 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAll-day Multi-scenes Lifelong Vision-and-Language Navigation with Tucker Adaptation
Mar 15, 2026Deploying vision-and-language navigation (VLN) agents requires adaptation across diverse scenes and environments, but fine-tuning on a specific scenario often causes catastrophic forgetting in others, which severely limits flexible long-term deployment. We formalize this challenge as the all-day multi-scenes lifelong VLN (AML-VLN) problem. Existing parameter-efficient adapters (e.g., LoRA and its variants) are limited by their two-dimensional matrix form, which fails to capture the multi-hierarchical navigation knowledge spanning multiple scenes and environments. To address this, we propose Tucker Adaptation (TuKA), which represents the multi-hierarchical navigation knowledge as a high-order tensor and leverages Tucker decomposition to decouple the knowledge into shared subspaces and scenario-specific experts. We further introduce a decoupled knowledge incremental learning strategy to consolidate shared subspaces while constraining specific experts for decoupled lifelong learning. Building on TuKA, we also develop a VLN agent named AlldayWalker, which continually learns across multiple navigation scenarios, achieving all-day multi-scenes navigation. Extensive experiments show that AlldayWalker consistently outperforms state-of-the-art baselines.
Lifelong Language-Conditioned Robotic Manipulation Learning
Mar 05, 2026Traditional language-conditioned manipulation agent sequential adaptation to new manipulation skills leads to catastrophic forgetting of old skills, limiting dynamic scene practical deployment. In this paper, we propose SkillsCrafter, a novel robotic manipulation framework designed to continually learn multiple skills while reducing catastrophic forgetting of old skills. Specifically, we propose a Manipulation Skills Adaptation to retain the old skills knowledge while inheriting the shared knowledge between new and old skills to facilitate learning of new skills. Meanwhile, we perform the singular value decomposition on the diverse skill instructions to obtain common skill semantic subspace projection matrices, thereby recording the essential semantic space of skills. To achieve forget-less and generalization manipulation, we propose a Skills Specialization Aggregation to compute inter-skills similarity in skill semantic subspaces, achieving aggregation of the previously learned skill knowledge for any new or unknown skill. Extensive experiments demonstrate the effectiveness and superiority of our proposed SkillsCrafter.
Efficient Low-Tubal-Rank Tensor Estimation via Alternating Preconditioned Gradient Descent
Dec 23, 2025



The problem of low-tubal-rank tensor estimation is a fundamental task with wide applications across high-dimensional signal processing, machine learning, and image science. Traditional approaches tackle such a problem by performing tensor singular value decomposition, which is computationally expensive and becomes infeasible for large-scale tensors. Recent approaches address this issue by factorizing the tensor into two smaller factor tensors and solving the resulting problem using gradient descent. However, this kind of approach requires an accurate estimate of the tensor rank, and when the rank is overestimated, the convergence of gradient descent and its variants slows down significantly or even diverges. To address this problem, we propose an Alternating Preconditioned Gradient Descent (APGD) algorithm, which accelerates convergence in the over-parameterized setting by adding a preconditioning term to the original gradient and updating these two factors alternately. Based on certain geometric assumptions on the objective function, we establish linear convergence guarantees for more general low-tubal-rank tensor estimation problems. Then we further analyze the specific cases of low-tubal-rank tensor factorization and low-tubal-rank tensor recovery. Our theoretical results show that APGD achieves linear convergence even under over-parameterization, and the convergence rate is independent of the tensor condition number. Extensive simulations on synthetic data are carried out to validate our theoretical assertions.
