 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGMT: A Robust Global Association Model for Multi-Target Multi-Camera Tracking
Paper and Code
Jul 01, 2024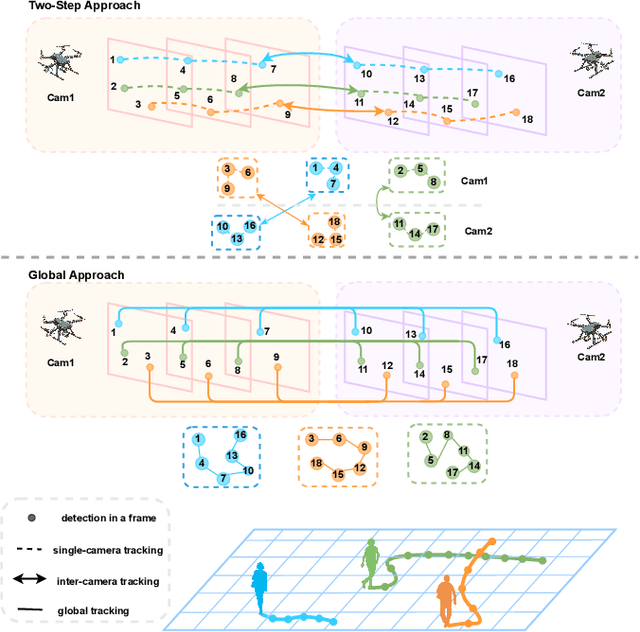
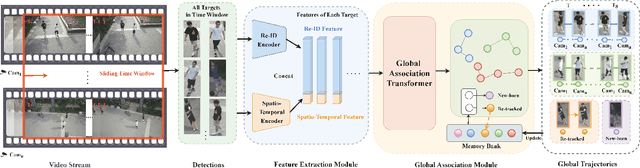

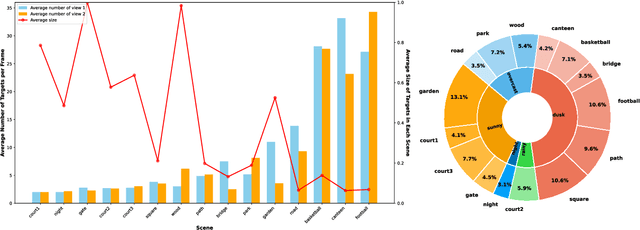
In the task of multi-target multi-camera (MTMC) tracking of pedestrians, the data association problem is a key issue and main challenge, especially with complications arising from camera movements, lighting variations, and obstructions. However, most MTMC models adopt two-step approaches, thus heavily depending on the results of the first-step tracking in practical applications. Moreover, the same targets crossing different cameras may exhibit significant appearance variations, which further increases the difficulty of cross-camera matching. To address the aforementioned issues, we propose a global online MTMC tracking model that addresses the dependency on the first tracking stage in two-step methods and enhances cross-camera matching. Specifically, we propose a transformer-based global MTMC association module to explore target associations across different cameras and frames, generating global trajectories directly. Additionally, to integrate the appearance and spatio-temporal features of targets, we propose a feature extraction and fusion module for MTMC tracking. This module enhances feature representation and establishes correlations between the features of targets across multiple cameras. To accommodate high scene diversity and complex lighting condition variations, we have established the VisionTrack dataset, which enables the development of models that are more generalized and robust to various environments. Our model demonstrates significant improvements over comparison methods on the VisionTrack dataset and others.