 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLEN: General-Purpose Event Detection for Thousands of Types
Mar 20, 2023



The development of event extraction systems has been hindered by the absence of wide-coverage, large-scale datasets. To make event extraction systems more accessible, we build a general-purpose event detection dataset GLEN, which covers 3,465 different event types, making it over 20x larger in ontology than any current dataset. GLEN is created by utilizing the DWD Overlay, which provides a mapping between Wikidata Qnodes and PropBank rolesets. This enables us to use the abundant existing annotation for PropBank as distant supervision. In addition, we also propose a new multi-stage event detection model specifically designed to handle the large ontology size and partial labels in GLEN. We show that our model exhibits superior performance (~10% F1 gain) compared to both conventional classification baselines and newer definition-based models. Finally, we perform error analysis and show that label noise is still the largest challenge for improving performance.
A corpus of preposition supersenses in English web reviews
May 08, 2016
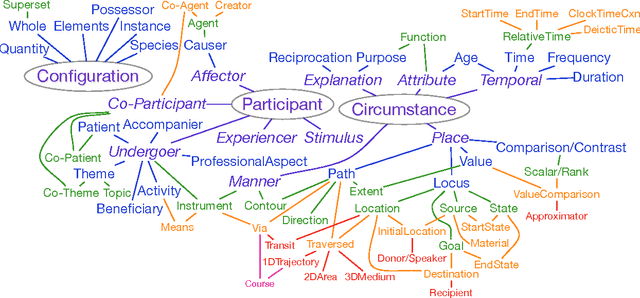

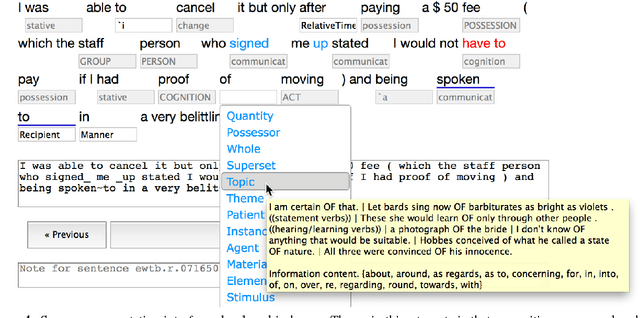
We present the first corpus annotated with preposition supersenses, unlexicalized categories for semantic functions that can be marked by English prepositions (Schneider et al., 2015). That scheme improves upon its predecessors to better facilitate comprehensive manual annotation. Moreover, unlike the previous schemes, the preposition supersenses are organized hierarchically. Our data will be publicly released on the web upon publication.