 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy is "Chicago" Predictive of Deceptive Reviews? Using LLMs to Discover Language Phenomena from Lexical Cues
Nov 17, 2025Deceptive reviews mislead consumers, harm businesses, and undermine trust in online marketplaces. Machine learning classifiers can learn from large amounts of training examples to effectively distinguish deceptive reviews from genuine ones. However, the distinguishing features learned by these classifiers are often subtle, fragmented, and difficult for humans to interpret. In this work, we explore using large language models (LLMs) to translate machine-learned lexical cues into human-understandable language phenomena that can differentiate deceptive reviews from genuine ones. We show that language phenomena obtained in this manner are empirically grounded in data, generalizable across similar domains, and more predictive than phenomena either in LLMs' prior knowledge or obtained through in-context learning. These language phenomena have the potential to aid people in critically assessing the credibility of online reviews in environments where deception detection classifiers are unavailable.
Risks and Opportunities in Human-Machine Teaming in Operationalizing Machine Learning Target Variables
Oct 29, 2025Predictive modeling has the potential to enhance human decision-making. However, many predictive models fail in practice due to problematic problem formulation in cases where the prediction target is an abstract concept or construct and practitioners need to define an appropriate target variable as a proxy to operationalize the construct of interest. The choice of an appropriate proxy target variable is rarely self-evident in practice, requiring both domain knowledge and iterative data modeling. This process is inherently collaborative, involving both domain experts and data scientists. In this work, we explore how human-machine teaming can support this process by accelerating iterations while preserving human judgment. We study the impact of two human-machine teaming strategies on proxy construction: 1) relevance-first: humans leading the process by selecting relevant proxies, and 2) performance-first: machines leading the process by recommending proxies based on predictive performance. Based on a controlled user study of a proxy construction task (N = 20), we show that the performance-first strategy facilitated faster iterations and decision-making, but also biased users towards well-performing proxies that are misaligned with the application goal. Our study highlights the opportunities and risks of human-machine teaming in operationalizing machine learning target variables, yielding insights for future research to explore the opportunities and mitigate the risks.
How Does Imperfect Automatic Indexing Affect Semantic Search Performance?
Apr 08, 2023Documents in the health domain are often annotated with semantic concepts (i.e., terms) from controlled vocabularies. As the volume of these documents gets large, the annotation work is increasingly done by algorithms. Compared to humans, automatic indexing algorithms are imperfect and may assign wrong terms to documents, which affect subsequent search tasks where queries contain these terms. In this work, we aim to understand the performance impact of using imperfectly assigned terms in Boolean semantic searches. We used MeSH terms and biomedical literature search as a case study. We implemented multiple automatic indexing algorithms on real-world Boolean queries that consist of MeSH terms, and found that (1) probabilistic logic can handle inaccurately assigned terms better than traditional Boolean logic, (2) query-level performance is mostly limited by lowest-performing terms in a query, and (3) mixing a small amount of human indexing with automatic indexing can regain excellent query-level performance. These findings provide important implications for future work on automatic indexing.
GRAFS: Graphical Faceted Search System to Support Conceptual Understanding in Exploratory Search
Feb 19, 2023When people search for information about a new topic within large document collections, they implicitly construct a mental model of the unfamiliar information space to represent what they currently know and guide their exploration into the unknown. Building this mental model can be challenging as it requires not only finding relevant documents, but also synthesizing important concepts and the relationships that connect those concepts both within and across documents. This paper describes a novel interactive approach designed to help users construct a mental model of an unfamiliar information space during exploratory search. We propose a new semantic search system to organize and visualize important concepts and their relations for a set of search results. A user study ($n=20$) was conducted to compare the proposed approach against a baseline faceted search system on exploratory literature search tasks. Experimental results show that the proposed approach is more effective in helping users recognize relationships between key concepts, leading to a more sophisticated understanding of the search topic while maintaining similar functionality and usability as a faceted search system.
An Empirical Study on Explainable Prediction of Text Complexity: Preliminaries for Text Simplification
Jul 31, 2020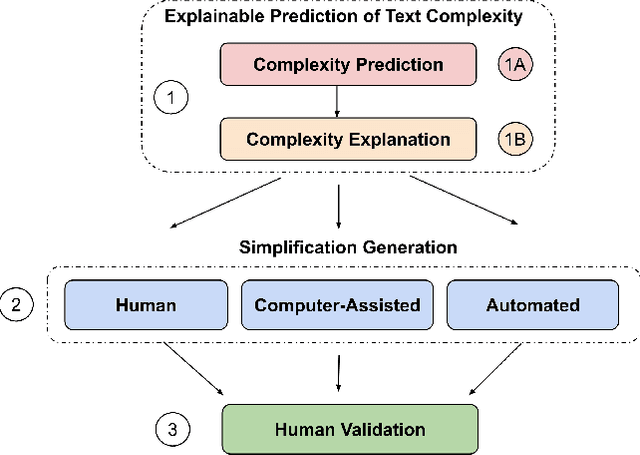
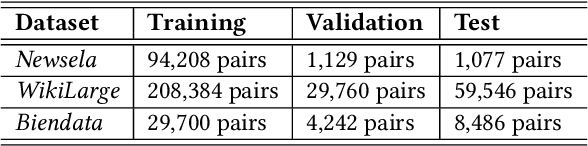

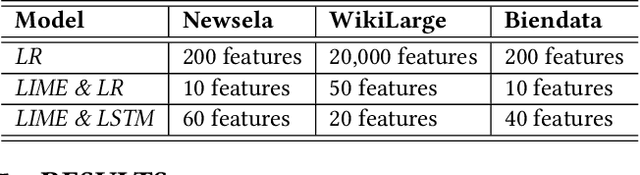
Text simplification is concerned with reducing the language complexity and improving the readability of professional content so that the text is accessible to readers at different ages and educational levels. As a promising practice to improve the fairness and transparency of text information systems, the notion of text simplification has been mixed in existing literature, ranging all the way through assessing the complexity of single words to automatically generating simplified documents. We show that the general problem of text simplification can be formally decomposed into a compact pipeline of tasks to ensure the transparency and explanability of the process. In this paper, we present a systematic analysis of the first two steps in this pipeline: 1) predicting the complexity of a given piece of text, and 2) identifying complex components from the text considered to be complex. We show that these two tasks can be solved separately, using either lexical approaches or the state-of-the-art deep learning methods, or they can be solved jointly through an end-to-end, explainable machine learning predictor. We propose formal evaluation metrics for both tasks, through which we are able to compare the performance of the candidate approaches using multiple datasets from a diversity of domains.