CMPhysBench: A Benchmark for Evaluating Large Language Models in Condensed Matter Physics
Aug 25, 2025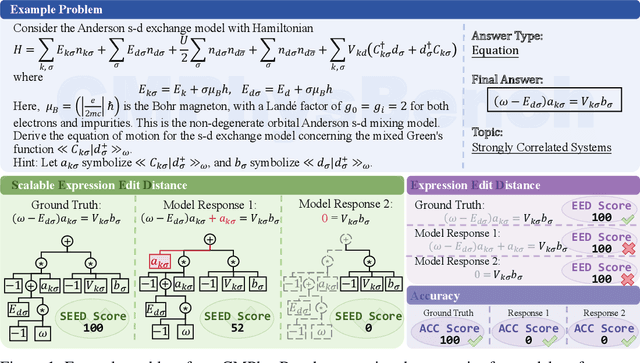
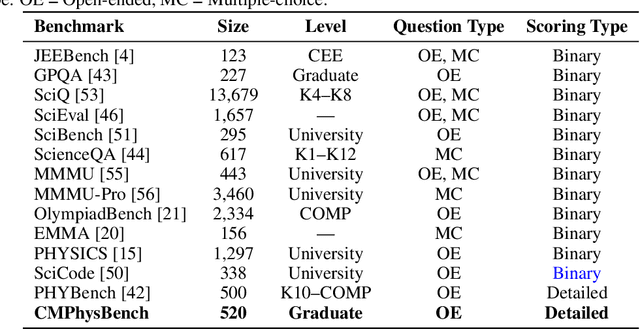
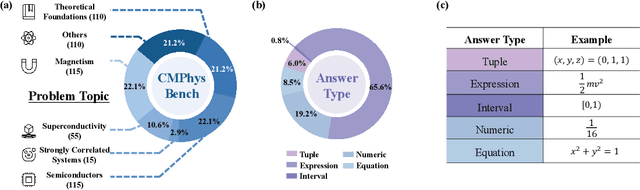

We introduce CMPhysBench, designed to assess the proficiency of Large Language Models (LLMs) in Condensed Matter Physics, as a novel Benchmark. CMPhysBench is composed of more than 520 graduate-level meticulously curated questions covering both representative subfields and foundational theoretical frameworks of condensed matter physics, such as magnetism, superconductivity, strongly correlated systems, etc. To ensure a deep understanding of the problem-solving process,we focus exclusively on calculation problems, requiring LLMs to independently generate comprehensive solutions. Meanwhile, leveraging tree-based representations of expressions, we introduce the Scalable Expression Edit Distance (SEED) score, which provides fine-grained (non-binary) partial credit and yields a more accurate assessment of similarity between prediction and ground-truth. Our results show that even the best models, Grok-4, reach only 36 average SEED score and 28% accuracy on CMPhysBench, underscoring a significant capability gap, especially for this practical and frontier domain relative to traditional physics. The code anddataset are publicly available at https://github.com/CMPhysBench/CMPhysBench.
Low-Tubal-Rank Tensor Recovery via Factorized Gradient Descent
Feb 03, 2024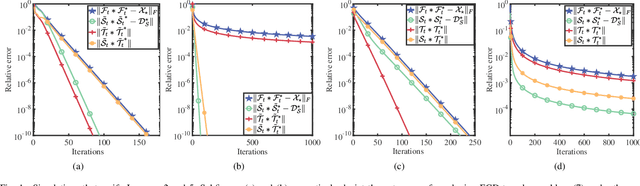
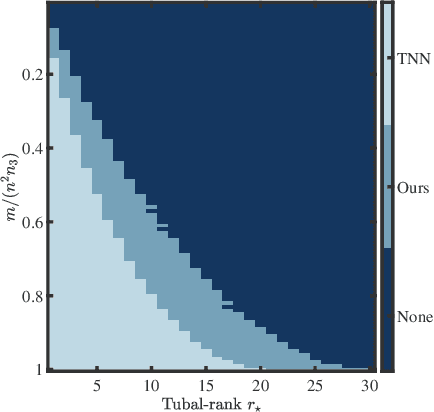
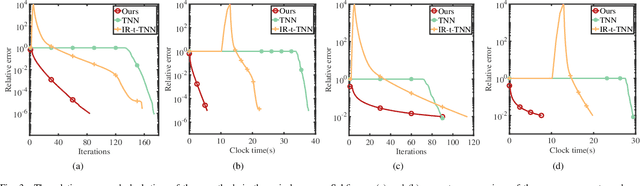
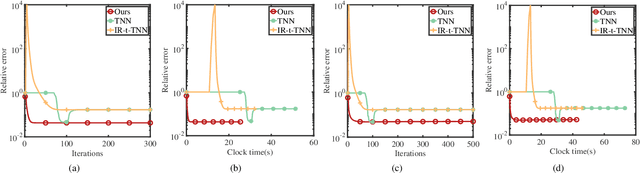
This paper considers the problem of recovering a tensor with an underlying low-tubal-rank structure from a small number of corrupted linear measurements. Traditional approaches tackling such a problem require the computation of tensor Singular Value Decomposition (t-SVD), that is a computationally intensive process, rendering them impractical for dealing with large-scale tensors. Aim to address this challenge, we propose an efficient and effective low-tubal-rank tensor recovery method based on a factorization procedure akin to the Burer-Monteiro (BM) method. Precisely, our fundamental approach involves decomposing a large tensor into two smaller factor tensors, followed by solving the problem through factorized gradient descent (FGD). This strategy eliminates the need for t-SVD computation, thereby reducing computational costs and storage requirements. We provide rigorous theoretical