 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniSIFT: Modality-Asymmetric Token Compression for Efficient Omni-modal Large Language Models
Feb 04, 2026Omni-modal Large Language Models (Omni-LLMs) have demonstrated strong capabilities in audio-video understanding tasks. However, their reliance on long multimodal token sequences leads to substantial computational overhead. Despite this challenge, token compression methods designed for Omni-LLMs remain limited. To bridge this gap, we propose OmniSIFT (Omni-modal Spatio-temporal Informed Fine-grained Token compression), a modality-asymmetric token compression framework tailored for Omni-LLMs. Specifically, OmniSIFT adopts a two-stage compression strategy: (i) a spatio-temporal video pruning module that removes video redundancy arising from both intra-frame structure and inter-frame overlap, and (ii) a vision-guided audio selection module that filters audio tokens. The entire framework is optimized end-to-end via a differentiable straight-through estimator. Extensive experiments on five representative benchmarks demonstrate the efficacy and robustness of OmniSIFT. Notably, for Qwen2.5-Omni-7B, OmniSIFT introduces only 4.85M parameters while maintaining lower latency than training-free baselines such as OmniZip. With merely 25% of the original token context, OmniSIFT consistently outperforms all compression baselines and even surpasses the performance of the full-token model on several tasks.
Semantic Routing: Exploring Multi-Layer LLM Feature Weighting for Diffusion Transformers
Feb 03, 2026Recent DiT-based text-to-image models increasingly adopt LLMs as text encoders, yet text conditioning remains largely static and often utilizes only a single LLM layer, despite pronounced semantic hierarchy across LLM layers and non-stationary denoising dynamics over both diffusion time and network depth. To better match the dynamic process of DiT generation and thereby enhance the diffusion model's generative capability, we introduce a unified normalized convex fusion framework equipped with lightweight gates to systematically organize multi-layer LLM hidden states via time-wise, depth-wise, and joint fusion. Experiments establish Depth-wise Semantic Routing as the superior conditioning strategy, consistently improving text-image alignment and compositional generation (e.g., +9.97 on the GenAI-Bench Counting task). Conversely, we find that purely time-wise fusion can paradoxically degrade visual generation fidelity. We attribute this to a train-inference trajectory mismatch: under classifier-free guidance, nominal timesteps fail to track the effective SNR, causing semantically mistimed feature injection during inference. Overall, our results position depth-wise routing as a strong and effective baseline and highlight the critical need for trajectory-aware signals to enable robust time-dependent conditioning.
GRAN-TED: Generating Robust, Aligned, and Nuanced Text Embedding for Diffusion Models
Dec 17, 2025The text encoder is a critical component of text-to-image and text-to-video diffusion models, fundamentally determining the semantic fidelity of the generated content. However, its development has been hindered by two major challenges: the lack of an efficient evaluation framework that reliably predicts downstream generation performance, and the difficulty of effectively adapting pretrained language models for visual synthesis. To address these issues, we introduce GRAN-TED, a paradigm to Generate Robust, Aligned, and Nuanced Text Embeddings for Diffusion models. Our contribution is twofold. First, we propose TED-6K, a novel text-only benchmark that enables efficient and robust assessment of an encoder's representational quality without requiring costly end-to-end model training. We demonstrate that performance on TED-6K, standardized via a lightweight, unified adapter, strongly correlates with an encoder's effectiveness in downstream generation tasks. Second, guided by this validated framework, we develop a superior text encoder using a novel two-stage training paradigm. This process involves an initial fine-tuning stage on a Multimodal Large Language Model for better visual representation, followed by a layer-wise weighting method to extract more nuanced and potent text features. Our experiments show that the resulting GRAN-TED encoder not only achieves state-of-the-art performance on TED-6K but also leads to demonstrable performance gains in text-to-image and text-to-video generation. Our code is available at the following link: https://anonymous.4open.science/r/GRAN-TED-4FCC/.
