 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreference Learning from Physics-Based Feedback: Tuning Language Models to Design BCC/B2 Superalloys
Nov 15, 2025We apply preference learning to the task of language model-guided design of novel structural alloys. In contrast to prior work that focuses on generating stable inorganic crystals, our approach targets the synthesizeability of a specific structural class: BCC/B2 superalloys, an underexplored family of materials with potential applications in extreme environments. Using three open-weight models (LLaMA-3.1, Gemma-2, and OLMo-2), we demonstrate that language models can be optimized for multiple design objectives using a single, unified reward signal through Direct Preference Optimization (DPO). Unlike prior approaches that rely on heuristic or human-in-the-loop feedback (costly), our reward signal is derived from thermodynamic phase calculations, offering a scientifically grounded criterion for model tuning. To our knowledge, this is the first demonstration of preference-tuning a language model using physics-grounded feedback for structural alloy design. The resulting framework is general and extensible, providing a path forward for intelligent design-space exploration across a range of physical science domains.
Retrieving Versus Understanding Extractive Evidence in Few-Shot Learning
Feb 19, 2025



A key aspect of alignment is the proper use of within-document evidence to construct document-level decisions. We analyze the relationship between the retrieval and interpretation of within-document evidence for large language model in a few-shot setting. Specifically, we measure the extent to which model prediction errors are associated with evidence retrieval errors with respect to gold-standard human-annotated extractive evidence for five datasets, using two popular closed proprietary models. We perform two ablation studies to investigate when both label prediction and evidence retrieval errors can be attributed to qualities of the relevant evidence. We find that there is a strong empirical relationship between model prediction and evidence retrieval error, but that evidence retrieval error is mostly not associated with evidence interpretation error--a hopeful sign for downstream applications built on this mechanism.
Toward Reliable Ad-hoc Scientific Information Extraction: A Case Study on Two Materials Datasets
Jun 08, 2024



We explore the ability of GPT-4 to perform ad-hoc schema based information extraction from scientific literature. We assess specifically whether it can, with a basic prompting approach, replicate two existing material science datasets, given the manuscripts from which they were originally manually extracted. We employ materials scientists to perform a detailed manual error analysis to assess where the model struggles to faithfully extract the desired information, and draw on their insights to suggest research directions to address this broadly important task.
Learning to Ignore Adversarial Attacks
May 23, 2022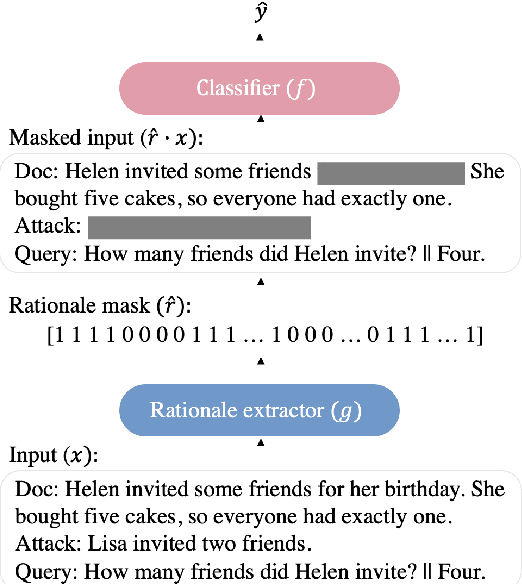

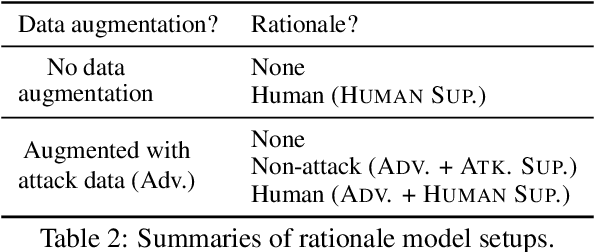
Despite the strong performance of current NLP models, they can be brittle against adversarial attacks. To enable effective learning against adversarial inputs, we introduce the use of rationale models that can explicitly learn to ignore attack tokens. We find that the rationale models can successfully ignore over 90\% of attack tokens. This approach leads to consistent sizable improvements ($\sim$10\%) over baseline models in robustness on three datasets for both BERT and RoBERTa, and also reliably outperforms data augmentation with adversarial examples alone. In many cases, we find that our method is able to close the gap between model performance on a clean test set and an attacked test set and hence reduce the effect of adversarial attacks.