analysis to ensure the convergence of FGD under both noise-free and noisy situations. Additionally, it is worth noting that our method does not require the precise estimation of the tensor tubal-rank. Even in cases where the tubal-rank is slightly overestimated, our approach continues to demonstrate robust performance. A series of experiments have been carried out to demonstrate that, as compared to other popular ones, our approach exhibits superior performance in multiple scenarios, in terms of the faster computational speed and the smaller convergence error.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Efficient textual explanations for complex road and traffic scenarios based on semantic segmentation
Jun 02, 2022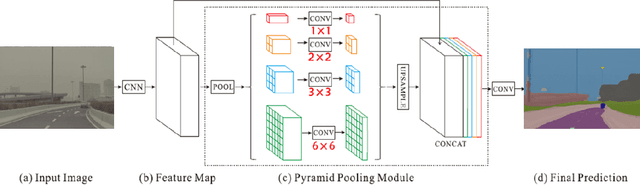

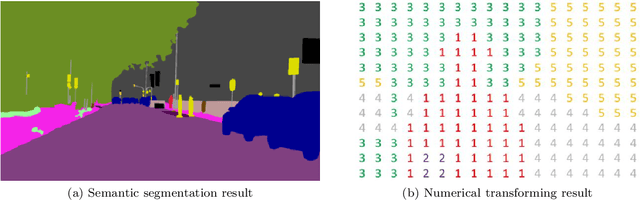
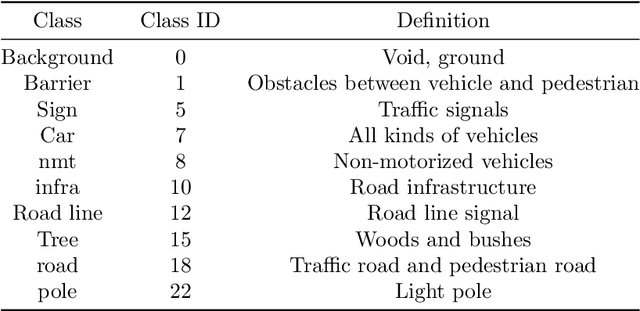
The complex driving environment brings great challenges to the visual perception of autonomous vehicles. It's essential to extract clear and explainable information from the complex road and traffic scenarios and offer clues to decision and control. However, the previous scene explanation had been implemented as a separate model. The black box model makes it difficult to interpret the driving environment. It cannot detect comprehensive textual information and requires a high computational load and time consumption. Thus, this study proposed a comprehensive and efficient textual explanation model. From 336k video frames of the driving environment, critical images of complex road and traffic scenarios were selected into a dataset. Through transfer learning, this study established an accurate and efficient segmentation model to obtain the critical traffic elements in the environment. Based on the XGBoost algorithm, a comprehensive model was developed. The model provided textual information about states of traffic elements, the motion of conflict objects, and scenario complexity. The approach was verified on the real-world road. It improved the perception accuracy of critical traffic elements to 78.8%. The time consumption reached 13 minutes for each epoch, which was 11.5 times more efficient than the pre-trained network. The textual information analyzed from the model was also accordant with reality. The findings offer clear and explainable information about the complex driving environment, which lays a foundation for subsequent decision and control. It can improve the visual perception ability and enrich the prior knowledge and judgments of complex traffic situations.