The Unseen Bias: How Norm Discrepancy in Pre-Norm MLLMs Leads to Visual Information Loss
Dec 09, 2025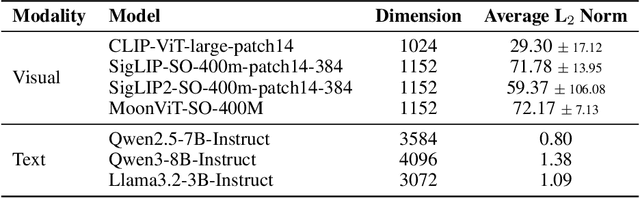

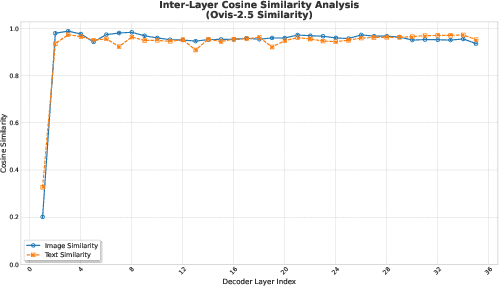

Multimodal Large Language Models (MLLMs), which couple pre-trained vision encoders and language models, have shown remarkable capabilities. However, their reliance on the ubiquitous Pre-Norm architecture introduces a subtle yet critical flaw: a severe norm disparity between the high-norm visual tokens and the low-norm text tokens. In this work, we present a formal theoretical analysis demonstrating that this imbalance is not a static issue. Instead, it induces an ``asymmetric update dynamic,'' where high-norm visual tokens exhibit a ``representational inertia,'' causing them to transform semantically much slower than their textual counterparts. This fundamentally impairs effective cross-modal feature fusion. Our empirical validation across a range of mainstream MLLMs confirms that this theoretical dynamic -- the persistence of norm disparity and the resulting asymmetric update rates -- is a prevalent phenomenon. Based on this insight, we propose a remarkably simple yet effective solution: inserting a single, carefully initialized LayerNorm layer after the visual projector to enforce norm alignment. Experiments conducted on the LLaVA-1.5 architecture show that this intervention yields significant performance gains not only on a wide suite of multimodal benchmarks but also, notably, on text-only evaluations such as MMLU, suggesting that resolving the architectural imbalance leads to a more holistically capable model.
VersaVid-R1: A Versatile Video Understanding and Reasoning Model from Question Answering to Captioning Tasks
Jun 10, 2025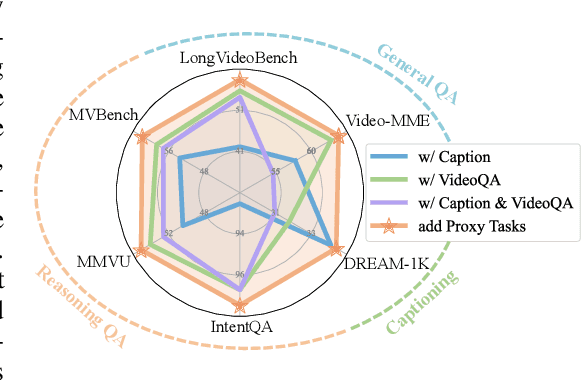
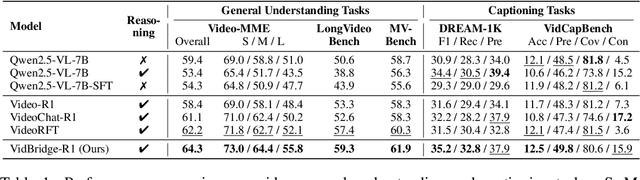
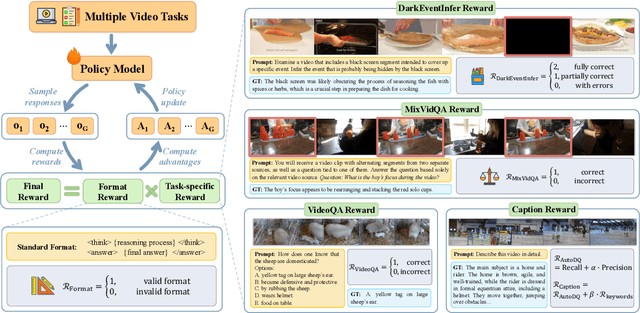
Recent advancements in multimodal large language models have successfully extended the Reason-Then-Respond paradigm to image-based reasoning, yet video-based reasoning remains an underdeveloped frontier, primarily due to the scarcity of high-quality reasoning-oriented data and effective training methodologies. To bridge this gap, we introduce DarkEventInfer and MixVidQA, two novel datasets specifically designed to stimulate the model's advanced video understanding and reasoning abilities. DarkEventinfer presents videos with masked event segments, requiring models to infer the obscured content based on contextual video cues. MixVidQA, on the other hand, presents interleaved video sequences composed of two distinct clips, challenging models to isolate and reason about one while disregarding the other. Leveraging these carefully curated training samples together with reinforcement learning guided by diverse reward functions, we develop VersaVid-R1, the first versatile video understanding and reasoning model under the Reason-Then-Respond paradigm capable of handling multiple-choice and open-ended question answering, as well as video captioning tasks. Extensive experiments demonstrate that VersaVid-R1 significantly outperforms existing models across a broad spectrum of benchmarks, covering video general understanding, cognitive reasoning, and captioning tasks.