Human-AI Collaboration via Conditional Delegation: A Case Study of Content Moderation
Apr 25, 2022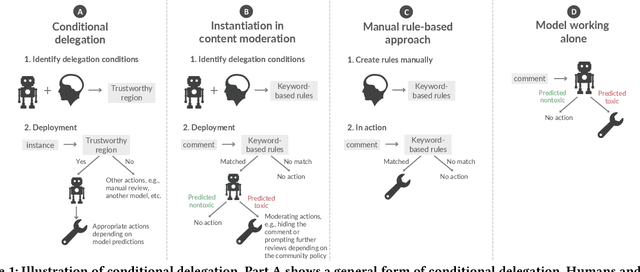

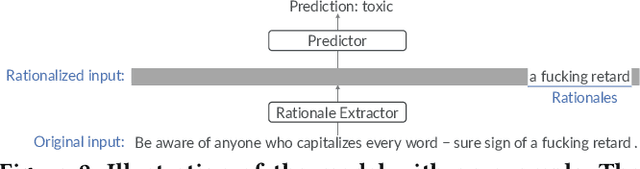
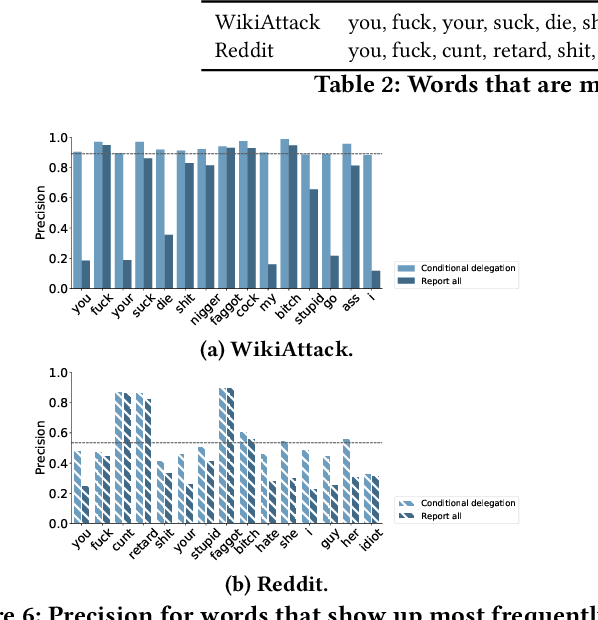
Despite impressive performance in many benchmark datasets, AI models can still make mistakes, especially among out-of-distribution examples. It remains an open question how such imperfect models can be used effectively in collaboration with humans. Prior work has focused on AI assistance that helps people make individual high-stakes decisions, which is not scalable for a large amount of relatively low-stakes decisions, e.g., moderating social media comments. Instead, we propose conditional delegation as an alternative paradigm for human-AI collaboration where humans create rules to indicate trustworthy regions of a model. Using content moderation as a testbed, we develop novel interfaces to assist humans in creating conditional delegation rules and conduct a randomized experiment with two datasets to simulate in-distribution and out-of-distribution scenarios. Our study demonstrates the promise of conditional delegation in improving model performance and provides insights into design for this novel paradigm, including the effect of AI explanations.
