 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDrowned out by the noise: Evidence for Tracking-free Motion Prediction
Apr 16, 2021
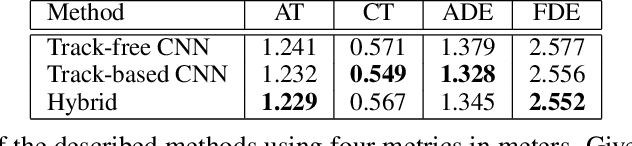

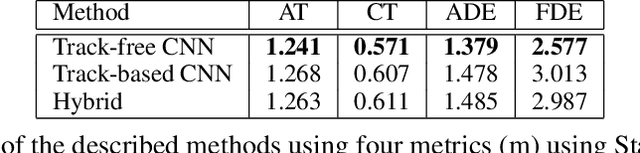
Autonomous driving consists of a multitude of interacting modules, where each module must contend with errors from the others. Typically, the motion prediction module depends on a robust tracking system to capture each agent's past movement. In this work, we systematically explore the importance of the tracking module for the motion prediction task and ultimately conclude that the tracking module is detrimental to overall motion prediction performance when the module is imperfect (with as low as 1% error). We explicitly compare models that use tracking information to models that do not across multiple scenarios and conditions. We find that the tracking information only improves performance in noise-free conditions. A noise-free tracker is unlikely to remain noise-free in real-world scenarios, and the inevitable noise will subsequently negatively affect performance. We thus argue future work should be mindful of noise when developing and testing motion/tracking modules, or that they should do away with the tracking component entirely.
A Novel Pose Proposal Network and Refinement Pipeline for Better Object Pose Estimation
Apr 11, 2020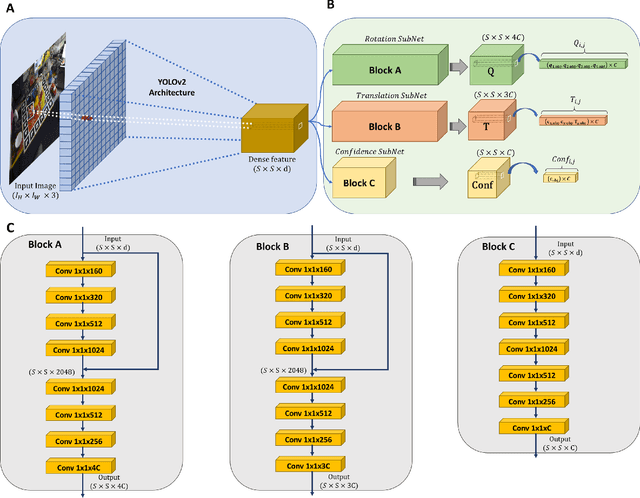

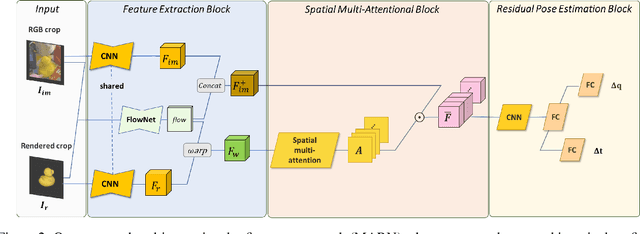
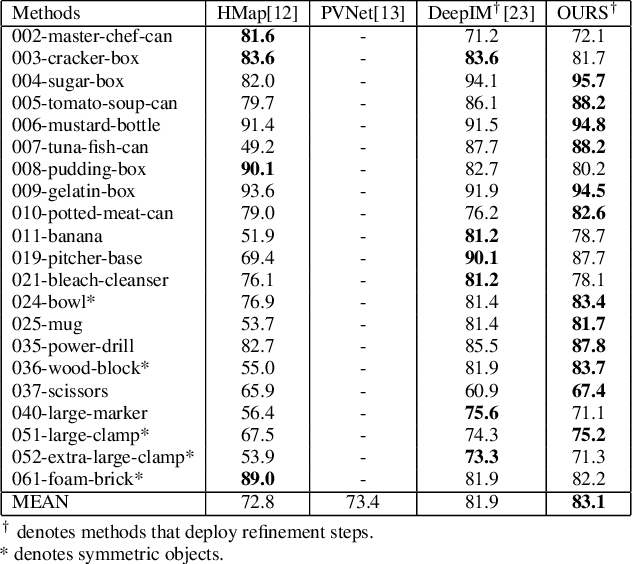
In this paper, we present a novel deep learning pipeline for 6D object pose estimation and refinement from RGB inputs. The first component of the pipeline leverages a region proposal framework to estimate multi-class single-shot 6D object poses directly from an RGB image and through a CNN-based encoder multi-decoders network. The second component, a multi-attentional pose refinement network (MARN), iteratively refines the estimated pose. MARN takes advantage of both visual and flow features to learn a relative transformation between an initially predicted pose and a target pose. MARN is further augmented by a spatial multi-attention block that emphasizes objects' discriminative feature parts. Experiments on three benchmarks for 6D pose estimation show that the proposed pipeline outperforms state-of-the-art RGB-based methods with competitive runtime performance.
End-to-end Learning Improves Static Object Geo-localization in Monocular Video
Apr 10, 2020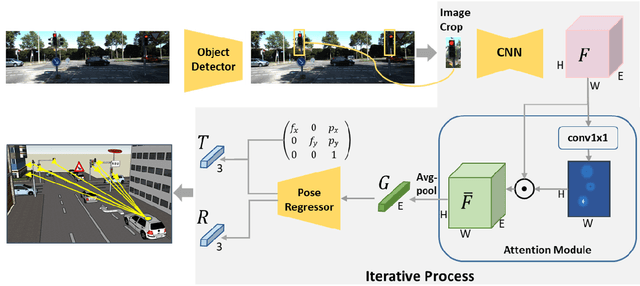
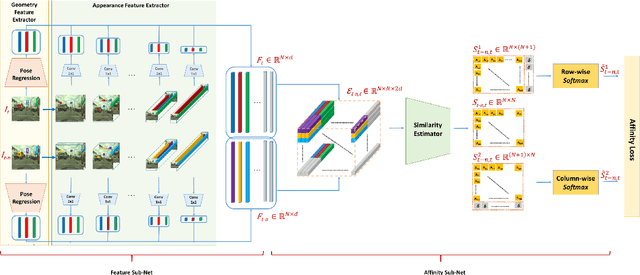
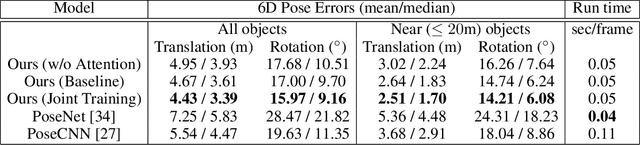
Accurately estimating the position of static objects, such as traffic lights, from the moving camera of a self-driving car is a challenging problem. In this work, we present a system that improves the localization of static objects by jointly-optimizing the components of the system via learning. Our system is comprised of networks that perform: 1) 6DoF object pose estimation from a single image, 2) association of objects between pairs of frames, and 3) multi-object tracking to produce the final geo-localization of the static objects within the scene. We evaluate our approach using a publicly-available data set, focusing on traffic lights due to data availability. For each component, we compare against contemporary alternatives and show significantly-improved performance. We also show that the end-to-end system performance is further improved via joint-training of the constituent models.
Looking Ahead: Anticipating Pedestrians Crossing with Future Frames Prediction
Oct 20, 2019