Mavors: Multi-granularity Video Representation for Multimodal Large Language Model
Apr 14, 2025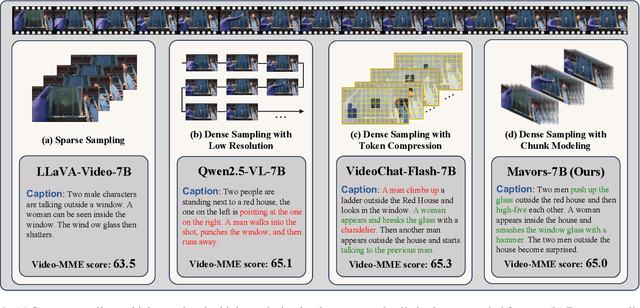
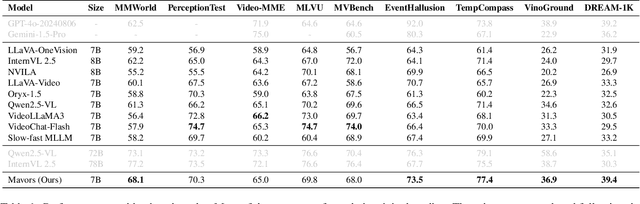
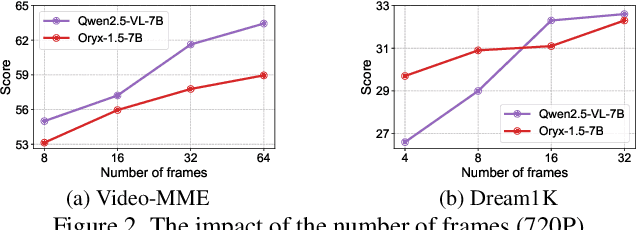
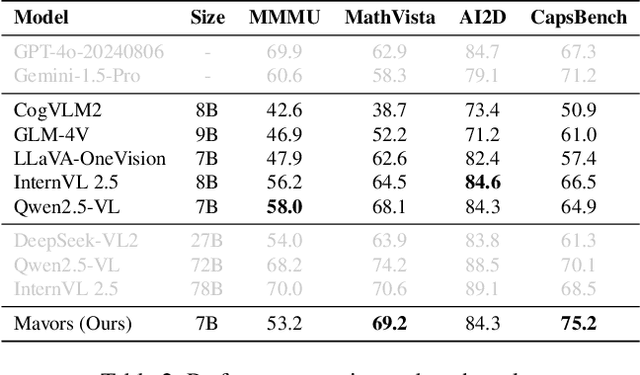
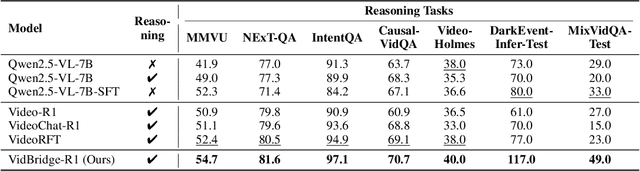
Long-context video understanding in multimodal large language models (MLLMs) faces a critical challenge: balancing computational efficiency with the retention of fine-grained spatio-temporal patterns. Existing approaches (e.g., sparse sampling, dense sampling with low resolution, and token compression) suffer from significant information loss in temporal dynamics, spatial details, or subtle interactions, particularly in videos with complex motion or varying resolutions. To address this, we propose $\mathbf{Mavors}$, a novel framework that introduces $\mathbf{M}$ulti-gr$\mathbf{a}$nularity $\mathbf{v}$ide$\mathbf{o}$ $\mathbf{r}$epre$\mathbf{s}$entation for holistic long-video modeling. Specifically, Mavors directly encodes raw video content into latent representations through two core components: 1) an Intra-chunk Vision Encoder (IVE) that preserves high-resolution spatial features via 3D convolutions and Vision Transformers, and 2) an Inter-chunk Feature Aggregator (IFA) that establishes temporal coherence across chunks using transformer-based dependency modeling with chunk-level rotary position encodings. Moreover, the framework unifies image and video understanding by treating images as single-frame videos via sub-image decomposition. Experiments across diverse benchmarks demonstrate Mavors' superiority in maintaining both spatial fidelity and temporal continuity, significantly outperforming existing methods in tasks requiring fine-grained spatio-temporal reasoning.