What to Learn, and How: Toward Effective Learning from Rationales
Nov 30, 2021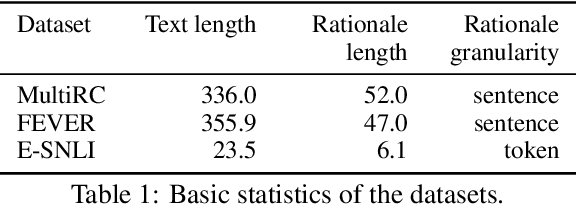
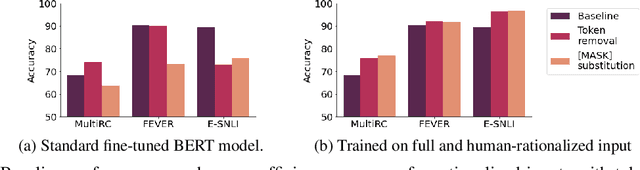
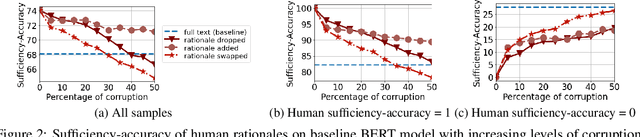
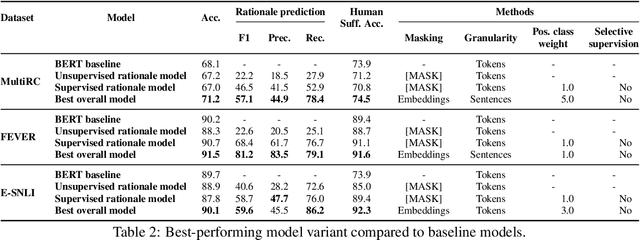
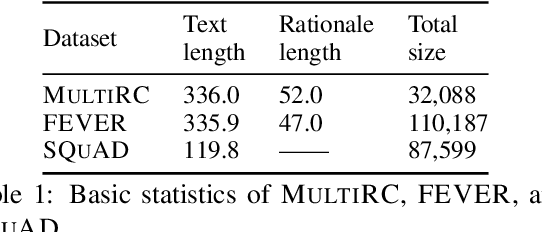
Learning from rationales seeks to augment model training with human-provided rationales (i.e., a subset of input tokens) that justify those labels. While intuitive, this idea has proven elusive in practice. We make two observations about human rationales via empirical analyses: 1) maximizing predicted rationale accuracy is not necessarily the optimal objective for improving model performance; 2) human rationales vary in whether they provide sufficient information for the model to exploit for prediction, and we can use this variance to assess a dataset's potential improvement from learning from rationales. Building on these insights, we propose loss functions and learning strategies, and evaluate their effectiveness on three datasets with human rationales. Our results demonstrate consistent improvements over baselines in both label performance and rationale performance, including a 3% accuracy improvement on MultiRC. Our work highlights the importance of understanding properties of human explanations and exploiting them accordingly in model training.
