 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCanonical Face Embeddings
Jun 17, 2021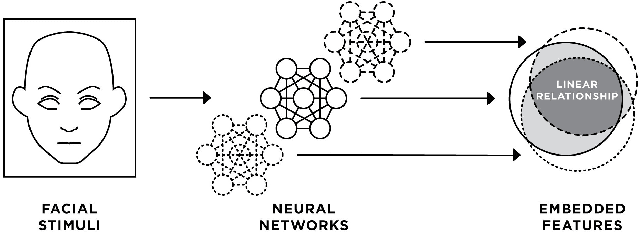
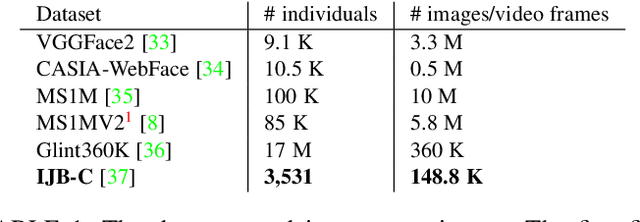
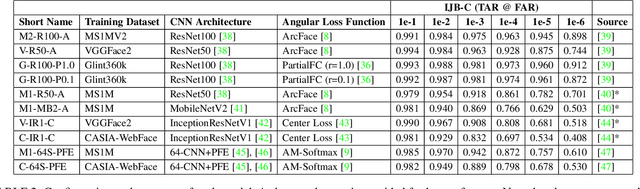
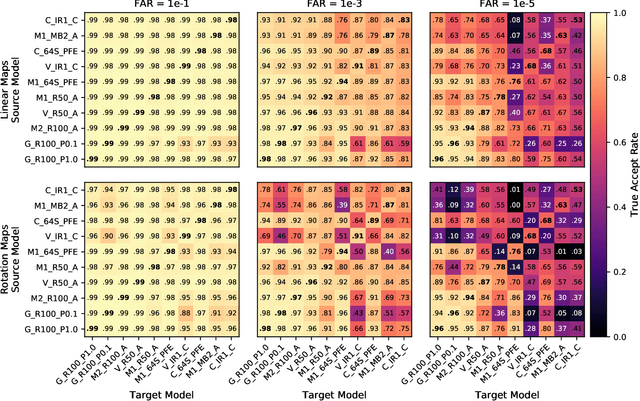
We present evidence that many common convolutional neural networks (CNNs) trained for face verification learn functions that are nearly equivalent under rotation. More specifically, we demonstrate that one face verification model's embeddings (i.e. last--layer activations) can be compared directly to another model's embeddings after only a rotation or linear transformation, with little performance penalty. This finding is demonstrated using IJB-C 1:1 verification across the combinations of ten modern off-the-shelf CNN-based face verification models which vary in training dataset, CNN architecture, way of using angular loss, or some combination of the 3, and achieve a mean true accept rate of 0.96 at a false accept rate of 0.01. When instead evaluating embeddings generated from two CNNs, where one CNN's embeddings are mapped with a linear transformation, the mean true accept rate drops to 0.95 using the same verification paradigm. Restricting these linear maps to only perform rotation produces a mean true accept rate of 0.91. These mappings' existence suggests that a common representation is learned by models with variation in training or structure. A discovery such as this likely has broad implications, and we provide an application in which face embeddings can be de-anonymized using a limited number of samples.
