science. Traditional approaches tackle such a problem by performing tensor singular value decomposition, which is computationally expensive and becomes infeasible for large-scale tensors. Recent approaches address this issue by factorizing the tensor into two smaller factor tensors and solving the resulting problem using gradient descent. However, this kind of approach requires an accurate estimate of the tensor rank, and when the rank is overestimated, the convergence of gradient descent and its variants slows down significantly or even diverges. To address this problem, we propose an Alternating Preconditioned Gradient Descent (APGD) algorithm, which accelerates convergence in the over-parameterized setting by adding a preconditioning term to the original gradient and updating these two factors alternately. Based on certain geometric assumptions on the objective function, we establish linear convergence guarantees for more general low-tubal-rank tensor estimation problems. Then we further analyze the specific cases of low-tubal-rank tensor factorization and low-tubal-rank tensor recovery. Our theoretical results show that APGD achieves linear convergence even under over-parameterization, and the convergence rate is independent of the tensor condition number. Extensive simulations on synthetic data are carried out to validate our theoretical assertions.
CRISP: Contrastive Residual Injection and Semantic Prompting for Continual Video Instance Segmentation
Aug 14, 2025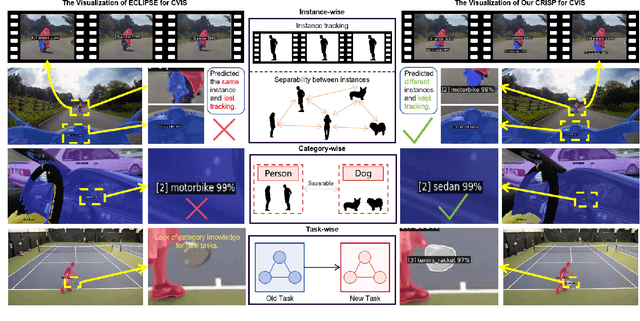
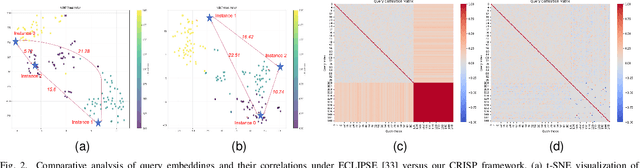
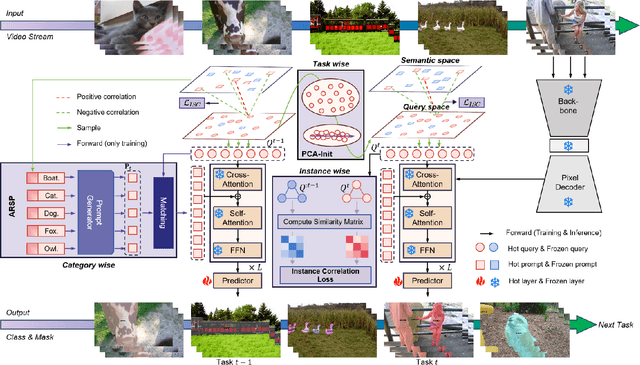
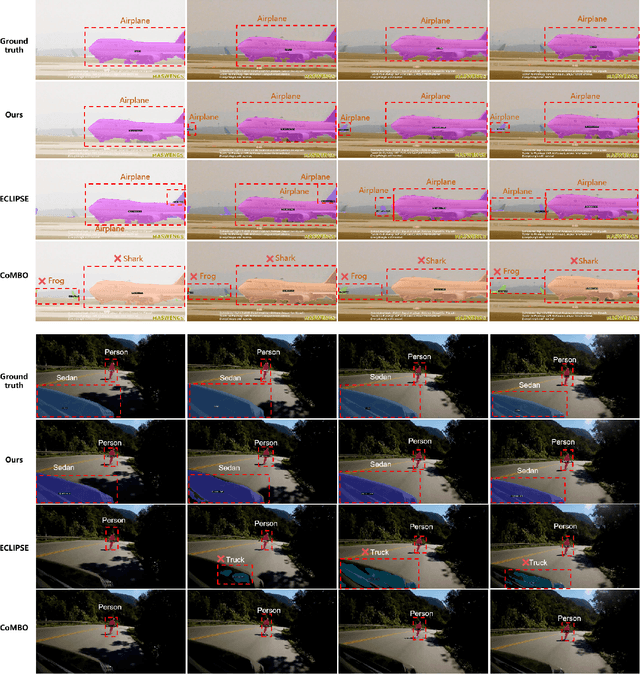
Continual video instance segmentation demands both the plasticity to absorb new object categories and the stability to retain previously learned ones, all while preserving temporal consistency across frames. In this work, we introduce Contrastive Residual Injection and Semantic Prompting (CRISP), an earlier attempt tailored to address the instance-wise, category-wise, and task-wise confusion in continual video instance segmentation. For instance-wise learning, we model instance tracking and construct instance correlation loss, which emphasizes the correlation with the prior query space while strengthening the specificity of the current task query. For category-wise learning, we build an adaptive residual semantic prompt (ARSP) learning framework, which constructs a learnable semantic residual prompt pool generated by category text and uses an adjustive query-prompt matching mechanism to build a mapping relationship between the query of the current task and the semantic residual prompt. Meanwhile, a semantic consistency loss based on the contrastive learning is introduced to maintain semantic coherence between object queries and residual prompts during incremental training. For task-wise learning, to ensure the correlation at the inter-task level within the query space, we introduce a concise yet powerful initialization strategy for incremental prompts. Extensive experiments on YouTube-VIS-2019 and YouTube-VIS-2021 datasets demonstrate that CRISP significantly outperforms existing continual segmentation methods in the long-term continual video instance segmentation task, avoiding catastrophic forgetting and effectively improving segmentation and classification performance. The code is available at https://github.com/01upup10/CRISP.
