 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient textual explanations for complex road and traffic scenarios based on semantic segmentation
Jun 02, 2022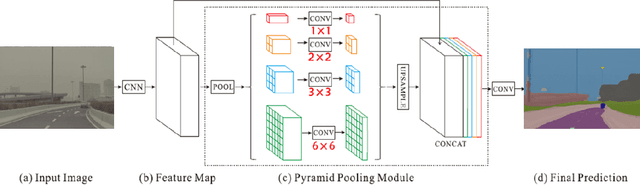

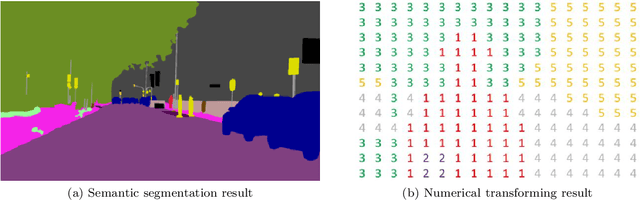
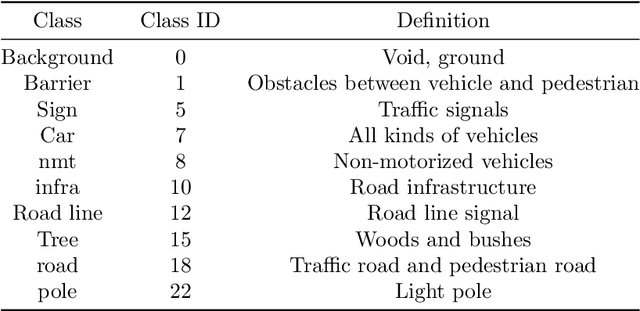
The complex driving environment brings great challenges to the visual perception of autonomous vehicles. It's essential to extract clear and explainable information from the complex road and traffic scenarios and offer clues to decision and control. However, the previous scene explanation had been implemented as a separate model. The black box model makes it difficult to interpret the driving environment. It cannot detect comprehensive textual information and requires a high computational load and time consumption. Thus, this study proposed a comprehensive and efficient textual explanation model. From 336k video frames of the driving environment, critical images of complex road and traffic scenarios were selected into a dataset. Through transfer learning, this study established an accurate and efficient segmentation model to obtain the critical traffic elements in the environment. Based on the XGBoost algorithm, a comprehensive model was developed. The model provided textual information about states of traffic elements, the motion of conflict objects, and scenario complexity. The approach was verified on the real-world road. It improved the perception accuracy of critical traffic elements to 78.8%. The time consumption reached 13 minutes for each