Locally Linear Attributes of ReLU Neural Networks
Nov 30, 2020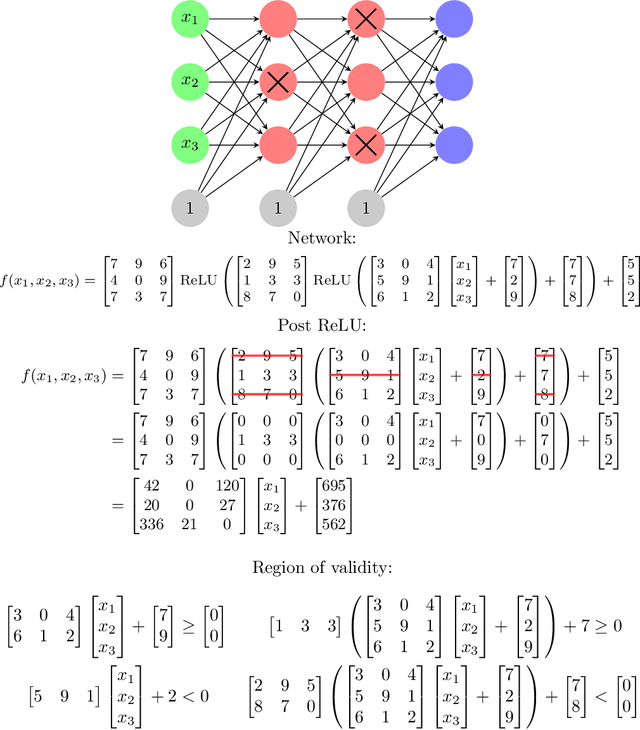
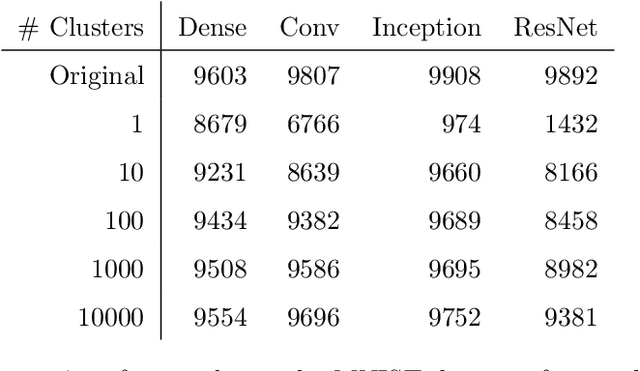
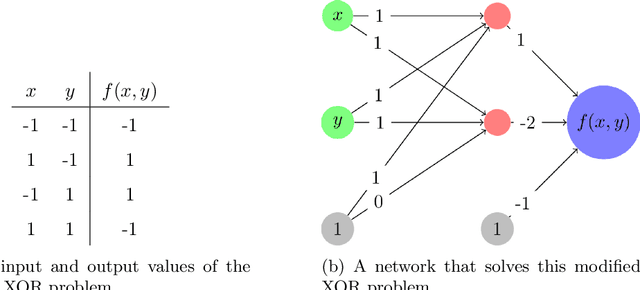
A ReLU neural network determines/is a continuous piecewise linear map from an input space to an output space. The weights in the neural network determine a decomposition of the input space into convex polytopes and on each of these polytopes the network can be described by a single affine mapping. The structure of the decomposition, together with the affine map attached to each polytope, can be analyzed to investigate the behavior of the associated neural network.
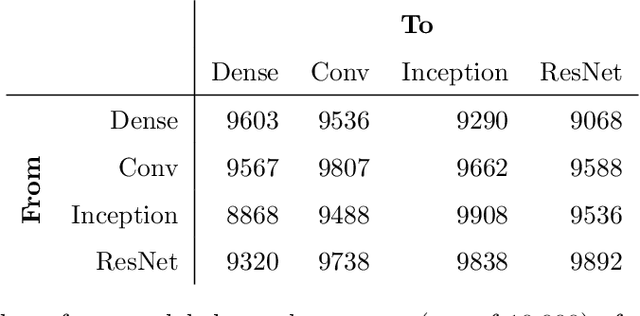
Common CNN-based Face Embedding Spaces are Equivalent
Oct 05, 2020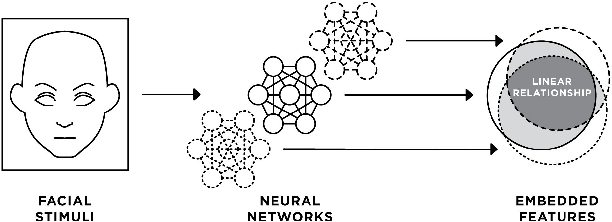
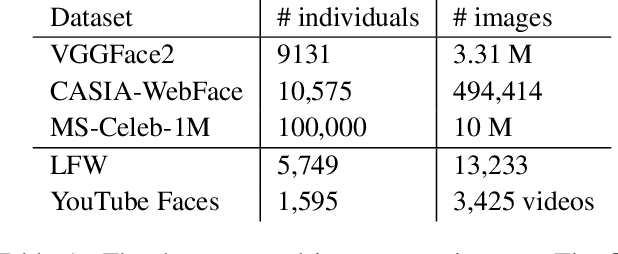

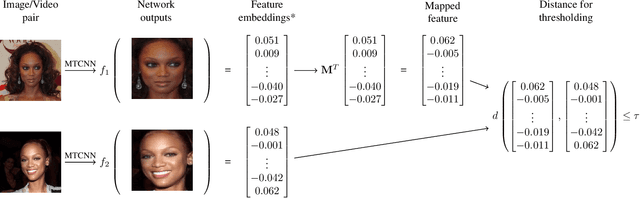
CNNs are the dominant method for creating face embeddings for recognition. It might be assumed that, since these networks are distinct, complex, nonlinear functions, that their embeddings are network specific, and thus have some degree of anonymity. However, recent research has shown that distinct networks' features can be directly mapped with little performance penalty (median 1.9% reduction across 90 distinct mappings) in the context of the 1,000 object ImageNet recognition task. This finding has revealed that embeddings coming from different systems can be meaningfully compared, provided the mapping. However, prior work only considered networks trained and tested on a closed set classification task. Here, we present evidence that a linear mapping between feature spaces can be easily discovered in the context of open set face recognition. Specifically, we demonstrate that the feature spaces of four face recognition models, of varying architecture and training datasets, can be mapped between with no more than a 1.0% penalty in recognition accuracy on LFW . This finding, which we also replicate on YouTube Faces, demonstrates that embeddings from different systems can be readily compared once the linear mapping is determined. In further analysis, fewer than 500 pairs of corresponding embeddings from two systems are required to calculate the full mapping between embedding spaces, and reducing the dimensionality of the mapping from 512 to 64 produces negligible performance penalty.