Specification mining and automated task planning for autonomous robots based on a graph-based spatial temporal logic
Jul 16, 2020
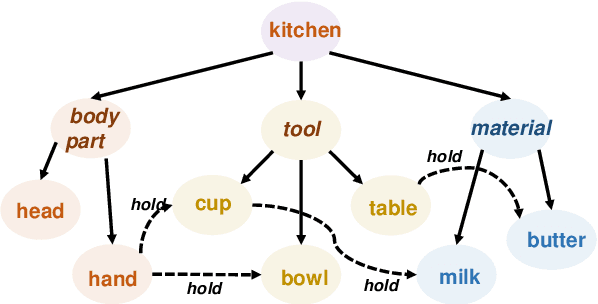
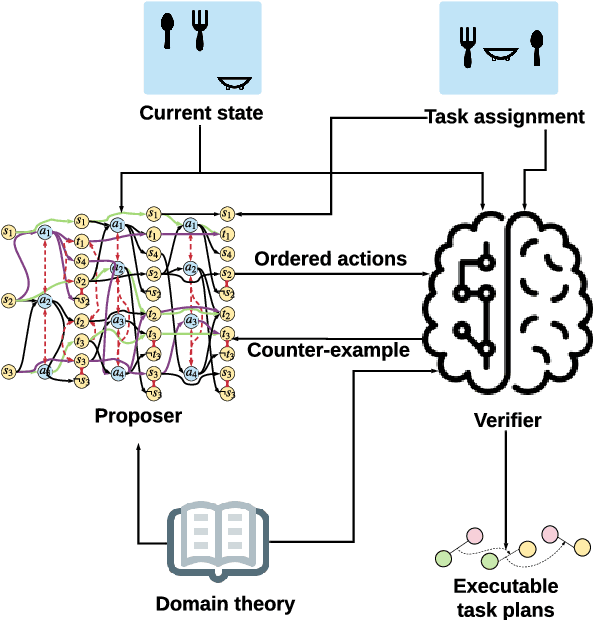
We aim to enable an autonomous robot to learn new skills from demo videos and use these newly learned skills to accomplish non-trivial high-level tasks. The goal of developing such autonomous robot involves knowledge representation, specification mining, and automated task planning. For knowledge representation, we use a graph-based spatial temporal logic (GSTL) to capture spatial and temporal information of related skills demonstrated by demo videos. We design a specification mining algorithm to generate a set of parametric GSTL formulas from demo videos by inductively constructing spatial terms and temporal formulas. The resulting parametric GSTL formulas from specification mining serve as a domain theory, which is used in automated task planning for autonomous robots. We propose an automatic task planning based on GSTL where a proposer is used to generate ordered actions, and a verifier is used to generate executable task plans. A table setting example is used throughout the paper to illustrate the main ideas.
Respiratory Motion Correction in Abdominal MRI using a Densely Connected U-Net with GAN-guided Training
Jun 24, 2019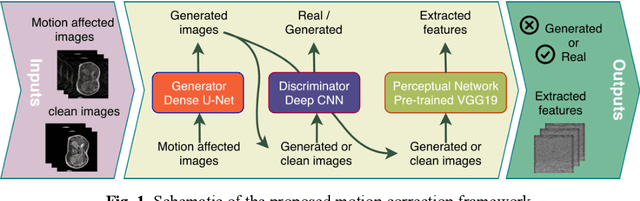
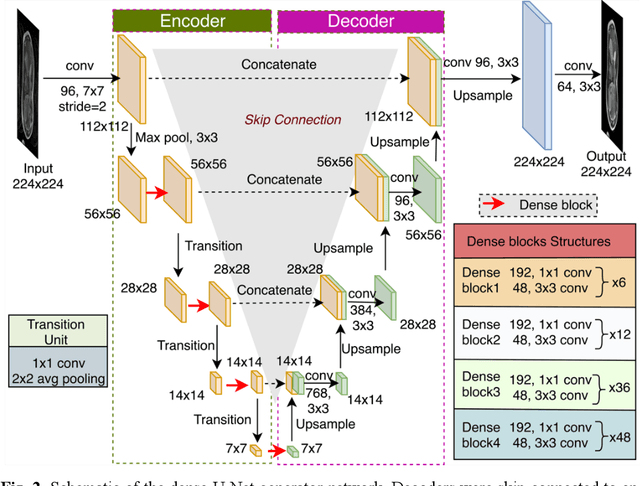
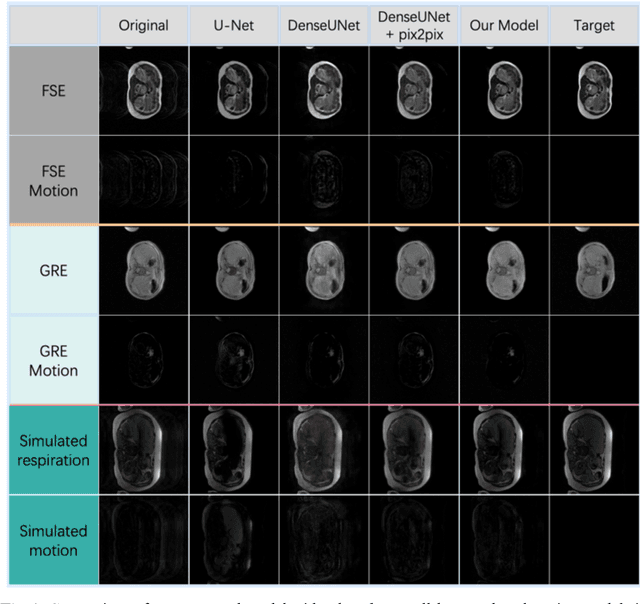
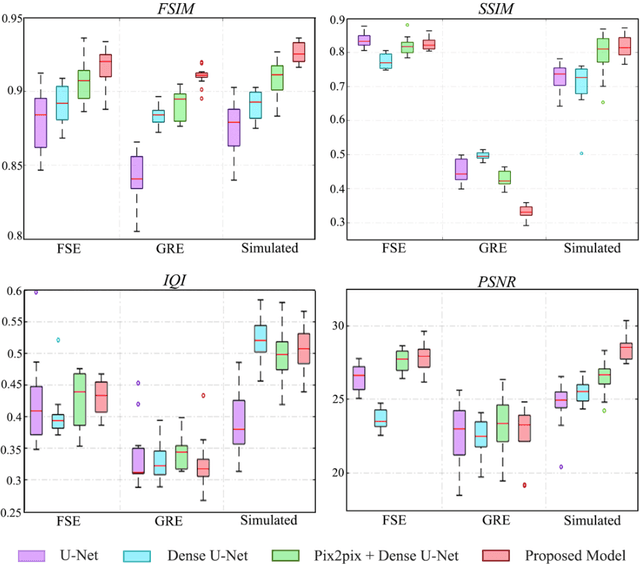
Abdominal magnetic resonance imaging (MRI) provides a straightforward way of characterizing tissue and locating lesions of patients as in standard diagnosis. However, abdominal MRI often suffers from respiratory motion artifacts, which leads to blurring and ghosting that significantly deteriorate the imaging quality. Conventional methods to reduce or eliminate these motion artifacts include breath holding, patient sedation, respiratory gating, and image post-processing, but these strategies inevitably involve extra scanning time and patient discomfort. In this paper, we propose a novel deep-learning-based model to recover MR images