 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing the Efficacy of Clinical Sentiment Analysis and Topic Extraction in Psychiatric Readmission Risk Prediction
Oct 09, 2019

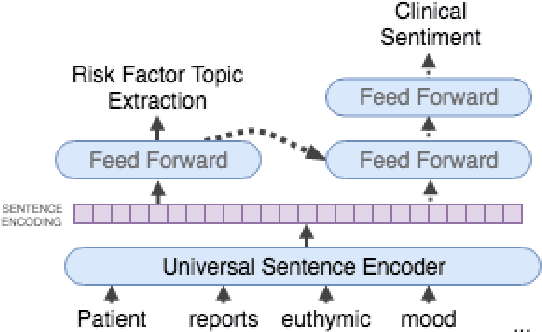
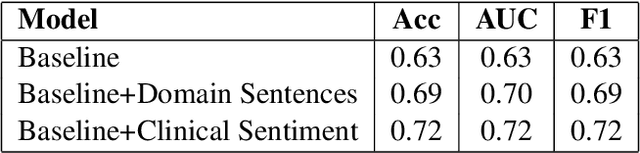
Predicting which patients are more likely to be readmitted to a hospital within 30 days after discharge is a valuable piece of information in clinical decision-making. Building a successful readmission risk classifier based on the content of Electronic Health Records (EHRs) has proved, however, to be a challenging task. Previously explored features include mainly structured information, such as sociodemographic data, comorbidity codes and physiological variables. In this paper we assess incorporating additional clinically interpretable NLP-based features such as topic extraction and clinical sentiment analysis to predict early readmission risk in psychiatry patients.
Analysis of Risk Factor Domains in Psychosis Patient Health Records
Sep 15, 2018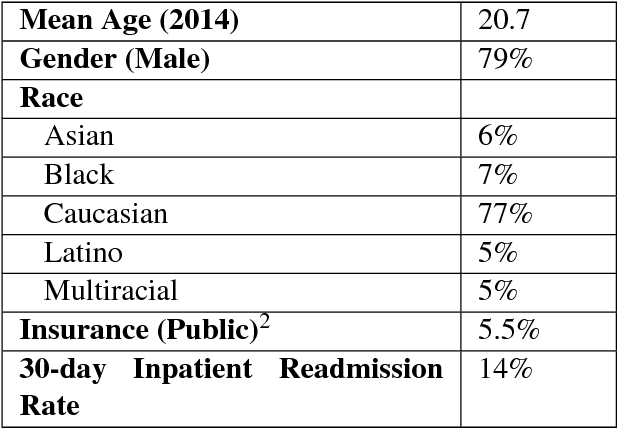
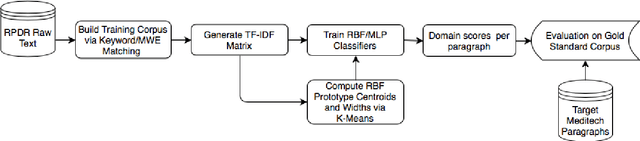
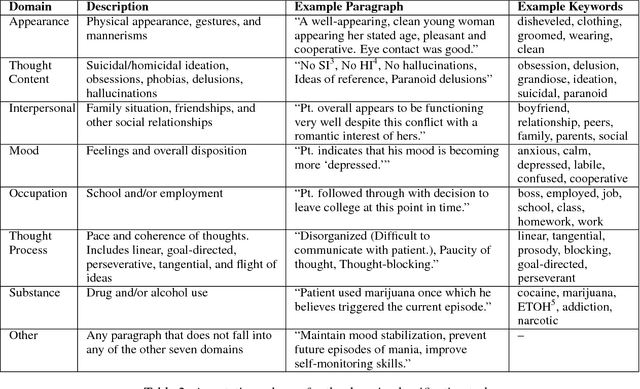
Readmission after discharge from a hospital is disruptive and costly, regardless of the reason. However, it can be particularly problematic for psychiatric patients, so predicting which patients may be readmitted is critically important but also very difficult. Clinical narratives in psychiatric electronic health records (EHRs) span a wide range of topics and vocabulary; therefore, a psychiatric readmission prediction model must begin with a robust and interpretable topic extraction component. We created a data pipeline for using document vector similarity metrics to perform topic extraction on psychiatric EHR data in service of our long-term goal of creating a readmission risk classifier. We show initial results for our topic extraction model and identify additional features we will be incorporating in the future.
Diverse Large-Scale ITS Dataset Created from Continuous Learning for Real-Time Vehicle Detection
Oct 07, 2015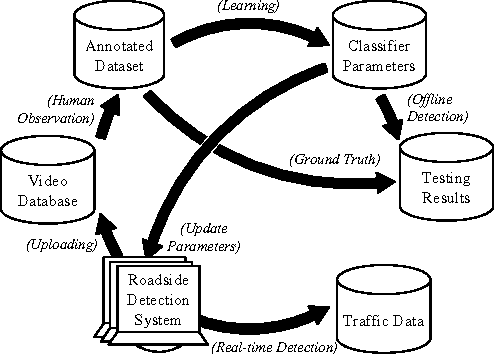

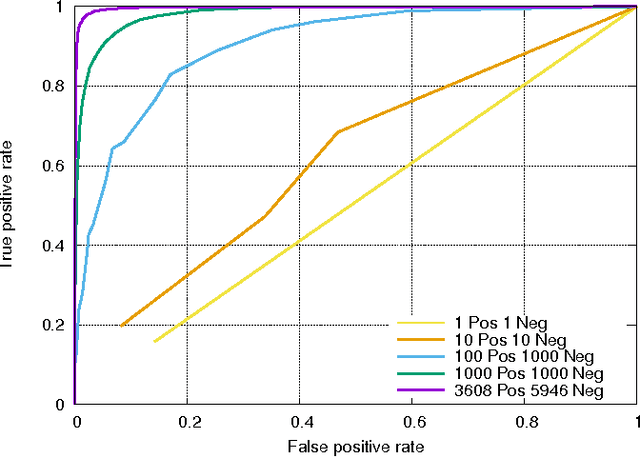

In traffic engineering, vehicle detectors are trained on limited datasets resulting in poor accuracy when deployed in real world applications. Annotating large-scale high quality datasets is challenging. Typically, these datasets have limited diversity; they do not reflect the real-world operating environment. There is a need for a large-scale, cloud based positive and negative mining (PNM) process and a large-scale learning and evaluation system for the application of traffic event detection. The proposed positive and negative mining process addresses the quality of crowd sourced ground truth data through machine learning review and human feedback mechanisms. The proposed learning and evaluation system uses a distributed cloud computing framework to handle data-scaling issues associated with large numbers of samples and a high-dimensional feature space. The system is trained using AdaBoost on $1,000,000$ Haar-like features extracted from $70,000$ annotated video frames. The trained real-time vehicle detector achieves an accuracy of at least $95\%$ for $1/2$ and about $78\%$ for $19/20$ of the time when tested on approximately $7,500,000$ video frames. At the end of 2015, the dataset is expect to have over one billion annotated video frames.