Evaluating and Characterizing Human Rationales
Oct 09, 2020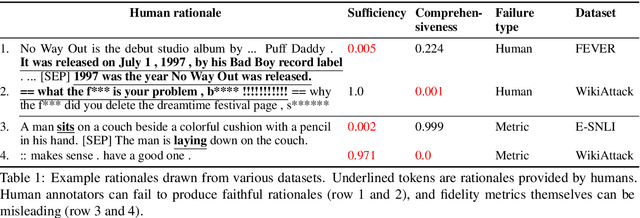
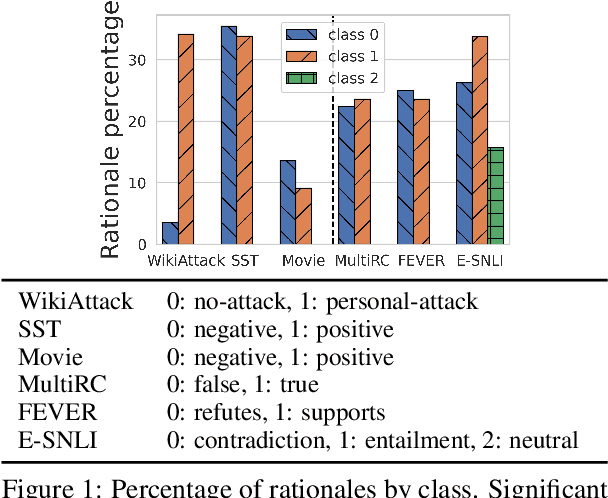
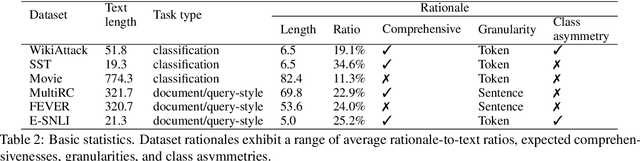
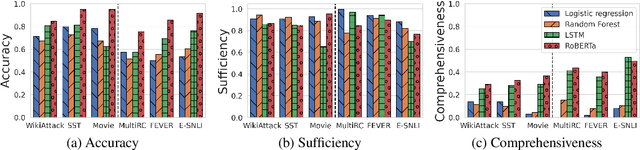
Two main approaches for evaluating the quality of machine-generated rationales are: 1) using human rationales as a gold standard; and 2) automated metrics based on how rationales affect model behavior. An open question, however, is how human rationales fare with these automatic metrics. Analyzing a variety of datasets and models, we find that human rationales do not necessarily perform well on these metrics. To unpack this finding, we propose improved metrics to account for model-dependent baseline performance. We then propose two methods to further characterize rationale quality, one based on model retraining and one on using "fidelity curves" to reveal properties such as irrelevance and redundancy. Our work leads to actionable suggestions for evaluating and characterizing rationales.
An Empirical Study on Explainable Prediction of Text Complexity: Preliminaries for Text Simplification
Jul 31, 2020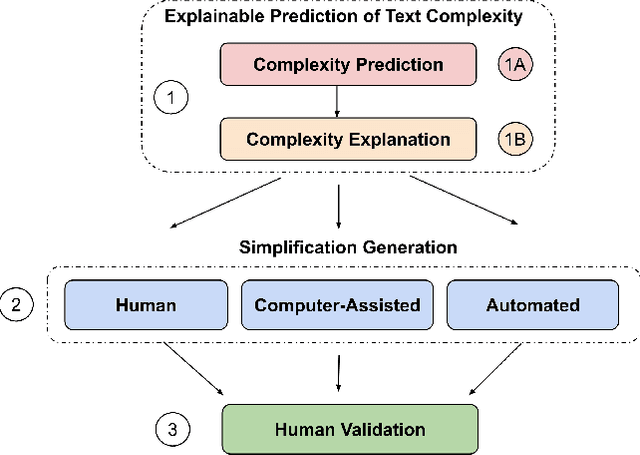

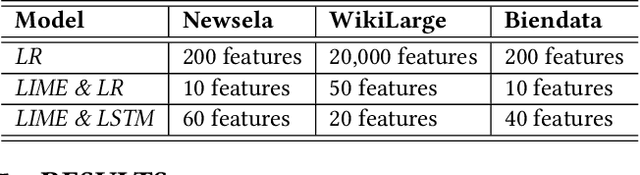
Text simplification is concerned with reducing the language complexity and improving the readability of professional content so that the text is accessible to readers at different ages and educational levels. As a promising practice to improve the fairness and transparency of text information systems, the notion of text simplification has been mixed in existing literature, ranging all the way through assessing the complexity of single words to automatically generating simplified documents. We show that the general problem of text simplification can be formally decomposed into a compact pipeline of tasks to ensure the transparency and explanability of the process. In this paper, we present a systematic analysis of the first two steps in this pipeline: 1) predicting the complexity of a given piece of text, and 2) identifying complex components from the text considered to be complex. We show that these two tasks can be solved separately, using either lexical approaches or the state-of-the-art deep learning methods, or they can be solved jointly through an end-to-end, explainable machine learning predictor. We propose formal evaluation metrics for both tasks, through which we are able to compare the performance of the candidate approaches using multiple datasets from a diversity of domains.
