 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Primal Sketch: A Unified Middle-Level Representation for Video
Paper and Code
Feb 10, 2015
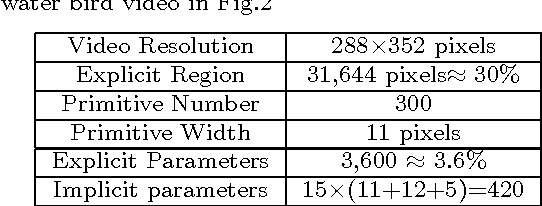
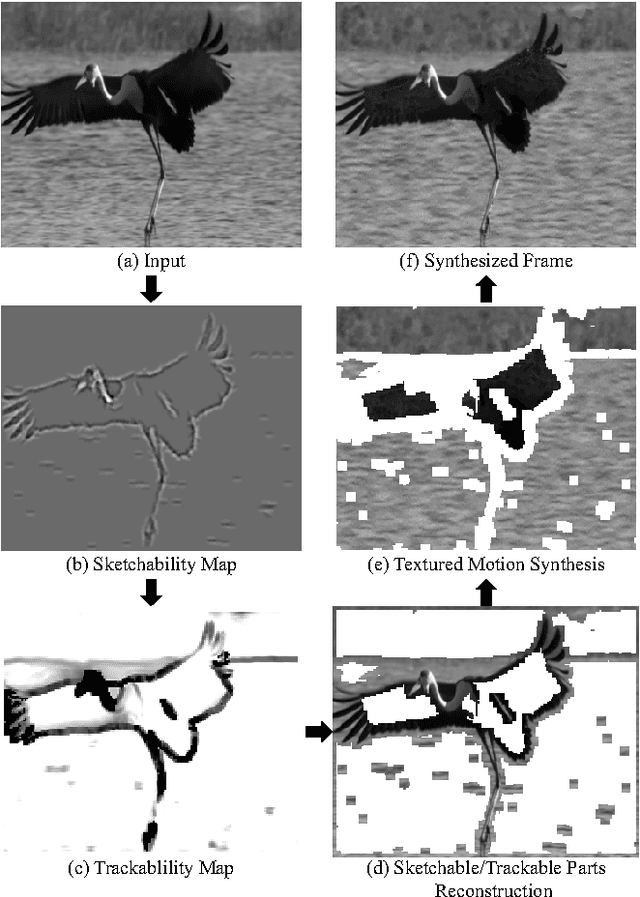
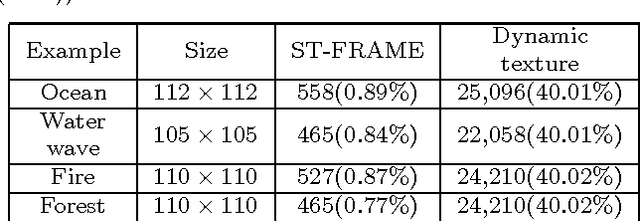
This paper presents a middle-level video representation named Video Primal Sketch (VPS), which integrates two regimes of models: i) sparse coding model using static or moving primitives to explicitly represent moving corners, lines, feature points, etc., ii) FRAME /MRF model reproducing feature statistics extracted from input video to implicitly represent textured motion, such as water and fire. The feature statistics include histograms of spatio-temporal filters and velocity distributions. This paper makes three contributions to the literature: i) Learning a dictionary of video primitives using parametric generative models; ii) Proposing the Spatio-Temporal FRAME (ST-FRAME) and Motion-Appearance FRAME (MA-FRAME) models for modeling and synthesizing textured motion; and iii) Developing a parsimonious hybrid model for generic video representation. Given an input video, VPS selects the proper models automatically for different motion patterns and is compatible with high-level action representations. In the experiments, we synthesize a number of textured motion; reconstruct real videos using the VPS; report a series of human perception experiments to verify the quality of reconstructed videos; demonstrate how the VPS changes over the scale transition in videos; and present the close connection between VPS and high-level action models.