 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient textual explanations for complex road and traffic scenarios based on semantic segmentation
Jun 02, 2022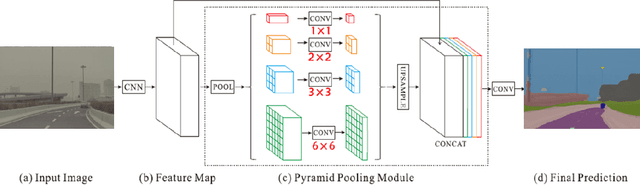

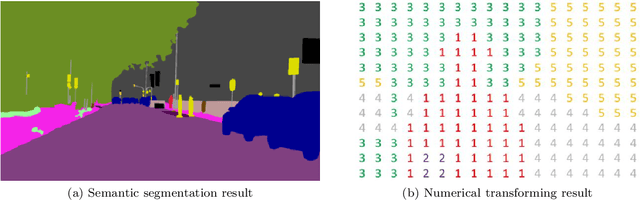
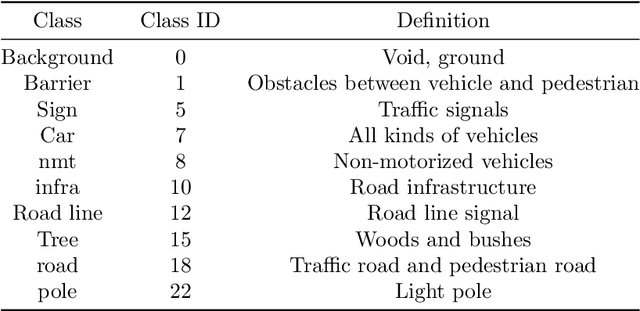
The complex driving environment brings great challenges to the visual perception of autonomous vehicles. It's essential to extract clear and explainable information from the complex road and traffic scenarios and offer clues to decision and control. However, the previous scene explanation had been implemented as a separate model. The black box model makes it difficult to interpret the driving environment. It cannot detect comprehensive textual information and requires a high computational load and time consumption. Thus, this study proposed a comprehensive and efficient textual explanation model. From 336k video frames of the driving environment, critical images of complex road and traffic scenarios were selected into a dataset. Through transfer learning, this study established an accurate and efficient segmentation model to obtain the critical traffic elements in the environment. Based on the XGBoost algorithm, a comprehensive model was developed. The model provided textual information about states of traffic elements, the motion of conflict objects, and scenario complexity. The approach was verified on the real-world road. It improved the perception accuracy of critical traffic elements to 78.8%. The time consumption reached 13 minutes for each epoch, which was 11.5 times more efficient than the pre-trained network. The textual information analyzed from the model was also accordant with reality. The findings offer clear and explainable information about the complex driving environment, which lays a foundation for subsequent decision and control. It can improve the visual perception ability and enrich the prior knowledge and judgments of complex traffic situations.
Human-Vehicle Cooperative Visual Perception for Shared Autonomous Driving
Dec 17, 2021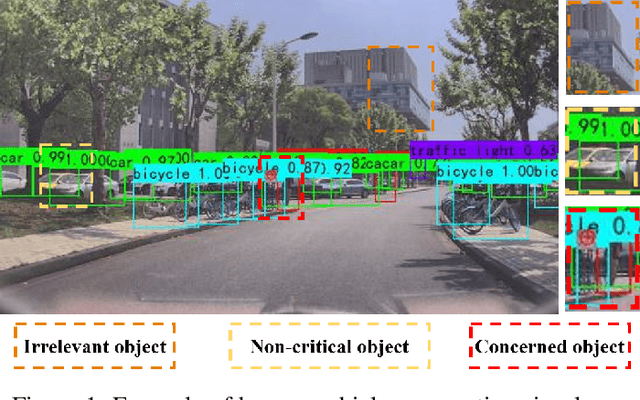
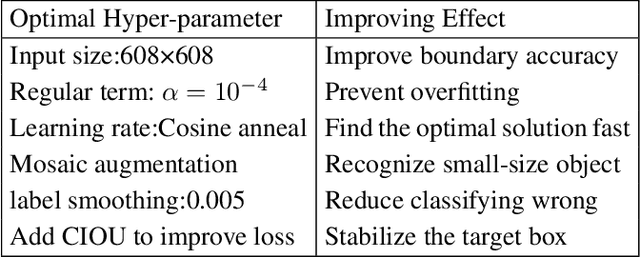
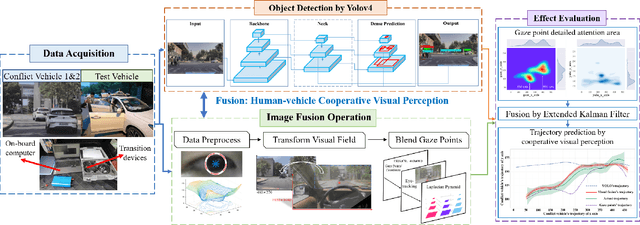

With the development of key technologies like environment perception, the automation level of autonomous vehicles has been increasing. However, before reaching highly autonomous driving, manual driving still needs to participate in the driving process to ensure the safety of human-vehicle shared driving. The existing human-vehicle cooperative driving focuses on auto engineering and drivers' behaviors, with few research studies in the field of visual perception. Due to the bad performance in the complex road traffic conflict scenarios, cooperative visual perception needs to be studied further. In addition, the autonomous driving perception system cannot correctly understand the characteristics of manual driving. Based on the background above, this paper directly proposes a human-vehicle cooperative visual perception method to enhance the visual perception ability of shared autonomous driving based on the transfer learning method and the image fusion algorithm for the complex road traffic scenarios. Based on transfer learning, the mAP of object detection reaches 75.52% and lays a solid foundation for visual fusion. And the fusion experiment further reveals that human-vehicle cooperative visual perception reflects the riskiest zone and predicts the conflict object's trajectory more precisely. This study pioneers a cooperative visual perception solution for shared autonomous driving and experiments in real-world complex traffic conflict scenarios, which can better support the following planning and controlling and improve the safety of autonomous vehicles.