 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiverse Representation Embedding for Lifelong Person Re-Identification
Apr 02, 2024Lifelong Person Re-Identification (LReID) aims to continuously learn from successive data streams, matching individuals across multiple cameras. The key challenge for LReID is how to effectively preserve old knowledge while incrementally learning new information, which is caused by task-level domain gaps and limited old task datasets. Existing methods based on CNN backbone are insufficient to explore the representation of each instance from different perspectives, limiting model performance on limited old task datasets and new task datasets. Unlike these methods, we propose a Diverse Representations Embedding (DRE) framework that first explores a pure transformer for LReID. The proposed DRE preserves old knowledge while adapting to new information based on instance-level and task-level layout. Concretely, an Adaptive Constraint Module (ACM) is proposed to implement integration and push away operations between multiple overlapping representations generated by transformer-based backbone, obtaining rich and discriminative representations for each instance to improve adaptive ability of LReID. Based on the processed diverse representations, we propose Knowledge Update (KU) and Knowledge Preservation (KP) strategies at the task-level layout by introducing the adjustment model and the learner model. KU strategy enhances the adaptive learning ability of learner models for new information under the adjustment model prior, and KP strategy preserves old knowledge operated by representation-level alignment and logit-level supervision in limited old task datasets while guaranteeing the adaptive learning information capacity of the LReID model. Compared to state-of-the-art methods, our method achieves significantly improved performance in holistic, large-scale, and occluded datasets.
Collision-Free Robot Navigation in Crowded Environments using Learning based Convex Model Predictive Control
Mar 14, 2024



Navigating robots safely and efficiently in crowded and complex environments remains a significant challenge. However, due to the dynamic and intricate nature of these settings, planning efficient and collision-free paths for robots to track is particularly difficult. In this paper, we uniquely bridge the robot's perception, decision-making and control processes by utilizing the convex obstacle-free region computed from 2D LiDAR data. The overall pipeline is threefold: (1) We proposes a robot navigation framework that utilizes deep reinforcement learning (DRL), conceptualizing the observation as the convex obstacle-free region, a departure from general reliance on raw sensor inputs. (2) We design the action space, derived from the intersection of the robot's kinematic limits and the convex region, to enable efficient sampling of inherently collision-free reference points. These actions assists in guiding the robot to move towards the goal and interact with other obstacles during navigation. (3) We employ model predictive control (MPC) to track the trajectory formed by the reference points while satisfying constraints imposed by the convex obstacle-free region and the robot's kinodynamic limits. The effectiveness of proposed improvements has been validated through two sets of ablation studies and a comparative experiment against the Timed Elastic Band (TEB), demonstrating improved navigation performance in crowded and complex environments.
Review helps learn better: Temporal Supervised Knowledge Distillation
Jul 03, 2023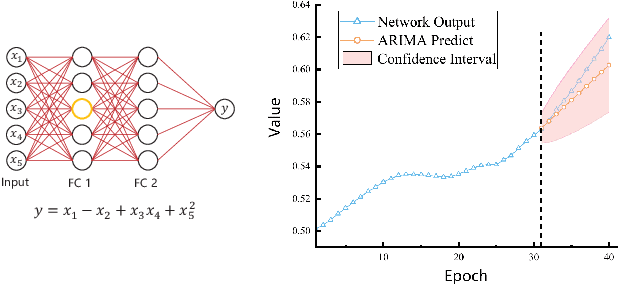
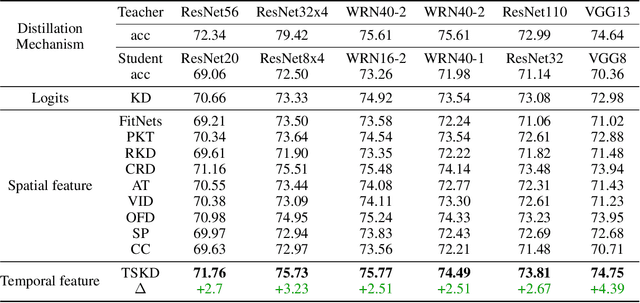
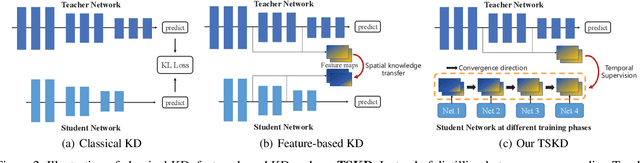

Reviewing plays an important role when learning knowledge. The knowledge acquisition at a certain time point may be strongly inspired with the help of previous experience. Thus the knowledge growing procedure should show strong relationship along the temporal dimension. In our research, we find that during the network training, the evolution of feature map follows temporal sequence property. A proper temporal supervision may further improve the network training performance. Inspired by this observation, we design a novel knowledge distillation method. Specifically, we extract the spatiotemporal features in the different training phases of student by convolutional Long Short-term memory network (Conv-LSTM). Then, we train the student net through a dynamic target, rather than static teacher network features. This process realizes the refinement of old knowledge in student network, and utilizes them to assist current learning. Extensive experiments verify the effectiveness and advantages of our method over existing knowledge distillation methods, including various network architectures, different tasks (image classification and object detection) .