epoch, which was 11.5 times more efficient than the pre-trained network. The textual information analyzed from the model was also accordant with reality. The findings offer clear and explainable information about the complex driving environment, which lays a foundation for subsequent decision and control. It can improve the visual perception ability and enrich the prior knowledge and judgments of complex traffic situations.
An Automated Machine Learning (AutoML) Method for Driving Distraction Detection Based on Lane-Keeping Performance
Mar 10, 2021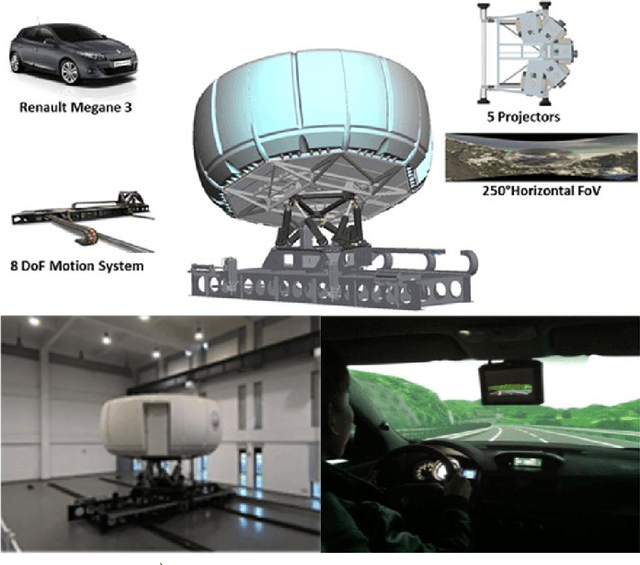
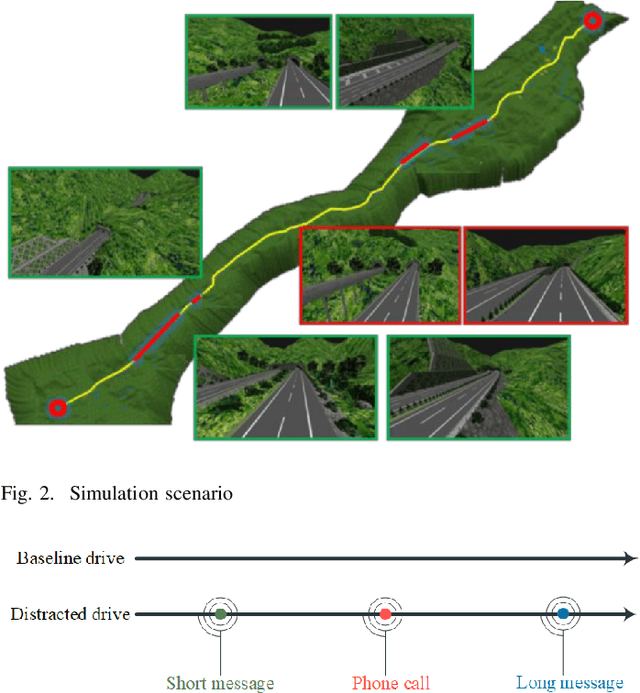
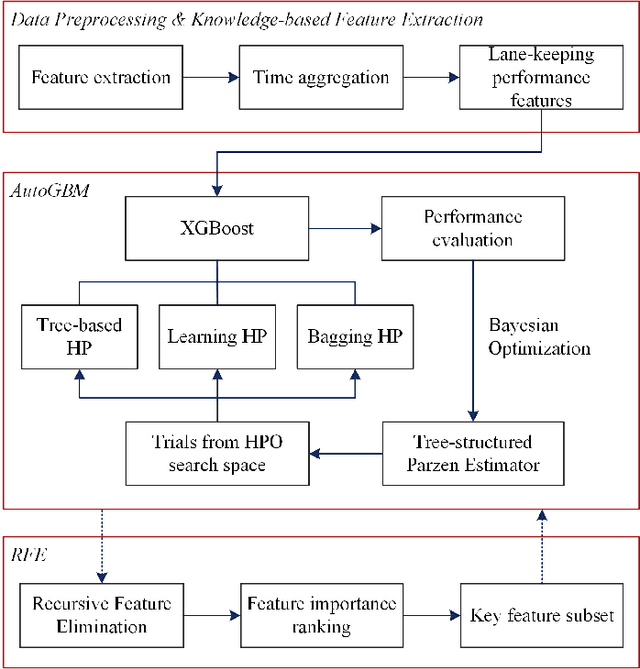
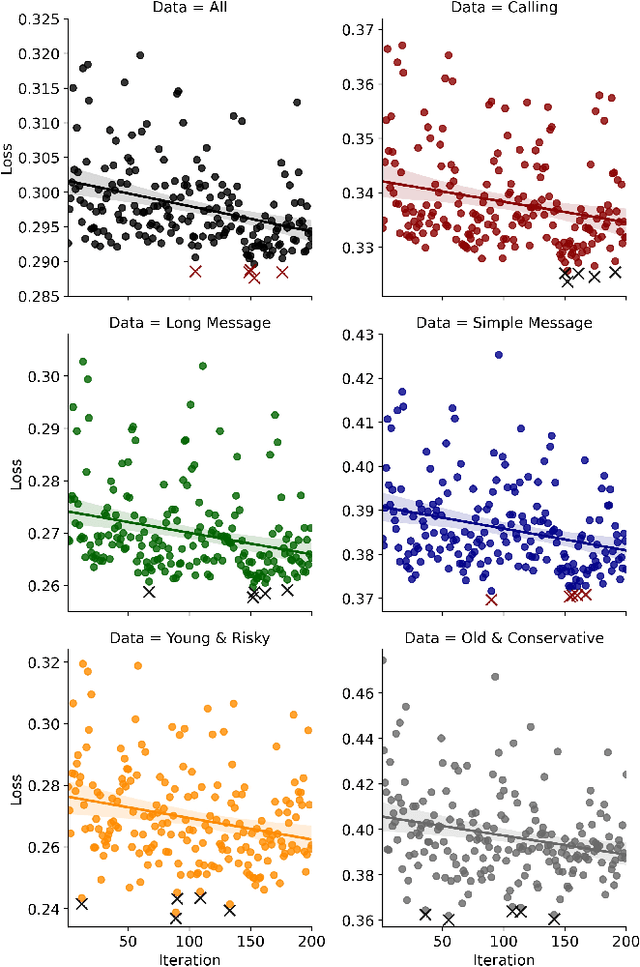
With the enrichment of smartphones, driving distractions caused by phone usages have become a threat to driving safety. A promising way to mitigate driving distractions is to detect them and give real-time safety warnings. However, existing detection algorithms face two major challenges, low user acceptance caused by in-vehicle camera sensors, and uncertain accuracy of pre-trained models due to drivers individual differences. Therefore, this study proposes a domain-specific automated machine learning (AutoML) to self-learn the optimal models to detect distraction based on lane-keeping performance data. The AutoML integrates the key modeling steps into an auto-optimizable pipeline, including knowledge-based feature extraction, feature selection by recursive feature elimination (RFE), algorithm selection, and hyperparameter auto-tuning