 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTMR: Evaluating NER Recall on Tough Mentions
Paper and Code

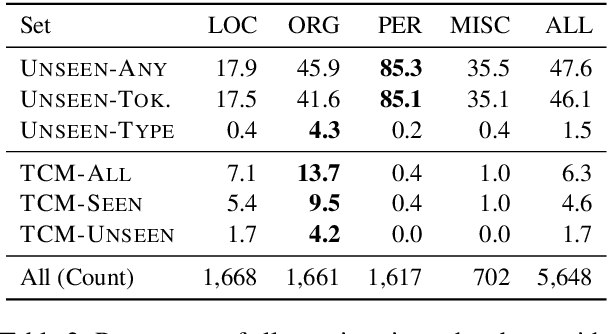
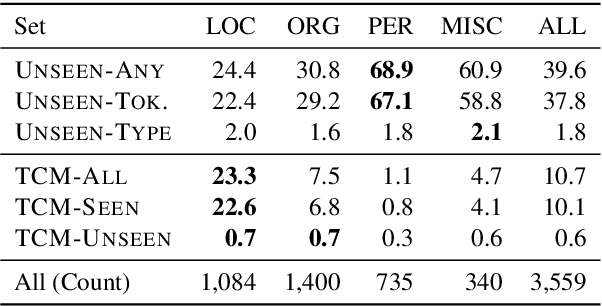
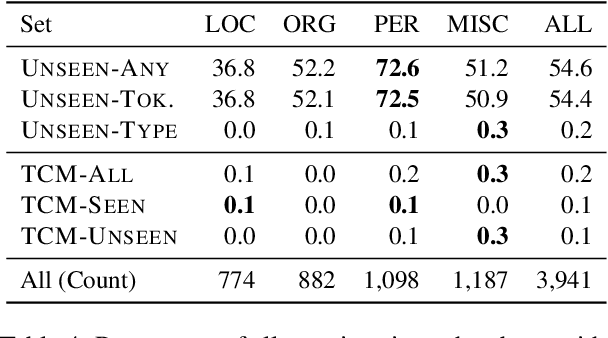
We propose the Tough Mentions Recall (TMR) metrics to supplement traditional named entity recognition (NER) evaluation by examining recall on specific subsets of "tough" mentions: unseen mentions, those whose tokens or token/type combination were not observed in training, and type-confusable mentions, token sequences with multiple entity types in the test data. We demonstrate the usefulness of these metrics by evaluating corpora of English, Spanish, and Dutch using five recent neural architectures. We identify subtle differences between the performance of BERT and Flair on two English NER corpora and identify a weak spot in the performance of current models in Spanish. We conclude that the TMR metrics enable differentiation between otherwise similar-scoring systems and identification of patterns in performance that would go unnoticed from overall precision, recall, and F1.