 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProximal PanNet: A Model-Based Deep Network for Pansharpening
Feb 12, 2022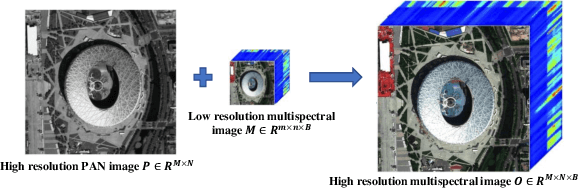
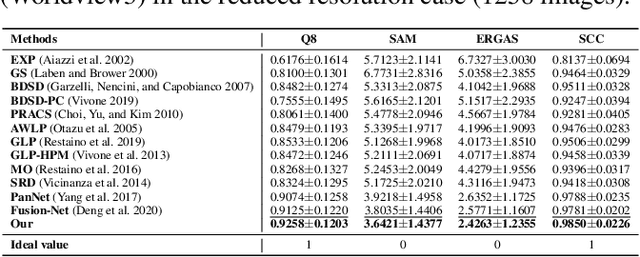
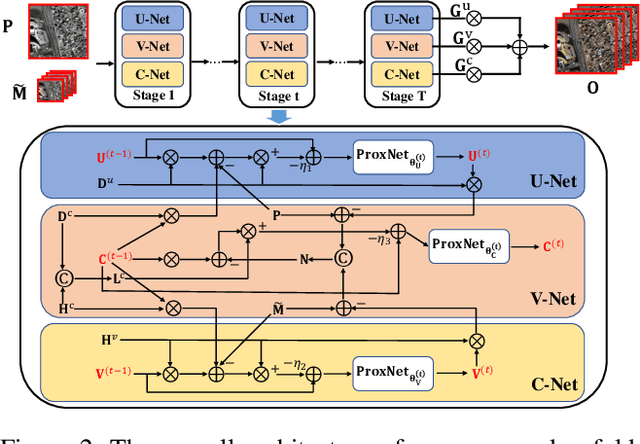
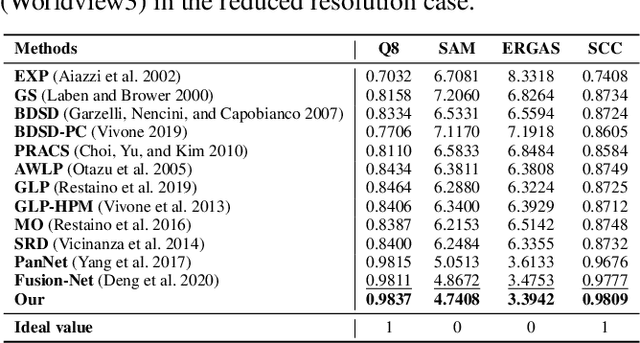
Recently, deep learning techniques have been extensively studied for pansharpening, which aims to generate a high resolution multispectral (HRMS) image by fusing a low resolution multispectral (LRMS) image with a high resolution panchromatic (PAN) image. However, existing deep learning-based pansharpening methods directly learn the mapping from LRMS and PAN to HRMS. These network architectures always lack sufficient interpretability, which limits further performance improvements. To alleviate this issue, we propose a novel deep network for pansharpening by combining the model-based methodology with the deep learning method. Firstly, we build an observation model for pansharpening using the convolutional sparse coding (CSC) technique and design a proximal gradient algorithm to solve this model. Secondly, we unfold the iterative algorithm into a deep network, dubbed as Proximal PanNet, by learning the proximal operators using convolutional neural networks. Finally, all the learnable modules can be automatically learned in an end-to-end manner. Experimental results on some benchmark datasets show that our network performs better than other advanced methods both quantitatively and qualitatively.
Total Variation Regularized Tensor RPCA for Background Subtraction from Compressive Measurements
Jun 05, 2016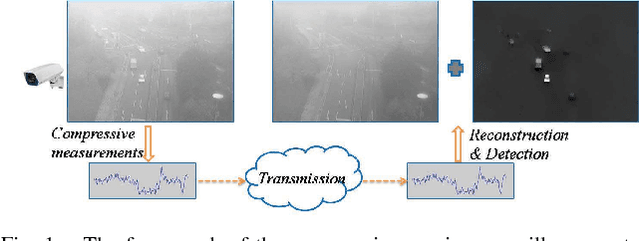