by Bayesian optimization. An AutoML method based on XGBoost, termed AutoGBM, is built as the classifier for prediction and feature ranking. The model is tested based on driving simulator experiments of three driving distractions caused by phone usage: browsing short messages, browsing long messages, and answering a phone call. The proposed AutoGBM method is found to be reliable and promising to predict phone-related driving distractions, which achieves satisfactory results prediction, with a predictive power of 80\% on group level and 90\% on individual level accuracy. Moreover, the results also evoke the fact that each distraction types and drivers require different optimized hyperparameters values, which reconfirm the necessity of utilizing AutoML to detect driving distractions. The purposed AutoGBM not only produces better performance with fewer features; but also provides data-driven insights about system design.
Automatic Clustering for Unsupervised Risk Diagnosis of Vehicle Driving for Smart Road
Nov 24, 2020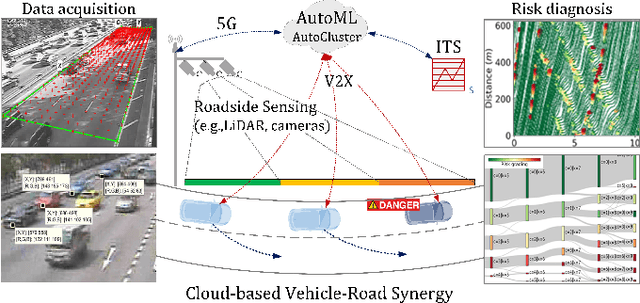
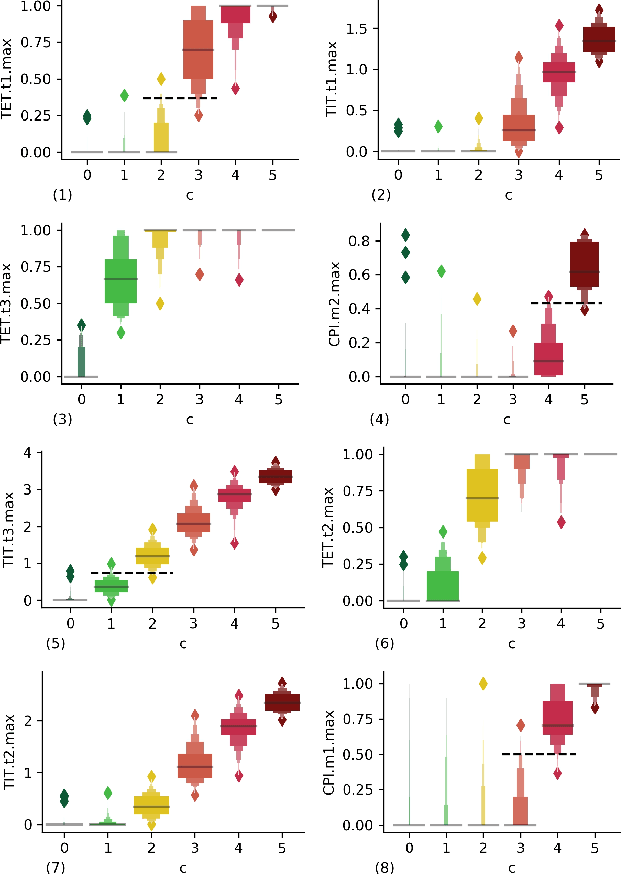
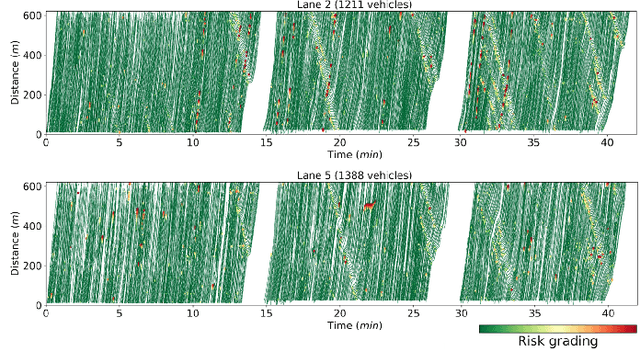
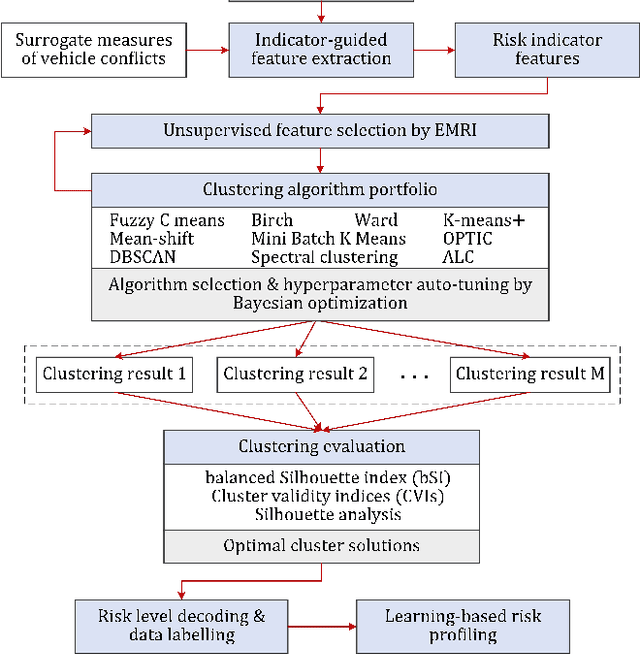
Early risk diagnosis and driving anomaly detection from vehicle stream are of great benefits in a range of advanced solutions towards Smart Road and crash prevention, although there are intrinsic challenges, especially lack of ground truth, definition of multiple risk exposures. This study proposes a domain-specific automatic clustering (termed Autocluster) to