 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesigning Multimodal Datasets for NLP Challenges
May 12, 2021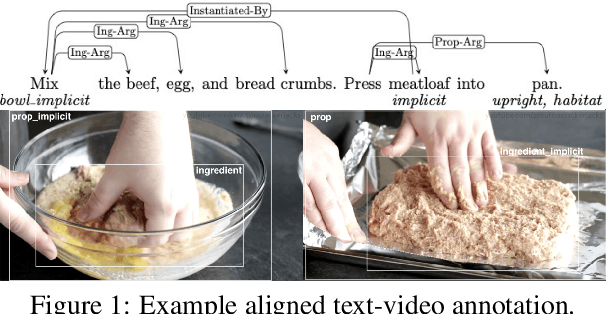


In this paper, we argue that the design and development of multimodal datasets for natural language processing (NLP) challenges should be enhanced in two significant respects: to more broadly represent commonsense semantic inferences; and to better reflect the dynamics of actions and events, through a substantive alignment of textual and visual information. We identify challenges and tasks that are reflective of linguistic and cognitive competencies that humans have when speaking and reasoning, rather than merely the performance of systems on isolated tasks. We introduce the distinction between challenge-based tasks and competence-based performance, and describe a diagnostic dataset, Recipe-to-Video Questions (R2VQ), designed for testing competence-based comprehension over a multimodal recipe collection (http://r2vq.org/). The corpus contains detailed annotation supporting such inferencing tasks and facilitating a rich set of question families that we use to evaluate NLP systems.
Assessing the Efficacy of Clinical Sentiment Analysis and Topic Extraction in Psychiatric Readmission Risk Prediction
Oct 09, 2019

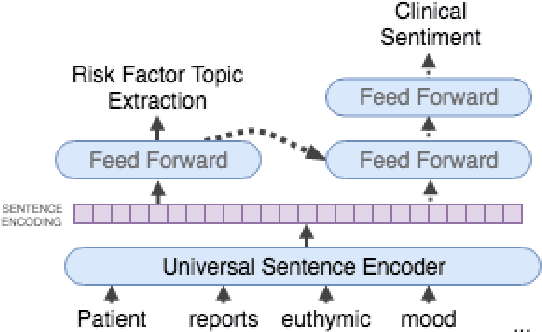
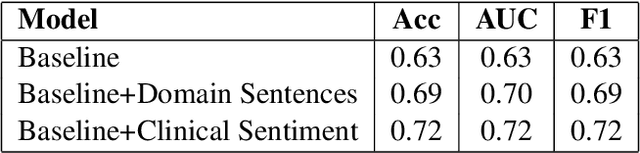
Predicting which patients are more likely to be readmitted to a hospital within 30 days after discharge is a valuable piece of information in clinical decision-making. Building a successful readmission risk classifier based on the content of Electronic Health Records (EHRs) has proved, however, to be a challenging task. Previously explored features include mainly structured information, such as sociodemographic data, comorbidity codes and physiological variables. In this paper we assess incorporating additional clinically interpretable NLP-based features such as topic extraction and clinical sentiment analysis to predict early readmission risk in psychiatry patients.
Distinguishing Clinical Sentiment: The Importance of Domain Adaptation in Psychiatric Patient Health Records
Apr 05, 2019
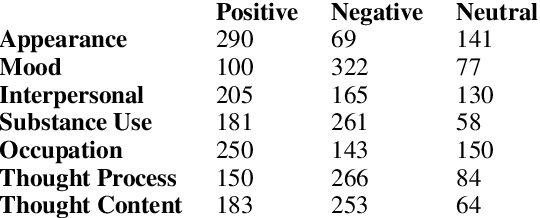
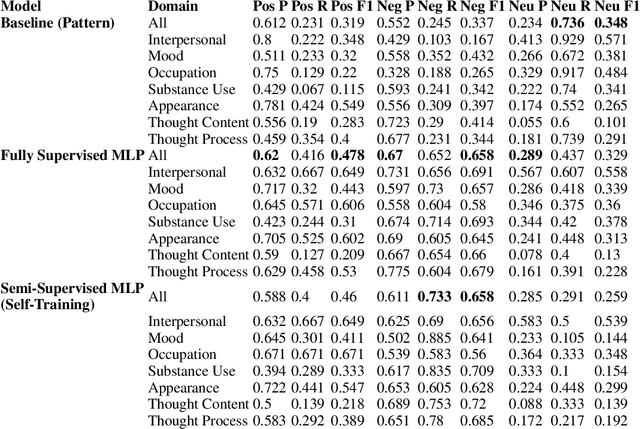