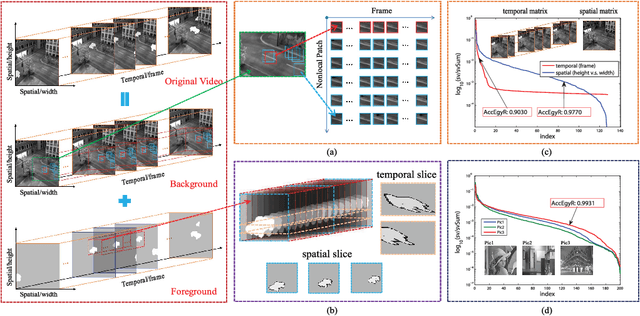
Background subtraction has been a fundamental and widely studied task in video analysis, with a wide range of applications in video surveillance, teleconferencing and 3D modeling. Recently, motivated by compressive imaging, background subtraction from compressive measurements (BSCM) is becoming an active research task in video surveillance. In this paper, we propose a novel tensor-based robust PCA (TenRPCA) approach for BSCM by decomposing video frames into backgrounds with spatial-temporal correlations and foregrounds with spatio-temporal continuity in a tensor framework. In this approach, we use 3D total variation (TV) to enhance the spatio-temporal continuity of foregrounds, and Tucker decomposition to model the spatio-temporal correlations of video background. Based on this idea, we design a basic tensor RPCA model over the video frames, dubbed as the holistic TenRPCA model (H-TenRPCA). To characterize the correlations among the groups of similar 3D patches of video background, we further design a patch-group-based tensor RPCA model (PG-TenRPCA) by joint tensor Tucker decompositions of 3D patch groups for modeling the video background. Efficient algorithms using alternating direction method of multipliers (ADMM) are developed to solve the proposed models. Extensive experiments on simulated and real-world videos demonstrate the superiority of the proposed approaches over the existing state-of-the-art approaches.
Super-resolution reconstruction of hyperspectral images via low rank tensor modeling and total variation regularization
Jan 23, 2016

In this paper, we propose a novel approach to hyperspectral image super-resolution by modeling the global spatial-and-spectral correlation and local smoothness properties over hyperspectral images. Specifically, we utilize the tensor nuclear norm and tensor folded-concave penalty functions to describe the global spatial-and-spectral correlation hidden in hyperspectral images, and 3D total variation (TV) to characterize the local spatial-and-spectral smoothness across all hyperspectral bands. Then, we develop an efficient algorithm for solving the resulting optimization problem by combing the local linear approximation (LLA) strategy and alternative direction method of multipliers (ADMM). Experimental results on one hyperspectral image dataset illustrate the merits of the proposed approach.
Learning a Convolutional Neural Network for Non-uniform Motion Blur Removal
Apr 12, 2015
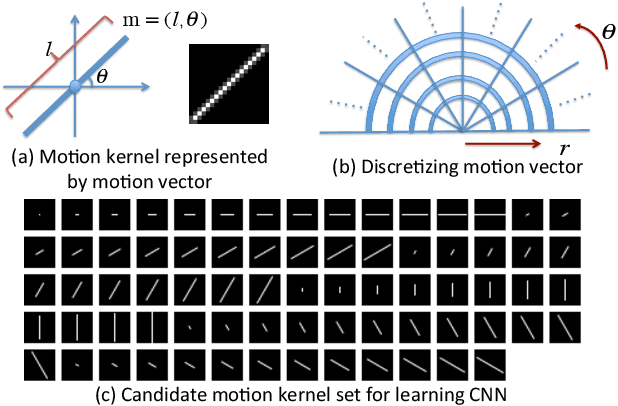


In this paper, we address the problem of estimating and removing non-uniform motion blur from a single blurry image. We propose a deep learning approach to predicting the probabilistic distribution of motion blur at the patch level using a convolutional neural network (CNN). We further extend the candidate set of motion kernels predicted by the CNN using carefully designed image rotations. A Markov random field model is then used to infer a dense non-uniform motion blur field enforcing motion smoothness. Finally, motion blur is removed by a non-uniform deblurring model using patch-level image prior. Experimental evaluations show that our approach can effectively estimate and remove complex non-uniform motion blur that is not handled well by previous approaches.