 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew Could Be Better Than All: Feature Sampling and Grouping for Scene Text Detection
Mar 30, 2022
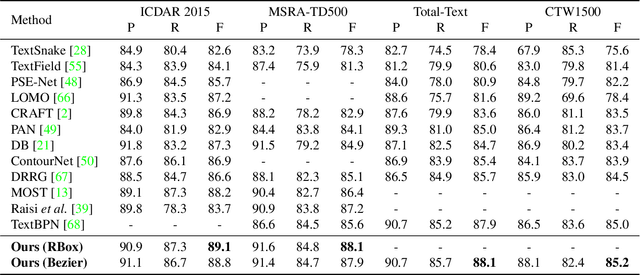
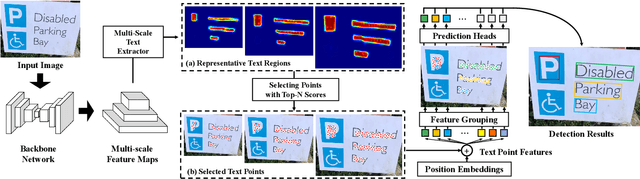
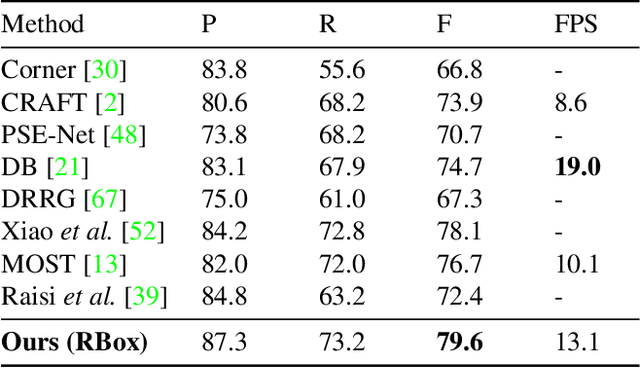
Recently, transformer-based methods have achieved promising progresses in object detection, as they can eliminate the post-processes like NMS and enrich the deep representations. However, these methods cannot well cope with scene text due to its extreme variance of scales and aspect ratios. In this paper, we present a simple yet effective transformer-based architecture for scene text detection. Different from previous approaches that learn robust deep representations of scene text in a holistic manner, our method performs scene text detection based on a few representative features, which avoids the disturbance by background and reduces the computational cost. Specifically, we first select a few representative features at all scales that are highly relevant to foreground text. Then, we adopt a transformer for modeling the relationship of the sampled features, which effectively divides them into reasonable groups. As each feature group corresponds to a text instance, its bounding box can be easily obtained without any post-processing operation. Using the basic feature pyramid network for feature extraction, our method consistently achieves state-of-the-art results on several popular datasets for scene text detection.
Symmetry-constrained Rectification Network for Scene Text Recognition
Aug 06, 2019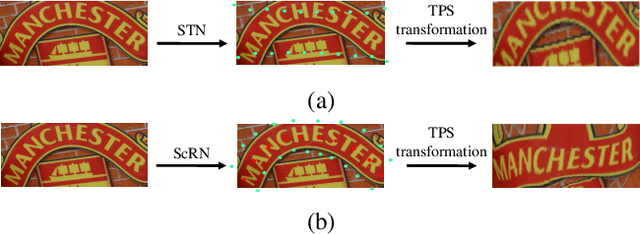
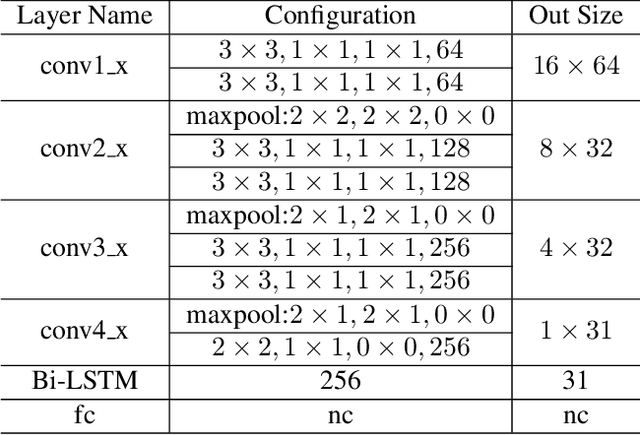
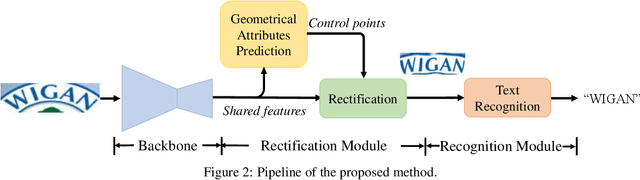
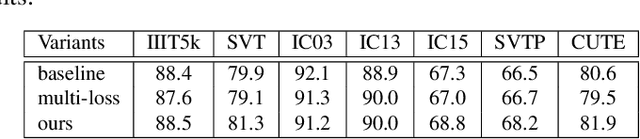
Reading text in the wild is a very challenging task due to the diversity of text instances and the complexity of natural scenes. Recently, the community has paid increasing attention to the problem of recognizing text instances with irregular shapes. One intuitive and effective way to handle this problem is to rectify irregular text to a canonical form before recognition. However, these methods might struggle when dealing with highly curved or distorted text instances. To tackle this issue, we propose in this paper a Symmetry-constrained Rectification Network (ScRN) based on local attributes of text instances, such as center line, scale and orientation. Such constraints with an accurate description of text shape enable ScRN to generate better rectification results than existing methods and thus lead to higher recognition accuracy. Our method achieves state-of-the-art performance on text with both regular and irregular shapes. Specifically, the system outperforms existing algorithms by a large margin on datasets that contain quite a proportion of irregular text instances, e.g., ICDAR 2015, SVT-Perspective and CUTE80.