 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Machine Translation for the Indigenous Languages of the Americas: An Introduction
Jun 11, 2023Neural models have drastically advanced state of the art for machine translation (MT) between high-resource languages. Traditionally, these models rely on large amounts of training data, but many language pairs lack these resources. However, an important part of the languages in the world do not have this amount of data. Most languages from the Americas are among them, having a limited amount of parallel and monolingual data, if any. Here, we present an introduction to the interested reader to the basic challenges, concepts, and techniques that involve the creation of MT systems for these languages. Finally, we discuss the recent advances and findings and open questions, product of an increased interest of the NLP community in these languages.
Human-AI Collaboration via Conditional Delegation: A Case Study of Content Moderation
Apr 25, 2022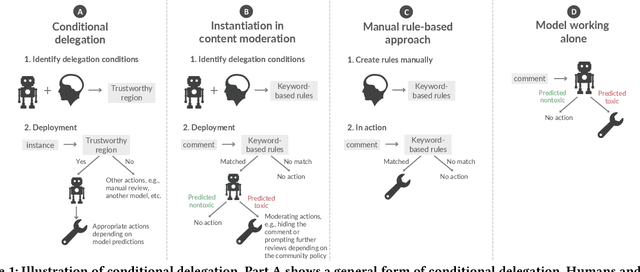

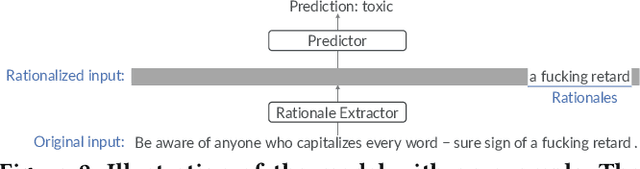
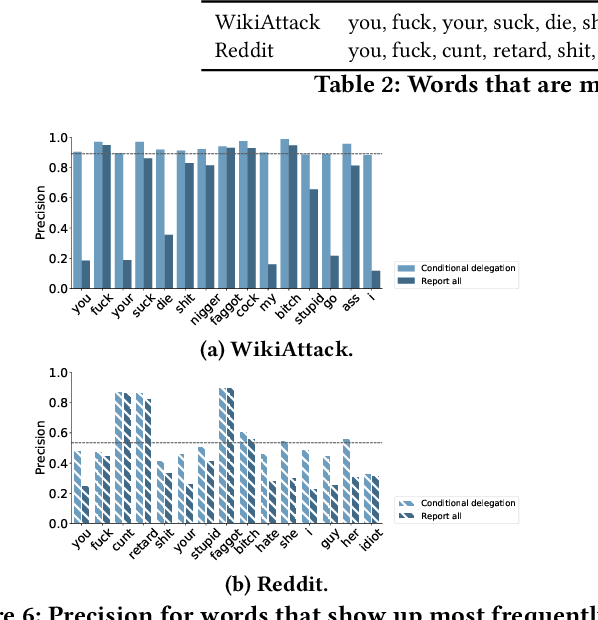
Despite impressive performance in many benchmark datasets, AI models can still make mistakes, especially among out-of-distribution examples. It remains an open question how such imperfect models can be used effectively in collaboration with humans. Prior work has focused on AI assistance that helps people make individual high-stakes decisions, which is not scalable for a large amount of relatively low-stakes decisions, e.g., moderating social media comments. Instead, we propose conditional delegation as an alternative paradigm for human-AI collaboration where humans create rules to indicate trustworthy regions of a model. Using content moderation as a testbed, we develop novel interfaces to assist humans in creating conditional delegation rules and conduct a randomized experiment with two datasets to simulate in-distribution and out-of-distribution scenarios. Our study demonstrates the promise of conditional delegation in improving model performance and provides insights into design for this novel paradigm, including the effect of AI explanations.
Don't Rule Out Monolingual Speakers: A Method For Crowdsourcing Machine Translation Data
Jun 12, 2021



High-performing machine translation (MT) systems can help overcome language barriers while making it possible for everyone to communicate and use language technologies in the language of their choice. However, such systems require large amounts of parallel sentences for training, and translators can be difficult to find and expensive. Here, we present a data collection strategy for MT which, in contrast, is cheap and simple, as it does not require bilingual speakers. Based on the insight that humans pay specific attention to movements, we use graphics interchange formats (GIFs) as a pivot to collect parallel sentences from monolingual annotators. We use our strategy to collect data in Hindi, Tamil and English. As a baseline, we also collect data using images as a pivot. We perform an intrinsic evaluation by manually evaluating a subset of the sentence pairs and an extrinsic evaluation by finetuning mBART on the collected data. We find that sentences collected via GIFs are indeed of higher quality.