Motion-Aware Transformer For Occluded Person Re-identification
Feb 10, 2022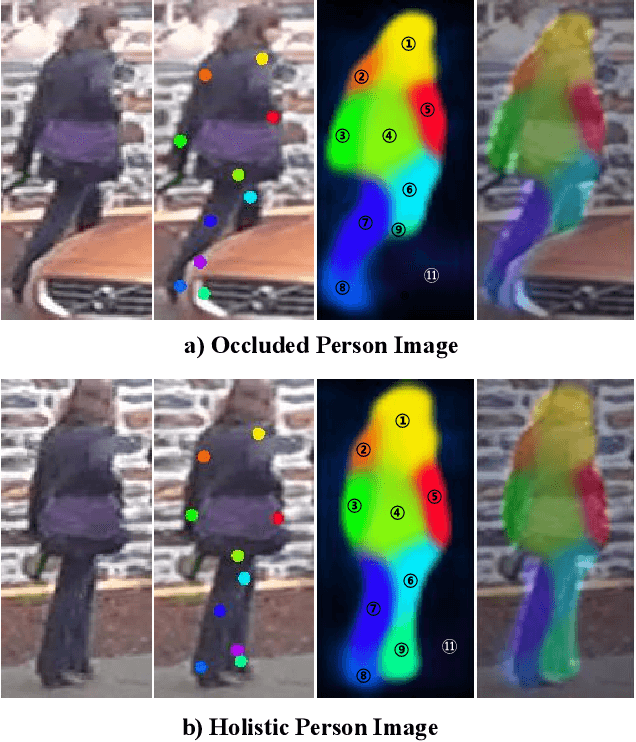
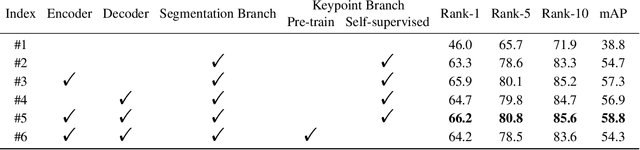
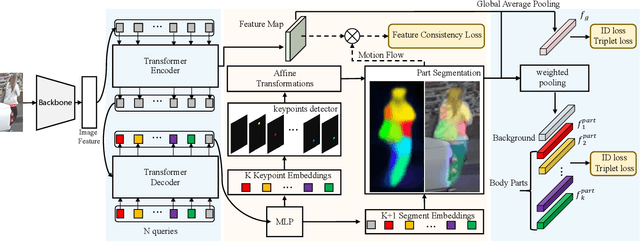
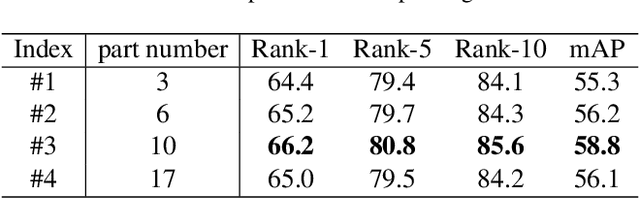
Recently, occluded person re-identification(Re-ID) remains a challenging task that people are frequently obscured by other people or obstacles, especially in a crowd massing situation. In this paper, we propose a self-supervised deep learning method to improve the location performance for human parts through occluded person Re-ID. Unlike previous works, we find that motion information derived from the photos of various human postures can help identify major human body components. Firstly, a motion-aware transformer encoder-decoder architecture is designed to obtain keypoints heatmaps and part-segmentation maps. Secondly, an affine transformation module is utilized to acquire motion information from the keypoint detection branch. Then the motion information will support the segmentation branch to achieve refined human part segmentation maps, and effectively divide the human body into reasonable groups. Finally, several cases demonstrate the efficiency of the proposed model in distinguishing different representative parts of the human body, which can avoid the background and occlusion disturbs. Our method consistently achieves state-of-the-art results on several popular datasets, including occluded, partial, and holistic.