 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnginuity: Building an Open Multi-Domain Dataset of Complex Engineering Diagrams
Jan 19, 2026We propose Enginuity - the first open, large-scale, multi-domain engineering diagram dataset with comprehensive structural annotations designed for automated diagram parsing. By capturing hierarchical component relationships, connections, and semantic elements across diverse engineering domains, our proposed dataset would enable multimodal large language models to address critical downstream tasks including structured diagram parsing, cross-modal information retrieval, and AI-assisted engineering simulation. Enginuity would be transformative for AI for Scientific Discovery by enabling artificial intelligence systems to comprehend and manipulate the visual-structural knowledge embedded in engineering diagrams, breaking down a fundamental barrier that currently prevents AI from fully participating in scientific workflows where diagram interpretation, technical drawing analysis, and visual reasoning are essential for hypothesis generation, experimental design, and discovery.
HARNESS: Human-Agent Risk Navigation and Event Safety System for Proactive Hazard Forecasting in High-Risk DOE Environments
Nov 13, 2025Operational safety at mission-critical work sites is a top priority given the complex and hazardous nature of daily tasks. This paper presents the Human-Agent Risk Navigation and Event Safety System (HARNESS), a modular AI framework designed to forecast hazardous events and analyze operational risks in U.S. Department of Energy (DOE) environments. HARNESS integrates Large Language Models (LLMs) with structured work data, historical event retrieval, and risk analysis to proactively identify potential hazards. A human-in-the-loop mechanism allows subject matter experts (SMEs) to refine predictions, creating an adaptive learning loop that enhances performance over time. By combining SME collaboration with iterative agentic reasoning, HARNESS improves the reliability and efficiency of predictive safety systems. Preliminary deployment shows promising results, with future work focusing on quantitative evaluation of accuracy, SME agreement, and decision latency reduction.
Simultaneous Reward Distillation and Preference Learning: Get You a Language Model Who Can Do Both
Oct 11, 2024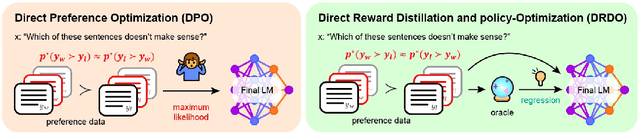
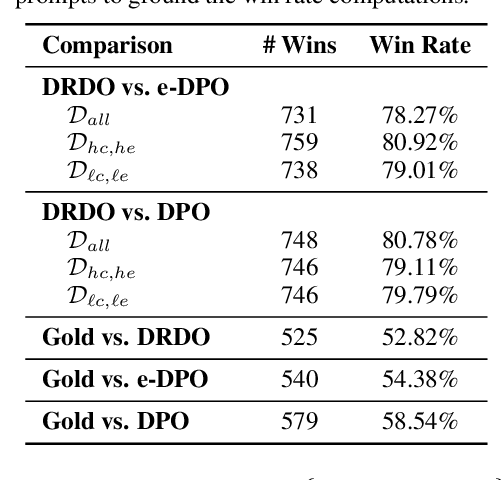
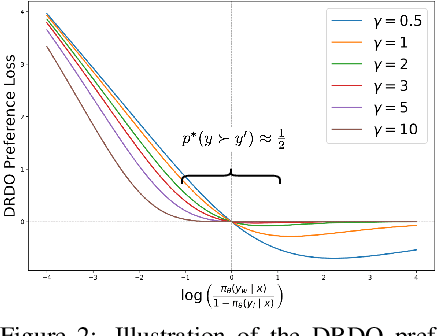
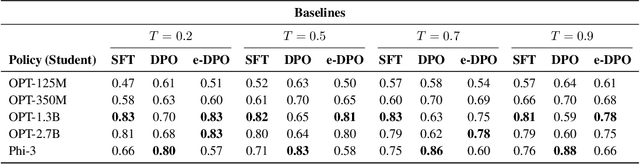
Reward modeling of human preferences is one of the cornerstones of building usable generative large language models (LLMs). While traditional RLHF-based alignment methods explicitly maximize the expected rewards from a separate reward model, more recent supervised alignment methods like Direct Preference Optimization (DPO) circumvent this phase to avoid problems including model drift and reward overfitting. Although popular due to its simplicity, DPO and similar direct alignment methods can still lead to degenerate policies, and rely heavily on the Bradley-Terry-based preference formulation to model reward differences between pairs of candidate outputs. This formulation is challenged by non-deterministic or noisy preference labels, for example human scoring of two candidate outputs is of low confidence. In this paper, we introduce DRDO (Direct Reward Distillation and policy-Optimization), a supervised knowledge distillation-based preference alignment method that simultaneously models rewards and preferences to avoid such degeneracy. DRDO directly mimics rewards assigned by an oracle while learning human preferences from a novel preference likelihood formulation. Our experimental results on the Ultrafeedback and TL;DR datasets demonstrate that policies trained using DRDO surpass previous methods such as DPO and e-DPO in terms of expected rewards and are more robust, on average, to noisy preference signals as well as out-of-distribution (OOD) settings.