from respiratory motion artifacts. The proposed model comprises a densely connected U-net with generative adversarial network (GAN)-guided training and a perceptual loss function. We validate the model using a diverse collection of MRI data that are adversely affected by both synthetic and authentic respiration artifacts. Effective outcomes of motion removal are demonstrated. Our experimental results show the great potential of utilizing deep-learning-based methods in respiratory motion correction for abdominal MRI.
Distributed Communication-aware Motion Planning for Multi-agent Systems from STL and SpaTeL Specifications
May 29, 2017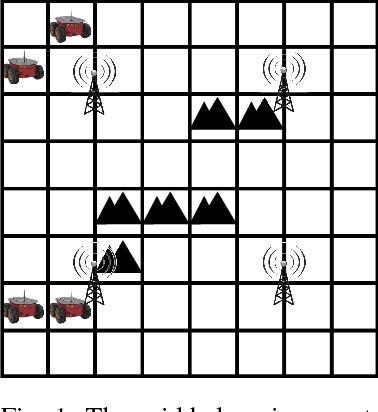
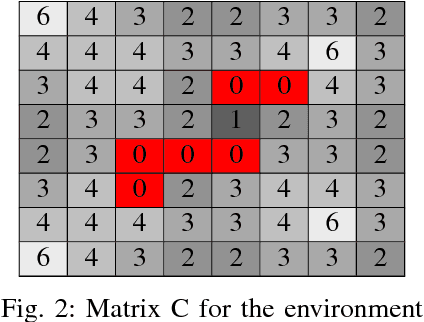
In future intelligent transportation systems, networked vehicles coordinate with each other to achieve safe operations based on an assumption that communications among vehicles and infrastructure are reliable. Traditional methods usually deal with the design of control systems and communication networks in a separated manner. However, control and communication systems are tightly coupled as the motions of vehicles will affect the overall communication quality. Hence, we are motivated to study the co-design of both control and communication systems. In particular, we propose a control theoretical framework for distributed motion planning for multi-agent systems which satisfies complex and high-level spatial and temporal specifications while accounting for communication quality at the same time. Towards this end, desired motion specifications and communication performances are formulated as signal temporal logic (STL) and spatial-temporal logic (SpaTeL) formulas, respectively. The specifications are encoded as constraints on system and environment state variables of mixed integer linear programs (MILP), and upon which control strategies satisfying both STL and SpaTeL specifications are generated for each agent by employing a distributed model predictive control (MPC) framework. Effectiveness of the proposed framework is validated by a simulation of distributed communication-aware motion planning for multi-agent systems.