 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIDDM: Bridging Synthetic-to-Real Domain Gap from Physics-Guided Diffusion for Real-world Image Dehazing
Apr 30, 2025Due to the domain gap between real-world and synthetic hazy images, current data-driven dehazing algorithms trained on synthetic datasets perform well on synthetic data but struggle to generalize to real-world scenarios. To address this challenge, we propose \textbf{I}mage \textbf{D}ehazing \textbf{D}iffusion \textbf{M}odels (IDDM), a novel diffusion process that incorporates the atmospheric scattering model into noise diffusion. IDDM aims to use the gradual haze formation process to help the denoising Unet robustly learn the distribution of clear images from the conditional input hazy images. We design a specialized training strategy centered around IDDM. Diffusion models are leveraged to bridge the domain gap from synthetic to real-world, while the atmospheric scattering model provides physical guidance for haze formation. During the forward process, IDDM simultaneously introduces haze and noise into clear images, and then robustly separates them during the sampling process. By training with physics-guided information, IDDM shows the ability of domain generalization, and effectively restores the real-world hazy images despite being trained on synthetic datasets. Extensive experiments demonstrate the effectiveness of our method through both quantitative and qualitative comparisons with state-of-the-art approaches.
GLAM: Global-Local Variation Awareness in Mamba-based World Model
Jan 21, 2025



Mimicking the real interaction trajectory in the inference of the world model has been shown to improve the sample efficiency of model-based reinforcement learning (MBRL) algorithms. Many methods directly use known state sequences for reasoning. However, this approach fails to enhance the quality of reasoning by capturing the subtle variation between states. Much like how humans infer trends in event development from this variation, in this work, we introduce Global-Local variation Awareness Mamba-based world model (GLAM) that improves reasoning quality by perceiving and predicting variation between states. GLAM comprises two Mambabased parallel reasoning modules, GMamba and LMamba, which focus on perceiving variation from global and local perspectives, respectively, during the reasoning process. GMamba focuses on identifying patterns of variation between states in the input sequence and leverages these patterns to enhance the prediction of future state variation. LMamba emphasizes reasoning about unknown information, such as rewards, termination signals, and visual representations, by perceiving variation in adjacent states. By integrating the strengths of the two modules, GLAM accounts for highervalue variation in environmental changes, providing the agent with more efficient imagination-based training. We demonstrate that our method outperforms existing methods in normalized human scores on the Atari 100k benchmark.
Unbiased Faster R-CNN for Single-source Domain Generalized Object Detection
May 24, 2024

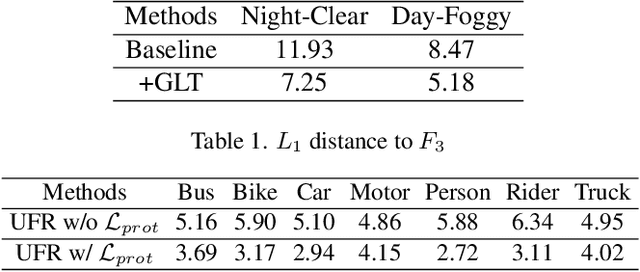

Single-source domain generalization (SDG) for object detection is a challenging yet essential task as the distribution bias of the unseen domain degrades the algorithm performance significantly. However, existing methods attempt to extract domain-invariant features, neglecting that the biased data leads the network to learn biased features that are non-causal and poorly generalizable. To this end, we propose an Unbiased Faster R-CNN (UFR) for generalizable feature learning. Specifically, we formulate SDG in object detection from a causal perspective and construct a Structural Causal Model (SCM) to analyze the data bias and feature bias in the task, which are caused by scene confounders and object attribute confounders. Based on the SCM, we design a Global-Local Transformation module for data augmentation, which effectively simulates domain diversity and mitigates the data bias. Additionally, we introduce a Causal Attention Learning module that incorporates a designed attention invariance loss to learn image-level features that are robust to scene confounders. Moreover, we develop a Causal Prototype Learning module with an explicit instance constraint and an implicit prototype constraint, which further alleviates the negative impact of object attribute confounders. Experimental results on five scenes demonstrate the prominent generalization ability of our method, with an improvement of 3.9% mAP on the Night-Clear scene.