VidCapBench: A Comprehensive Benchmark of Video Captioning for Controllable Text-to-Video Generation
Feb 18, 2025The training of controllable text-to-video (T2V) models relies heavily on the alignment between videos and captions, yet little existing research connects video caption evaluation with T2V generation assessment. This paper introduces VidCapBench, a video caption evaluation scheme specifically designed for T2V generation, agnostic to any particular caption format. VidCapBench employs a data annotation pipeline, combining expert model labeling and human refinement, to associate each collected video with key information spanning video aesthetics, content, motion, and physical laws. VidCapBench then partitions these key information attributes into automatically assessable and manually assessable subsets, catering to both the rapid evaluation needs of agile development and the accuracy requirements of thorough validation. By evaluating numerous state-of-the-art captioning models, we demonstrate the superior stability and comprehensiveness of VidCapBench compared to existing video captioning evaluation approaches. Verification with off-the-shelf T2V models reveals a significant positive correlation between scores on VidCapBench and the T2V quality evaluation metrics, indicating that VidCapBench can provide valuable guidance for training T2V models. The project is available at https://github.com/VidCapBench/VidCapBench.
DAIS: Automatic Channel Pruning via Differentiable Annealing Indicator Search
Nov 04, 2020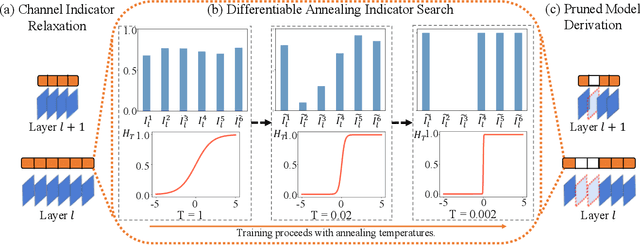
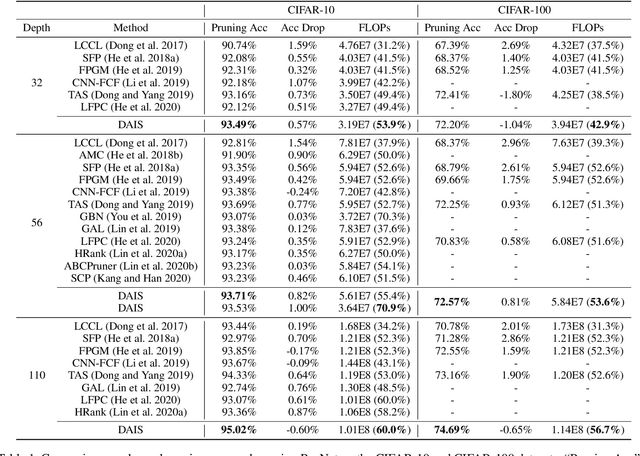
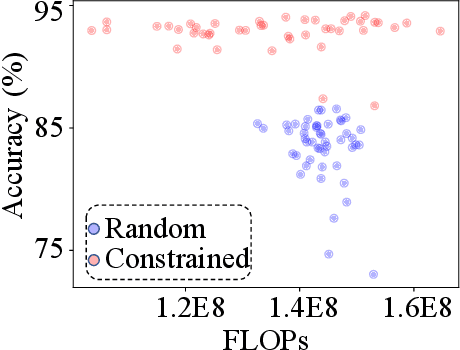
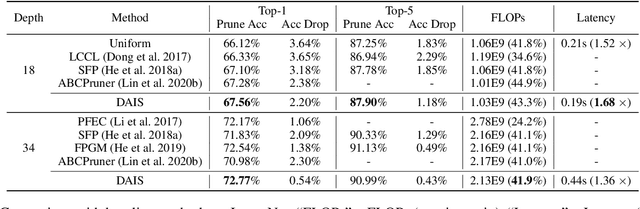
The convolutional neural network has achieved great success in fulfilling computer vision tasks despite large computation overhead against efficient deployment. Structured (channel) pruning is usually applied to reduce the model redundancy while preserving the network structure, such that the pruned network can be easily deployed in practice. However, existing structured pruning methods require hand-crafted rules which may lead to tremendous pruning space. In this paper, we introduce Differentiable Annealing Indicator Search (DAIS) that leverages the strength of neural architecture search in the channel pruning and automatically searches for the effective pruned model with given constraints on computation overhead. Specifically, DAIS relaxes the binarized channel indicators to be continuous and then jointly learns both indicators and model parameters via bi-level optimization. To bridge the non-negligible discrepancy between the continuous model and the target binarized model, DAIS proposes an annealing-based procedure to steer the indicator convergence towards binarized states. Moreover, DAIS designs various regularizations based on a priori structural knowledge to control the pruning sparsity and to improve model performance. Experimental results show that DAIS outperforms state-of-the-art pruning methods on CIFAR-10, CIFAR-100, and ImageNet.
