 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Substitute Words with Model-based Score Ranking
Feb 09, 2025



Smart word substitution aims to enhance sentence quality by improving word choices; however current benchmarks rely on human-labeled data. Since word choices are inherently subjective, ground-truth word substitutions generated by a small group of annotators are often incomplete and likely not generalizable. To circumvent this issue, we instead employ a model-based score (BARTScore) to quantify sentence quality, thus forgoing the need for human annotations. Specifically, we use this score to define a distribution for each word substitution, allowing one to test whether a substitution is statistically superior relative to others. In addition, we propose a loss function that directly optimizes the alignment between model predictions and sentence scores, while also enhancing the overall quality score of a substitution. Crucially, model learning no longer requires human labels, thus avoiding the cost of annotation while maintaining the quality of the text modified with substitutions. Experimental results show that the proposed approach outperforms both masked language models (BERT, BART) and large language models (GPT-4, LLaMA). The source code is available at https://github.com/Hyfred/Substitute-Words-with-Ranking.
NTIRE 2023 Quality Assessment of Video Enhancement Challenge
Jul 19, 2023



This paper reports on the NTIRE 2023 Quality Assessment of Video Enhancement Challenge, which will be held in conjunction with the New Trends in Image Restoration and Enhancement Workshop (NTIRE) at CVPR 2023. This challenge is to address a major challenge in the field of video processing, namely, video quality assessment (VQA) for enhanced videos. The challenge uses the VQA Dataset for Perceptual Video Enhancement (VDPVE), which has a total of 1211 enhanced videos, including 600 videos with color, brightness, and contrast enhancements, 310 videos with deblurring, and 301 deshaked videos. The challenge has a total of 167 registered participants. 61 participating teams submitted their prediction results during the development phase, with a total of 3168 submissions. A total of 176 submissions were submitted by 37 participating teams during the final testing phase. Finally, 19 participating teams submitted their models and fact sheets, and detailed the methods they used. Some methods have achieved better results than baseline methods, and the winning methods have demonstrated superior prediction performance.
Few Could Be Better Than All: Feature Sampling and Grouping for Scene Text Detection
Mar 30, 2022
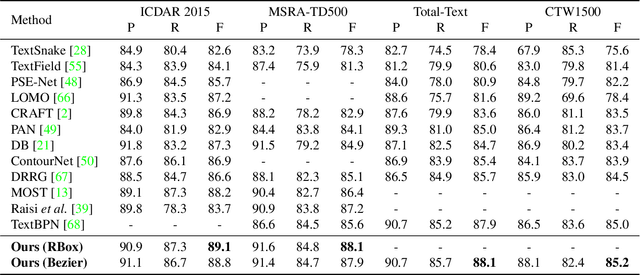
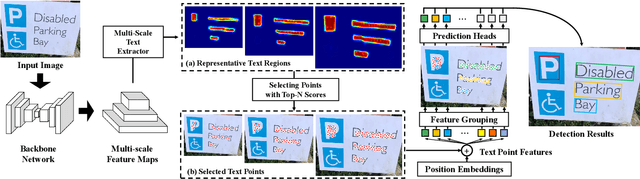
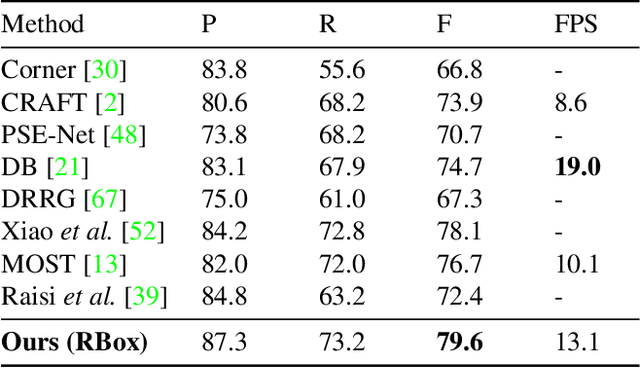
Recently, transformer-based methods have achieved promising progresses in object detection, as they can eliminate the post-processes like NMS and enrich the deep representations. However, these methods cannot well cope with scene text due to its extreme variance of scales and aspect ratios. In this paper, we present a simple yet effective transformer-based architecture for scene text detection. Different from previous approaches that learn robust deep representations of scene text in a holistic manner, our method performs scene text detection based on a few representative features, which avoids the disturbance by background and reduces the computational cost. Specifically, we first select a few representative features at all scales that are highly relevant to foreground text. Then, we adopt a transformer for modeling the relationship of the sampled features, which effectively divides them into reasonable groups. As each feature group corresponds to a text instance, its bounding box can be easily obtained without any post-processing operation. Using the basic feature pyramid network for feature extraction, our method consistently achieves state-of-the-art results on several popular datasets for scene text detection.