MMGT: Motion Mask Guided Two-Stage Network for Co-Speech Gesture Video Generation
May 29, 2025Co-Speech Gesture Video Generation aims to generate vivid speech videos from audio-driven still images, which is challenging due to the diversity of different parts of the body in terms of amplitude of motion, audio relevance, and detailed features. Relying solely on audio as the control signal often fails to capture large gesture movements in video, leading to more pronounced artifacts and distortions. Existing approaches typically address this issue by introducing additional a priori information, but this can limit the practical application of the task. Specifically, we propose a Motion Mask-Guided Two-Stage Network (MMGT) that uses audio, as well as motion masks and motion features generated from the audio signal to jointly drive the generation of synchronized speech gesture videos. In the first stage, the Spatial Mask-Guided Audio Pose Generation (SMGA) Network generates high-quality pose videos and motion masks from audio, effectively capturing large movements in key regions such as the face and gestures. In the second stage, we integrate the Motion Masked Hierarchical Audio Attention (MM-HAA) into the Stabilized Diffusion Video Generation model, overcoming limitations in fine-grained motion generation and region-specific detail control found in traditional methods. This guarantees high-quality, detailed upper-body video generation with accurate texture and motion details. Evaluations show improved video quality, lip-sync, and gesture. The model and code are available at https://github.com/SIA-IDE/MMGT.
Vision and Language Integration for Domain Generalization
Apr 17, 2025



Domain generalization aims at training on source domains to uncover a domain-invariant feature space, allowing the model to perform robust generalization ability on unknown target domains. However, due to domain gaps, it is hard to find reliable common image feature space, and the reason for that is the lack of suitable basic units for images. Different from image in vision space, language has comprehensive expression elements that can effectively convey semantics. Inspired by the semantic completeness of language and intuitiveness of image, we propose VLCA, which combine language space and vision space, and connect the multiple image domains by using semantic space as the bridge domain. Specifically, in language space, by taking advantage of the completeness of language basic units, we tend to capture the semantic representation of the relations between categories through word vector distance. Then, in vision space, by taking advantage of the intuitiveness of image features, the common pattern of sample features with the same class is explored through low-rank approximation. In the end, the language representation is aligned with the vision representation through the multimodal space of text and image. Experiments demonstrate the effectiveness of the proposed method.
B*: Efficient and Optimal Base Placement for Fixed-Base Manipulators
Apr 17, 2025B* is a novel optimization framework that addresses a critical challenge in fixed-base manipulator robotics: optimal base placement. Current methods rely on pre-computed kinematics databases generated through sampling to search for solutions. However, they face an inherent trade-off between solution optimality and computational efficiency when determining sampling resolution. To address these limitations, B* unifies multiple objectives without database dependence. The framework employs a two-layer hierarchical approach. The outer layer systematically manages terminal constraints through progressive tightening, particularly for base mobility, enabling feasible initialization and broad solution exploration. The inner layer addresses non-convexities in each outer-layer subproblem through sequential local linearization, converting the original problem into tractable sequential linear programming (SLP). Testing across multiple robot platforms demonstrates B*'s effectiveness. The framework achieves solution optimality five orders of magnitude better than sampling-based approaches while maintaining perfect success rates and reduced computational overhead. Operating directly in configuration space, B* enables simultaneous path planning with customizable optimization criteria. B* serves as a crucial initialization tool that bridges the gap between theoretical motion planning and practical deployment, where feasible trajectory existence is fundamental.