Differentiable Feature Aggregation Search for Knowledge Distillation
Aug 02, 2020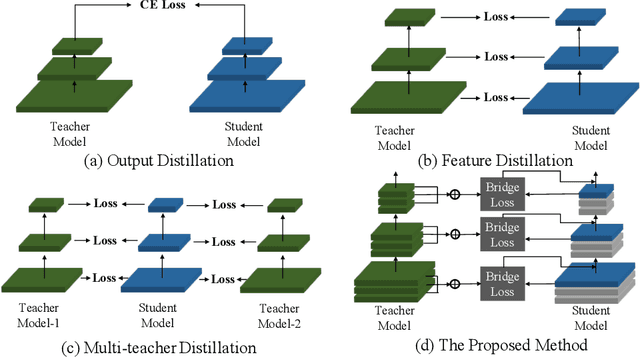
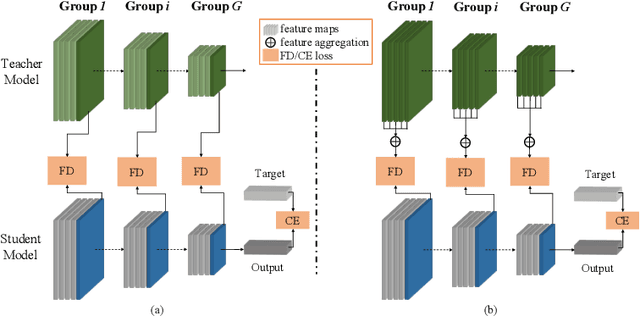

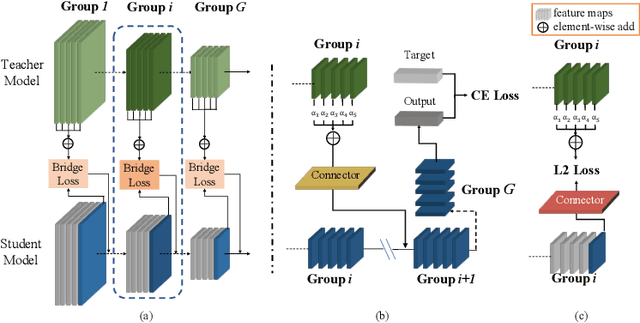
Knowledge distillation has become increasingly important in model compression. It boosts the performance of a miniaturized student network with the supervision of the output distribution and feature maps from a sophisticated teacher network. Some recent works introduce multi-teacher distillation to provide more supervision to the student network. However, the effectiveness of multi-teacher distillation methods are accompanied by costly computation resources. To tackle with both the efficiency and the effectiveness of knowledge distillation, we introduce the feature aggregation to imitate the multi-teacher distillation in the single-teacher distillation framework by extracting informative supervision from multiple teacher feature maps. Specifically, we introduce DFA, a two-stage Differentiable Feature Aggregation search method that motivated by DARTS in neural architecture search, to efficiently find the aggregations. In the first stage, DFA formulates the searching problem as a bi-level optimization and leverages a novel bridge loss, which consists of a student-to-teacher path and a teacher-to-student path, to find appropriate feature aggregations. The two paths act as two players against each other, trying to optimize the unified architecture parameters to the opposite directions while guaranteeing both expressivity and learnability of the feature aggregation simultaneously. In the second stage, DFA performs knowledge distillation with the derived feature aggregation. Experimental results show that DFA outperforms existing methods on CIFAR-100 and CINIC-10 datasets under various teacher-student settings, verifying the effectiveness and robustness of the design.