Recently natural language processing (NLP) tools have been developed to identify and extract salient risk indicators in electronic health records (EHRs). Sentiment analysis, although widely used in non-medical areas for improving decision making, has been studied minimally in the clinical setting. In this study, we undertook, to our knowledge, the first domain adaptation of sentiment analysis to psychiatric EHRs by defining psychiatric clinical sentiment, performing an annotation project, and evaluating multiple sentence-level sentiment machine learning (ML) models. Results indicate that off-the-shelf sentiment analysis tools fail in identifying clinically positive or negative polarity, and that the definition of clinical sentiment that we provide is learnable with relatively small amounts of training data. This project is an initial step towards further refining sentiment analysis methods for clinical use. Our long-term objective is to incorporate the results of this project as part of a machine learning model that predicts inpatient readmission risk. We hope that this work will initiate a discussion concerning domain adaptation of sentiment analysis to the clinical setting.
Analysis of Risk Factor Domains in Psychosis Patient Health Records
Sep 15, 2018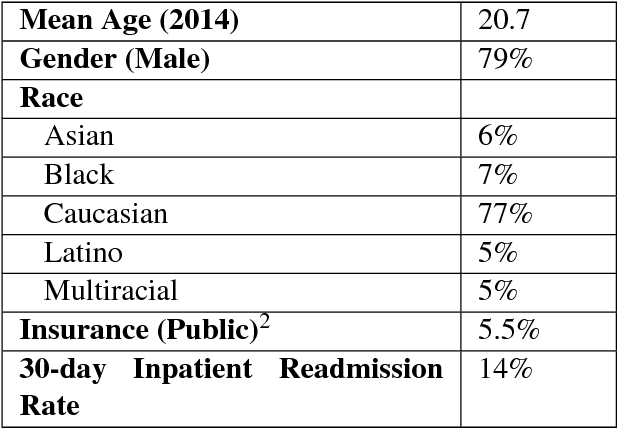
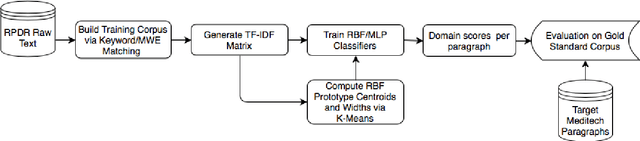
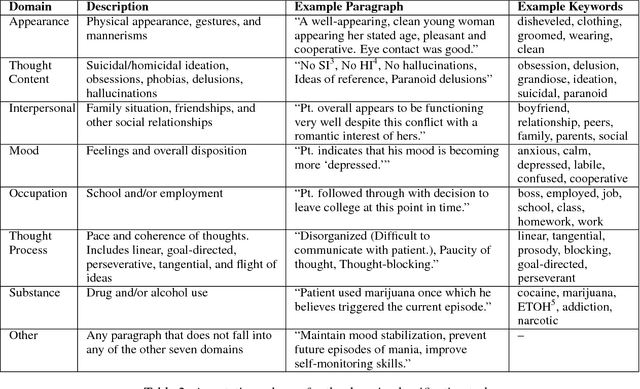
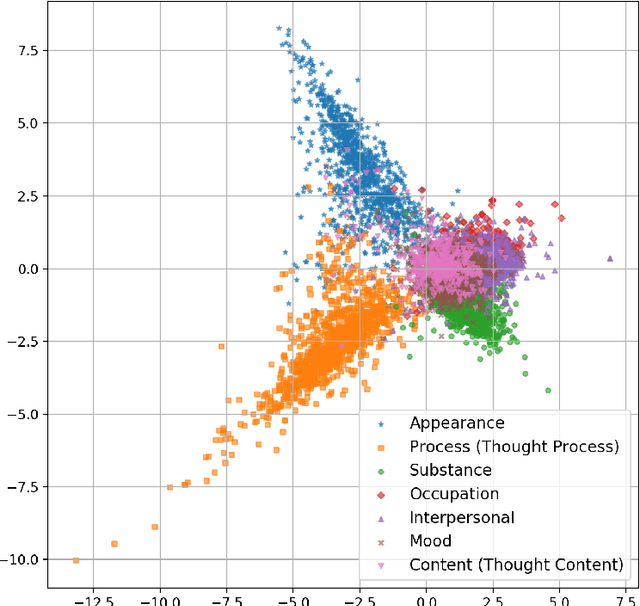
Readmission after discharge from a hospital is disruptive and costly, regardless of the reason. However, it can be particularly problematic for psychiatric patients, so predicting which patients may be readmitted is critically important but also very difficult. Clinical narratives in psychiatric electronic health records (EHRs) span a wide range of topics and vocabulary; therefore, a psychiatric readmission prediction model must begin with a robust and interpretable topic extraction component. We created a data pipeline for using document vector similarity metrics to perform topic extraction on psychiatric EHR data in service of our long-term goal of creating a readmission risk classifier. We show initial results for our topic extraction model and identify additional features we will be incorporating in the future.