 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesigning Multimodal Datasets for NLP Challenges
May 12, 2021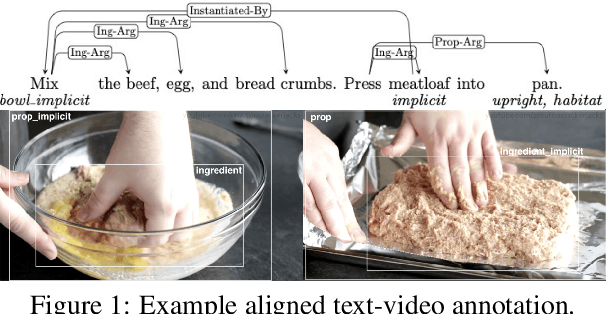


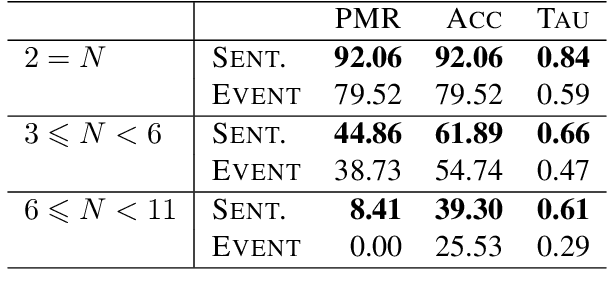
In this paper, we argue that the design and development of multimodal datasets for natural language processing (NLP) challenges should be enhanced in two significant respects: to more broadly represent commonsense semantic inferences; and to better reflect the dynamics of actions and events, through a substantive alignment of textual and visual information. We identify challenges and tasks that are reflective of linguistic and cognitive competencies that humans have when speaking and reasoning, rather than merely the performance of systems on isolated tasks. We introduce the distinction between challenge-based tasks and competence-based performance, and describe a diagnostic dataset, Recipe-to-Video Questions (R2VQ), designed for testing competence-based comprehension over a multimodal recipe collection (http://r2vq.org/). The corpus contains detailed annotation supporting such inferencing tasks and facilitating a rich set of question families that we use to evaluate NLP systems.