Diverse Representation Embedding for Lifelong Person Re-Identification
Apr 02, 2024Lifelong Person Re-Identification (LReID) aims to continuously learn from successive data streams, matching individuals across multiple cameras. The key challenge for LReID is how to effectively preserve old knowledge while incrementally learning new information, which is caused by task-level domain gaps and limited old task datasets. Existing methods based on CNN backbone are insufficient to explore the representation of each instance from different perspectives, limiting model performance on limited old task datasets and new task datasets. Unlike these methods, we propose a Diverse Representations Embedding (DRE) framework that first explores a pure transformer for LReID. The proposed DRE preserves old knowledge while adapting to new information based on instance-level and task-level layout. Concretely, an Adaptive Constraint Module (ACM) is proposed to implement integration and push away operations between multiple overlapping representations generated by transformer-based backbone, obtaining rich and discriminative representations for each instance to improve adaptive ability of LReID. Based on the processed diverse representations, we propose Knowledge Update (KU) and Knowledge Preservation (KP) strategies at the task-level layout by introducing the adjustment model and the learner model. KU strategy enhances the adaptive learning ability of learner models for new information under the adjustment model prior, and KP strategy preserves old knowledge operated by representation-level alignment and logit-level supervision in limited old task datasets while guaranteeing the adaptive learning information capacity of the LReID model. Compared to state-of-the-art methods, our method achieves significantly improved performance in holistic, large-scale, and occluded datasets.
Low-Tubal-Rank Tensor Recovery via Factorized Gradient Descent
Feb 03, 2024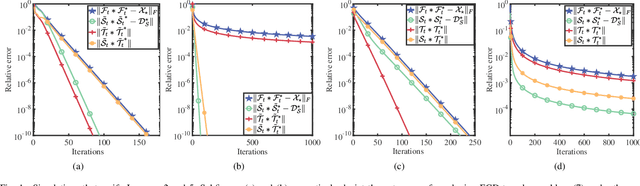
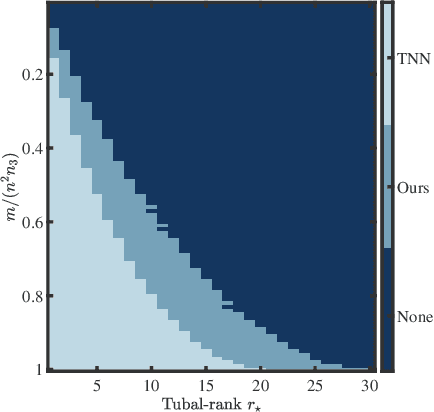
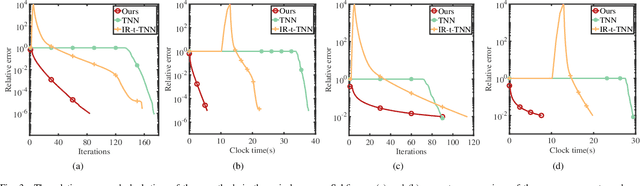
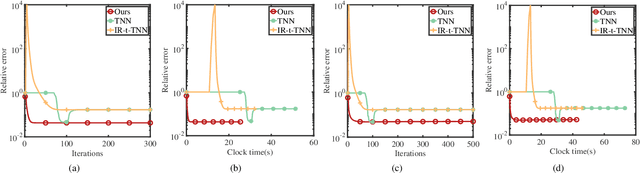
This paper considers the problem of recovering a tensor with an underlying low-tubal-rank structure from a small number of corrupted linear measurements. Traditional approaches tackling such a problem require the computation of tensor Singular Value Decomposition (t-SVD), that is a computationally intensive process, rendering them impractical for dealing with large-scale tensors. Aim to address this challenge, we propose an efficient and effective low-tubal-rank tensor recovery method based on a factorization procedure akin to the Burer-Monteiro (BM) method. Precisely, our fundamental approach involves decomposing a large tensor into two smaller factor tensors, followed by solving the problem through factorized gradient descent (FGD). This strategy eliminates the need for t-SVD computation, thereby reducing computational costs and storage requirements. We provide rigorous theoretical analysis to ensure the convergence of FGD under both noise-free and noisy situations. Additionally, it is worth noting that our method does not require the precise estimation of the tensor tubal-rank. Even in cases where the tubal-rank is slightly overestimated, our approach continues to demonstrate robust performance. A series of experiments have been carried out to demonstrate that, as compared to other popular ones, our approach exhibits superior performance in multiple scenarios, in terms of the faster computational speed and the smaller convergence error.