A New Perspective for Flexible Feature Gathering in Scene Text Recognition Via Character Anchor Pooling
Feb 10, 2020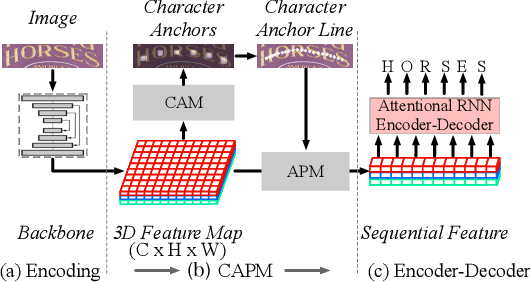
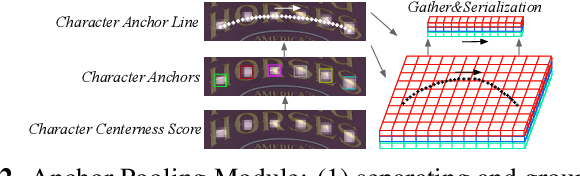
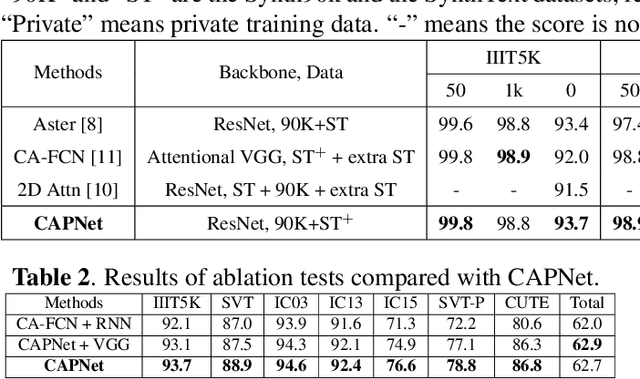
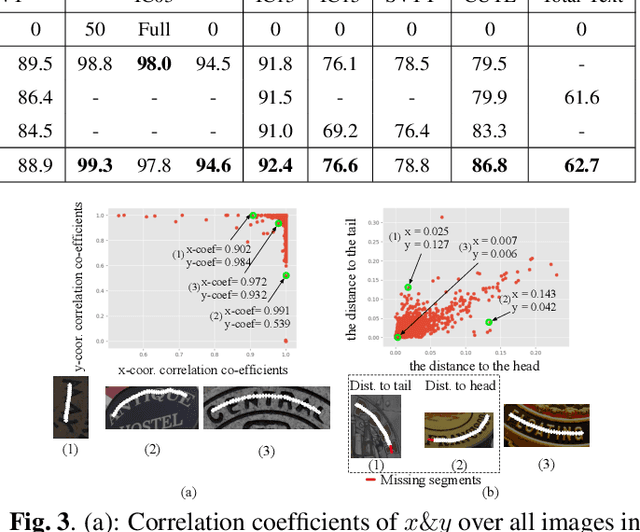
Irregular scene text recognition has attracted much attention from the research community, mainly due to the complexity of shapes of text in natural scene. However, recent methods either rely on shape-sensitive modules such as bounding box regression, or discard sequence learning. To tackle these issues, we propose a pair of coupling modules, termed as Character Anchoring Module (CAM) and Anchor Pooling Module (APM), to extract high-level semantics from two-dimensional space to form feature sequences. The proposed CAM localizes the text in a shape-insensitive way by design by anchoring characters individually. APM then interpolates and gathers features flexibly along the character anchors which enables sequence learning. The complementary modules realize a harmonic unification of spatial information and sequence learning. With the proposed modules, our recognition system surpasses previous state-of-the-art scores on irregular and perspective text datasets, including, ICDAR 2015, CUTE, and Total-Text, while paralleling state-of-the-art performance on regular text datasets.