 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCanonical Face Embeddings
Jun 17, 2021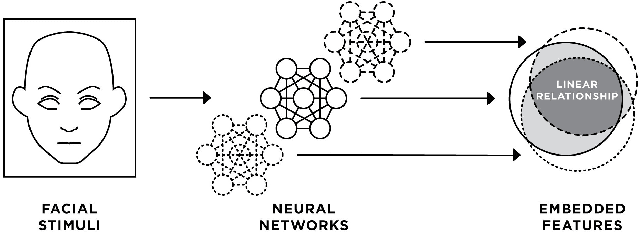
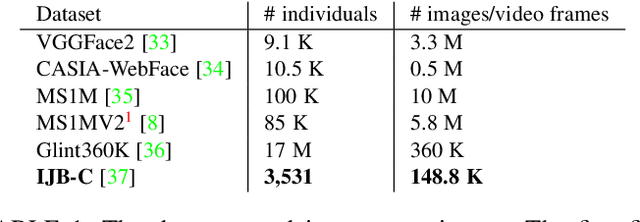
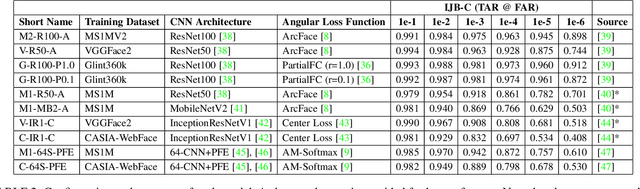
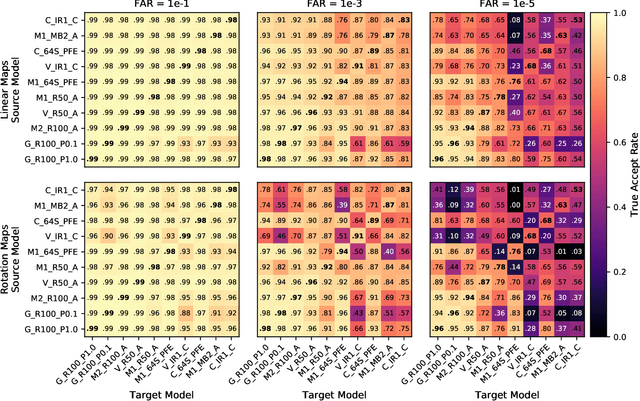
We present evidence that many common convolutional neural networks (CNNs) trained for face verification learn functions that are nearly equivalent under rotation. More specifically, we demonstrate that one face verification model's embeddings (i.e. last--layer activations) can be compared directly to another model's embeddings after only a rotation or linear transformation, with little performance penalty. This finding is demonstrated using IJB-C 1:1 verification across the combinations of ten modern off-the-shelf CNN-based face verification models which vary in training dataset, CNN architecture, way of using angular loss, or some combination of the 3, and achieve a mean true accept rate of 0.96 at a false accept rate of 0.01. When instead evaluating embeddings generated from two CNNs, where one CNN's embeddings are mapped with a linear transformation, the mean true accept rate drops to 0.95 using the same verification paradigm. Restricting these linear maps to only perform rotation produces a mean true accept rate of 0.91. These mappings' existence suggests that a common representation is learned by models with variation in training or structure. A discovery such as this likely has broad implications, and we provide an application in which face embeddings can be de-anonymized using a limited number of samples.
Common CNN-based Face Embedding Spaces are Equivalent
Oct 05, 2020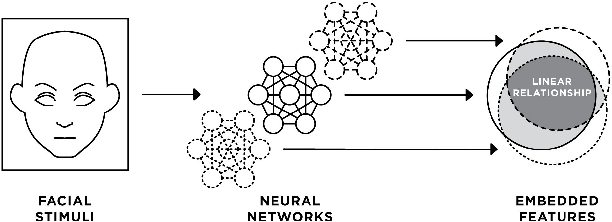
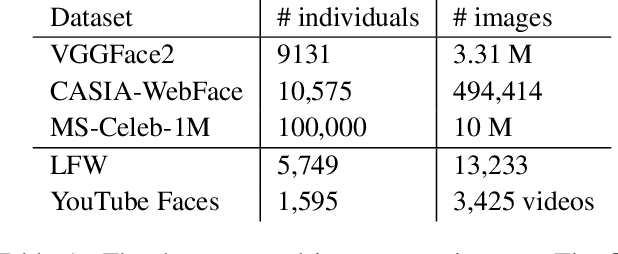

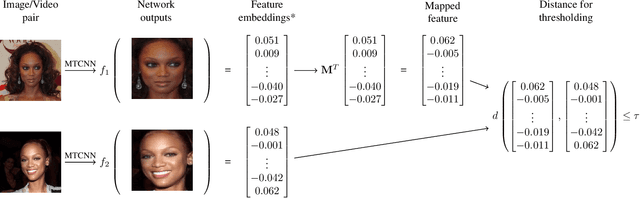
CNNs are the dominant method for creating face embeddings for recognition. It might be assumed that, since these networks are distinct, complex, nonlinear functions, that their embeddings are network specific, and thus have some degree of anonymity. However, recent research has shown that distinct networks' features can be directly mapped with little performance penalty (median 1.9% reduction across 90 distinct mappings) in the context of the 1,000 object ImageNet recognition task. This finding has revealed that embeddings coming from different systems can be meaningfully compared, provided the mapping. However, prior work only considered networks trained and tested on a closed set classification task. Here, we present evidence that a linear mapping between feature spaces can be easily discovered in the context of open set face recognition. Specifically, we demonstrate that the feature spaces of four face recognition models, of varying architecture and training datasets, can be mapped between with no more than a 1.0% penalty in recognition accuracy on LFW . This finding, which we also replicate on YouTube Faces, demonstrates that embeddings from different systems can be readily compared once the linear mapping is determined. In further analysis, fewer than 500 pairs of corresponding embeddings from two systems are required to calculate the full mapping between embedding spaces, and reducing the dimensionality of the mapping from 512 to 64 produces negligible performance penalty.