Harnessing Explanations to Bridge AI and Humans
Mar 16, 2020Machine learning models are increasingly integrated into societally critical applications such as recidivism prediction and medical diagnosis, thanks to their superior predictive power. In these applications, however, full automation is often not desired due to ethical and legal concerns. The research community has thus ventured into developing interpretable methods that explain machine predictions. While these explanations are meant to assist humans in understanding machine predictions and thereby allowing humans to make better decisions, this hypothesis is not supported in many recent studies. To improve human decision-making with AI assistance, we propose future directions for closing the gap between the efficacy of explanations and improvement in human performance.
Judge the Judges: A Large-Scale Evaluation Study of Neural Language Models for Online Review Generation
Jan 02, 2019
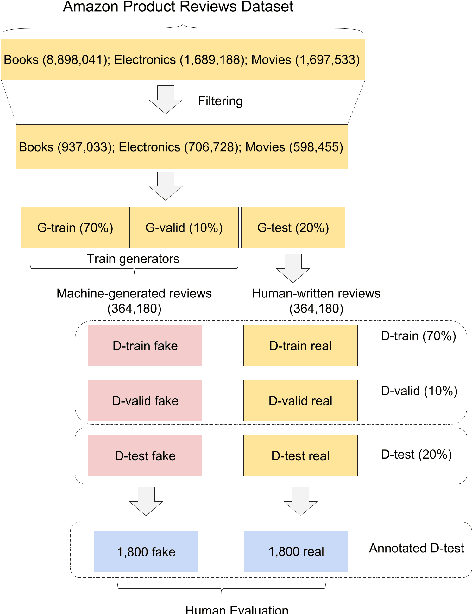
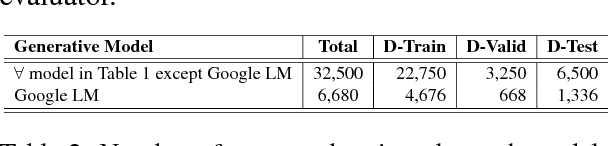
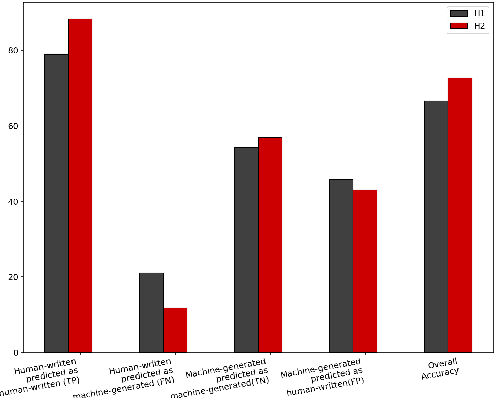
Recent advances in deep learning have resulted in a resurgence in the popularity of natural language generation (NLG). Many deep learning based models, including recurrent neural networks and generative adversarial networks, have been proposed and applied to generating various types of text. Despite the fast development of methods, how to better evaluate the quality of these natural language generators remains a significant challenge. We conduct an in-depth empirical study to evaluate the existing evaluation methods for natural language generation. We compare human-based evaluators with a variety of automated evaluation procedures, including discriminative evaluators that measure how well the generated text can be distinguished from human-written text, as well as text overlap metrics that measure how similar the generated text is to human-written references. We measure to what extent these different evaluators agree on the ranking of a dozen of state-of-the-art generators for online product reviews. We find that human evaluators do not correlate well with discriminative evaluators, leaving a bigger question of whether adversarial accuracy is the correct objective for natural language generation. In general, distinguishing machine-generated text is a challenging task even for human evaluators, and their decisions tend to correlate better with text overlap metrics. We also find that diversity is an intriguing metric that is indicative of the assessments of different evaluators.