Deep Convolutional Neural Networks with Zero-Padding: Feature Extraction and Learning
Jul 30, 2023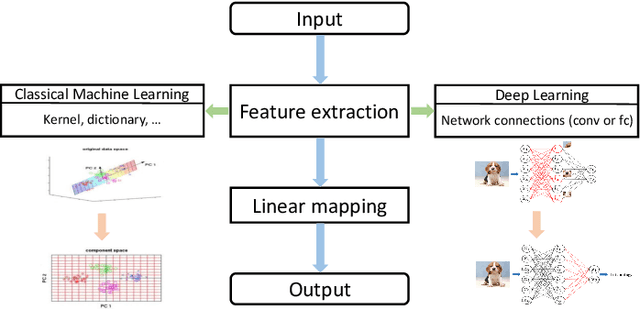

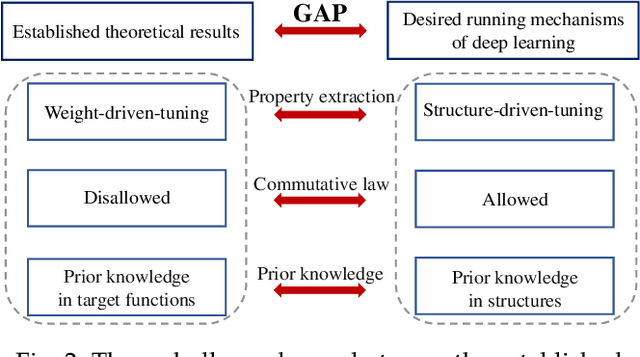
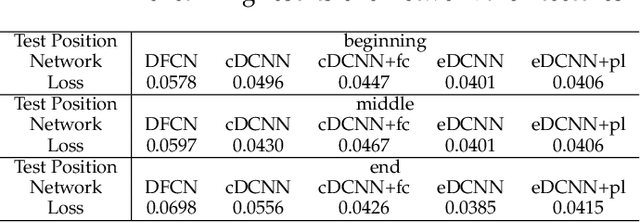
This paper studies the performance of deep convolutional neural networks (DCNNs) with zero-padding in feature extraction and learning. After verifying the roles of zero-padding in enabling translation-equivalence, and pooling in its translation-invariance driven nature, we show that with similar number of free parameters, any deep fully connected networks (DFCNs) can be represented by DCNNs with zero-padding. This demonstrates that DCNNs with zero-padding is essentially better than DFCNs in feature extraction. Consequently, we derive universal consistency of DCNNs with zero-padding and show its translation-invariance in the learning process. All our theoretical results are verified by numerical experiments including both toy simulations and real-data running.
Review helps learn better: Temporal Supervised Knowledge Distillation
Jul 03, 2023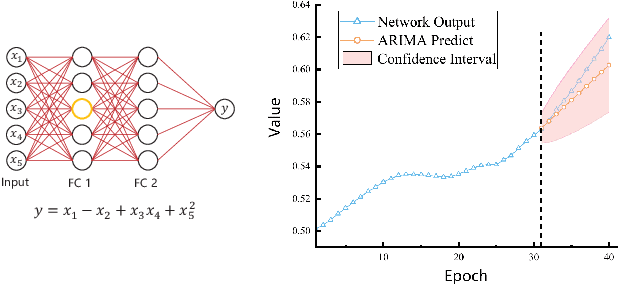
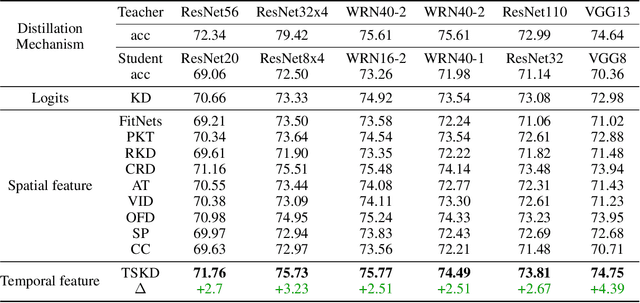
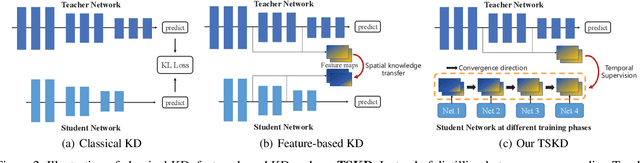

Reviewing plays an important role when learning knowledge. The knowledge acquisition at a certain time point may be strongly inspired with the help of previous experience. Thus the knowledge growing procedure should show strong relationship along the temporal dimension. In our research, we find that during the network training, the evolution of feature map follows temporal sequence property. A proper temporal supervision may further improve the network training performance. Inspired by this observation, we design a novel knowledge distillation method. Specifically, we extract the spatiotemporal features in the different training phases of student by convolutional Long Short-term memory network (Conv-LSTM). Then, we train the student net through a dynamic target, rather than static teacher network features. This process realizes the refinement of old knowledge in student network, and utilizes them to assist current learning. Extensive experiments verify the effectiveness and advantages of our method over existing knowledge distillation methods, including various network architectures, different tasks (image classification and object detection) .