A Novel Pose Proposal Network and Refinement Pipeline for Better Object Pose Estimation
Apr 11, 2020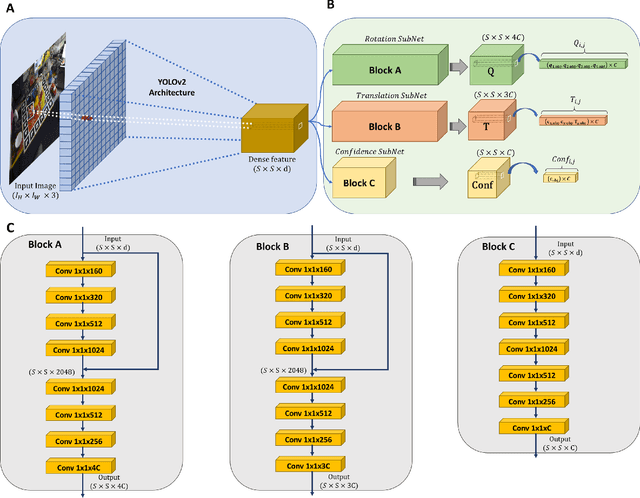

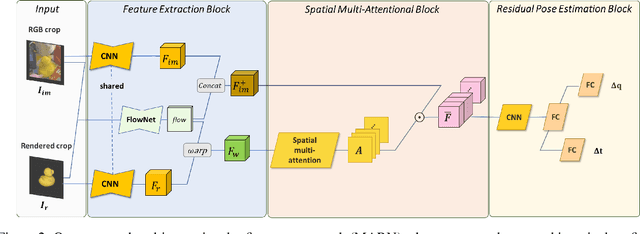
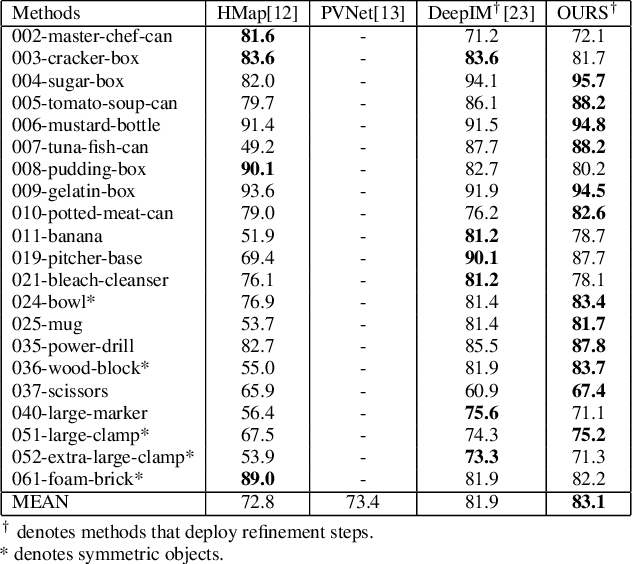
In this paper, we present a novel deep learning pipeline for 6D object pose estimation and refinement from RGB inputs. The first component of the pipeline leverages a region proposal framework to estimate multi-class single-shot 6D object poses directly from an RGB image and through a CNN-based encoder multi-decoders network. The second component, a multi-attentional pose refinement network (MARN), iteratively refines the estimated pose. MARN takes advantage of both visual and flow features to learn a relative transformation between an initially predicted pose and a target pose. MARN is further augmented by a spatial multi-attention block that emphasizes objects' discriminative feature parts. Experiments on three benchmarks for 6D pose estimation show that the proposed pipeline outperforms state-of-the-art RGB-based methods with competitive runtime performance.