Motion-Aware Transformer For Occluded Person Re-identification
Feb 10, 2022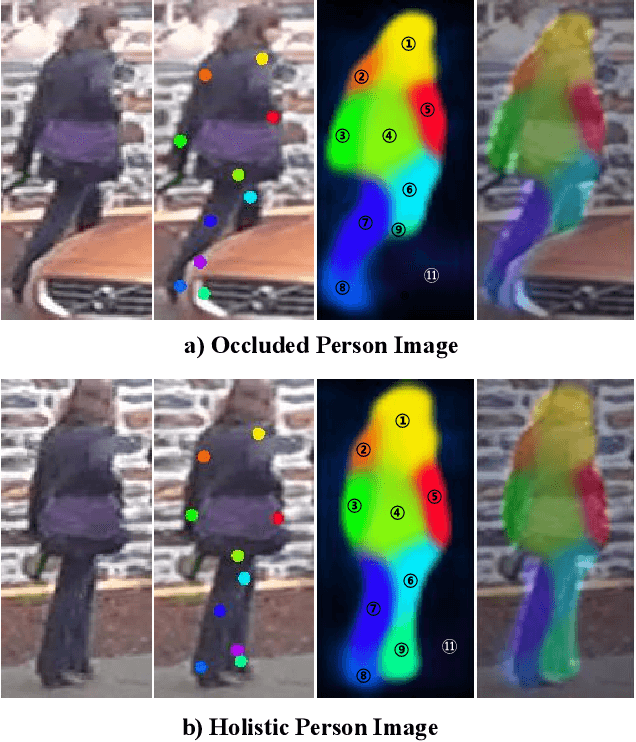
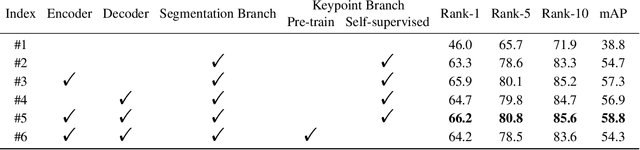
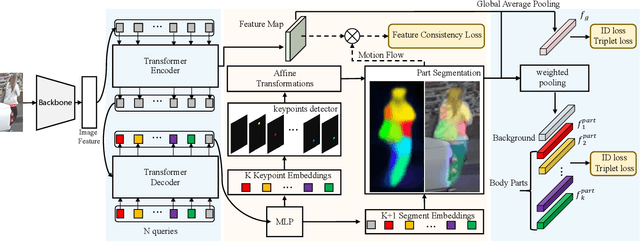
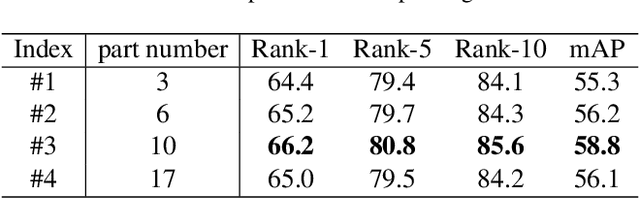
Recently, occluded person re-identification(Re-ID) remains a challenging task that people are frequently obscured by other people or obstacles, especially in a crowd massing situation. In this paper, we propose a self-supervised deep learning method to improve the location performance for human parts through occluded person Re-ID. Unlike previous works, we find that motion information derived from the photos of various human postures can help identify major human body components. Firstly, a motion-aware transformer encoder-decoder architecture is designed to obtain keypoints heatmaps and part-segmentation maps. Secondly, an affine transformation module is utilized to acquire motion information from the keypoint detection branch. Then the motion information will support the segmentation branch to achieve refined human part segmentation maps, and effectively divide the human body into reasonable groups. Finally, several cases demonstrate the efficiency of the proposed model in distinguishing different representative parts of the human body, which can avoid the background and occlusion disturbs. Our method consistently achieves state-of-the-art results on several popular datasets, including occluded, partial, and holistic.
SIXray : A Large-scale Security Inspection X-ray Benchmark for Prohibited Item Discovery in Overlapping Images
Jan 02, 2019
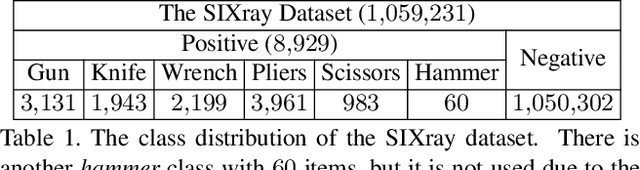
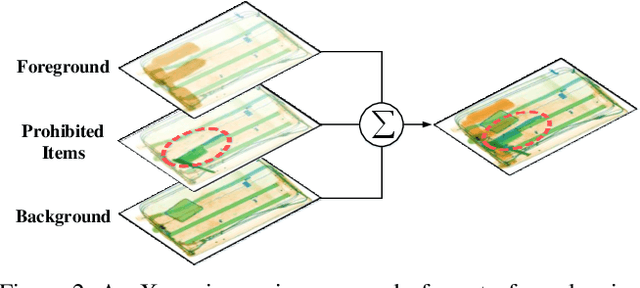

In this paper, we present a large-scale dataset and establish a baseline for prohibited item discovery in Security Inspection X-ray images. Our dataset, named SIXray, consists of 1,059,231 X-ray images, in which 6 classes of 8,929 prohibited items are manually annotated. It raises a brand new challenge of overlapping image data, meanwhile shares the same properties with existing datasets, including complex yet meaningless contexts and class imbalance. We propose an approach named class-balanced hierarchical refinement (CHR) to deal with these difficulties. CHR assumes that each input image is sampled from a mixture distribution, and that deep networks require an iterative process to infer image contents accurately. To accelerate, we insert reversed connections to different network backbones, delivering high-level visual cues to assist mid-level features. In addition, a class-balanced loss function is designed to maximally alleviate the noise introduced by easy negative samples. We evaluate CHR on SIXray with different ratios of positive/negative samples. Compared to the baselines, CHR enjoys a better ability of discriminating objects especially using mid-level features, which offers the possibility of using a weakly-supervised approach towards accurate object localization. In particular, the advantage of CHR is more significant in the scenarios with fewer positive training samples, which demonstrates its potential application in real-world security inspection.