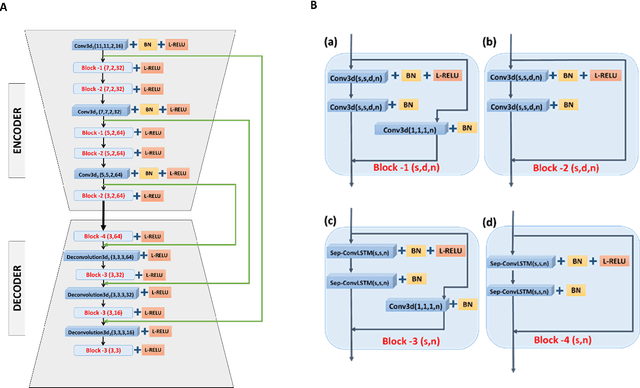
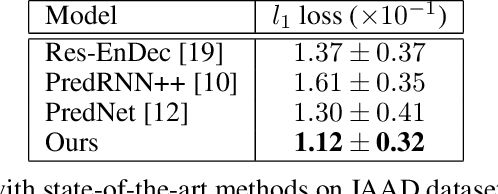
In this paper, we present an end-to-end future-prediction model that focuses on pedestrian safety. Specifically, our model uses previous video frames, recorded from the perspective of the vehicle, to predict if a pedestrian will cross in front of the vehicle. The long term goal of this work is to design a fully autonomous system that acts and reacts as a defensive human driver would --- predicting future events and reacting to mitigate risk. We focus on pedestrian-vehicle interactions because of the high risk of harm to the pedestrian if their actions are miss-predicted. Our end-to-end model consists of two stages: the first stage is an encoder/decoder network that learns to predict future video frames. The second stage is a deep spatio-temporal network that utilizes the predicted frames of the first stage to predict the pedestrian's future action. Our system achieves state-of-the-art accuracy on pedestrian behavior prediction and future frames prediction on the Joint Attention for Autonomous Driving (JAAD) dataset.
Comprehensive Evaluation of Deep Learning Architectures for Prediction of DNA/RNA Sequence Binding Specificities
Jan 29, 2019



Motivation: Deep learning architectures have recently demonstrated their power in predicting DNA- and RNA-binding specificities. Existing methods fall into three classes: Some are based on Convolutional Neural Networks (CNNs), others use Recurrent Neural Networks (RNNs), and others rely on hybrid architectures combining CNNs and RNNs. However, based on existing studies it is still unclear which deep learning architecture is achieving the best performance. Thus an in-depth analysis and evaluation of the different methods is needed to fully evaluate their relative. Results: In this study, We present a systematic exploration of various deep learning architectures for predicting DNA- and RNA-binding specificities. For this purpose, we present deepRAM, an end-to-end deep learning tool that provides an implementation of novel and previously proposed architectures; its fully automatic model selection procedure allows us to perform a fair and unbiased comparison of deep learning architectures. We find that an architecture that uses k-mer embedding to represent the sequence, a convolutional layer and a recurrent layer, outperforms all other methods in terms of model accuracy. Our work provides guidelines that will assist the practitioner in choosing the best architecture for the task at hand, and provides some insights on the differences between the models learned by convolutional and recurrent networks. In particular, we find that although recurrent networks improve model accuracy, this comes at the expense of a loss in the interpretability of the features learned by the model. Availability and implementation: The source code for deepRAM is available at https://github.com/MedChaabane/deepRAM