End-to-end Learning Improves Static Object Geo-localization in Monocular Video
Apr 10, 2020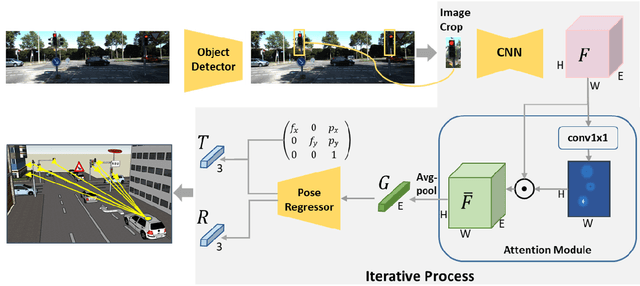
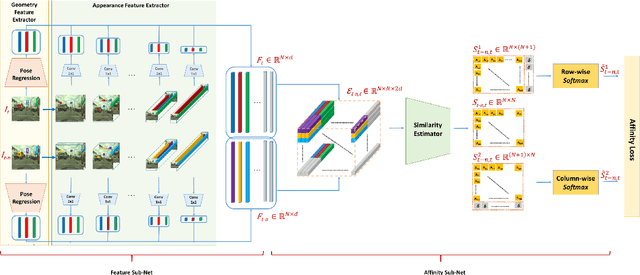
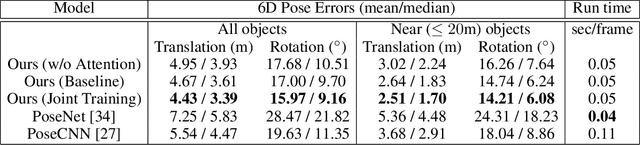
Accurately estimating the position of static objects, such as traffic lights, from the moving camera of a self-driving car is a challenging problem. In this work, we present a system that improves the localization of static objects by jointly-optimizing the components of the system via learning. Our system is comprised of networks that perform: 1) 6DoF object pose estimation from a single image, 2) association of objects between pairs of frames, and 3) multi-object tracking to produce the final geo-localization of the static objects within the scene. We evaluate our approach using a publicly-available data set, focusing on traffic lights due to data availability. For each component, we compare against contemporary alternatives and show significantly-improved performance. We also show that the end-to-end system performance is further improved via joint-training of the constituent models.
Looking Ahead: Anticipating Pedestrians Crossing with Future Frames Prediction
Oct 20, 2019

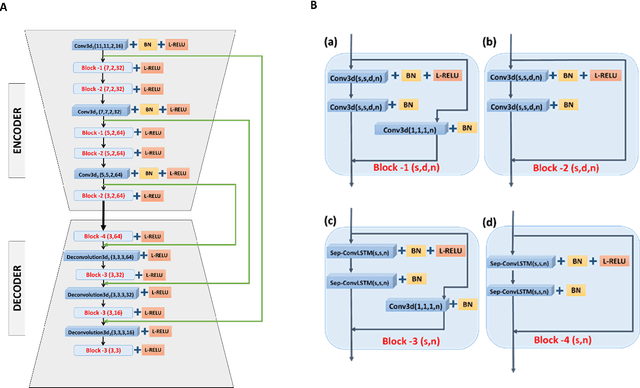
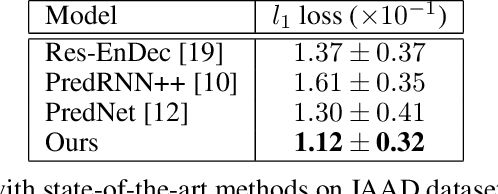
In this paper, we present an end-to-end future-prediction model that focuses on pedestrian safety. Specifically, our model uses previous video frames, recorded from the perspective of the vehicle, to predict if a pedestrian will cross in front of the vehicle. The long term goal of this work is to design a fully autonomous system that acts and reacts as a defensive human driver would --- predicting future events and reacting to mitigate risk. We focus on pedestrian-vehicle interactions because of the high risk of harm to the pedestrian if their actions are miss-predicted. Our end-to-end model consists of two stages: the first stage is an encoder/decoder network that learns to predict future video frames. The second stage is a deep spatio-temporal network that utilizes the predicted frames of the first stage to predict the pedestrian's future action. Our system achieves state-of-the-art accuracy on pedestrian behavior prediction and future frames prediction on the Joint Attention for Autonomous Driving (JAAD) dataset.