self-learn the optimal models for unsupervised risk assessment, which integrates key steps of risk clustering into an auto-optimisable pipeline, including feature and algorithm selection, hyperparameter auto-tuning. Firstly, based on surrogate conflict measures, indicator-guided feature extraction is conducted to construct temporal-spatial and kinematical risk features. Then we develop an elimination-based model reliance importance (EMRI) method to unsupervised-select the useful features. Secondly, we propose balanced Silhouette Index (bSI) to evaluate the internal quality of imbalanced clustering. A loss function is designed that considers the clustering performance in terms of internal quality, inter-cluster variation, and model stability. Thirdly, based on Bayesian optimisation, the algorithm selection and hyperparameter auto-tuning are self-learned to generate the best clustering partitions. Various algorithms are comprehensively investigated. Herein, NGSIM vehicle trajectory data is used for test-bedding. Findings show that Autocluster is reliable and promising to diagnose multiple distinct risk exposures inherent to generalised driving behaviour. Besides, we also delve into risk clustering, such as, algorithms heterogeneity, Silhouette analysis, hierarchical clustering flows, etc. Meanwhile, the Autocluster is also a method for unsupervised multi-risk data labelling and indicator threshold calibration. Furthermore, Autocluster is useful to tackle the challenges in imbalanced clustering without ground truth or priori knowledge